版权声明:本文为博主原创文章,转载请注明出处:http://blog.csdn.net/shine19930820 https://blog.csdn.net/shine19930820/article/details/84037579
Building a Conversational Agent Overnight with Dialogue Self-Play
Google提出了 Machines Talking To Machines(M2M,机器对话机器)的框架,这是一个功能导向的流程,用于训练对话智能体。其主要目标是通过自动化任务无关的步骤以减少建立对话数据集所需的代价,从而对话开发者只需要提供对话的任务特定的层面。另一个目标是获得更高质量的对话,「高质量」指的是:(1)语言和对话流的多样性,(2)所有预期用户行为的覆盖范围;以及(3)监督标签的准确性。最后,这个框架的目标是引导对话智能体,使其被部署去服务实际的用户,并达到可接受的任务完成率,之后,该框架应该能使用强化学习通过用户反馈直接提升自身性能。
1. Wizard-of-Oz
首先讲一下Wizard-of-Oz如何通过众包工作者产生task oriented多轮对话。
1.1 user
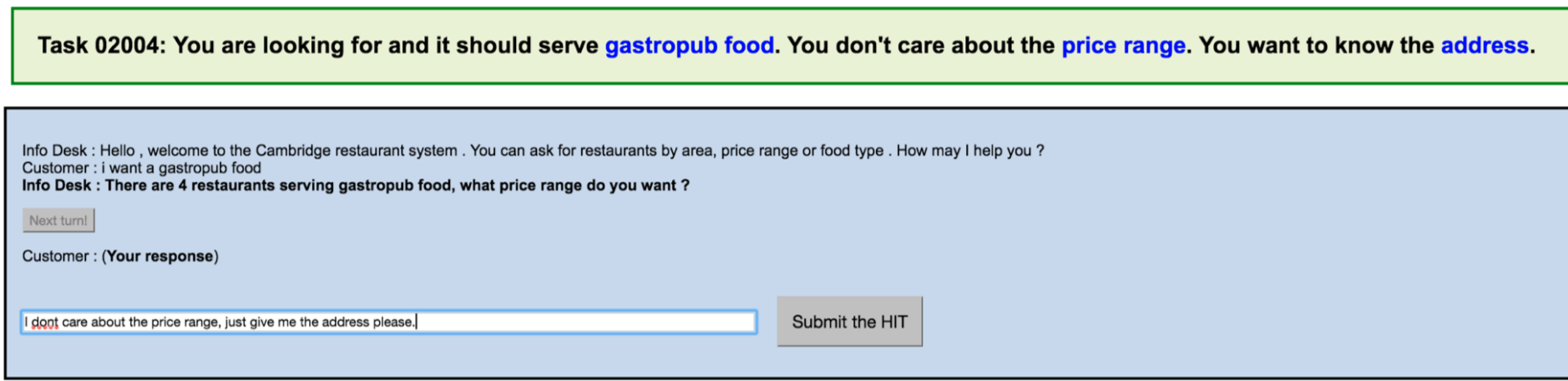
user: 给出实体(infrom, request),查看历史对话和任务描述,给出适当的回应句子。
1.2 wizard
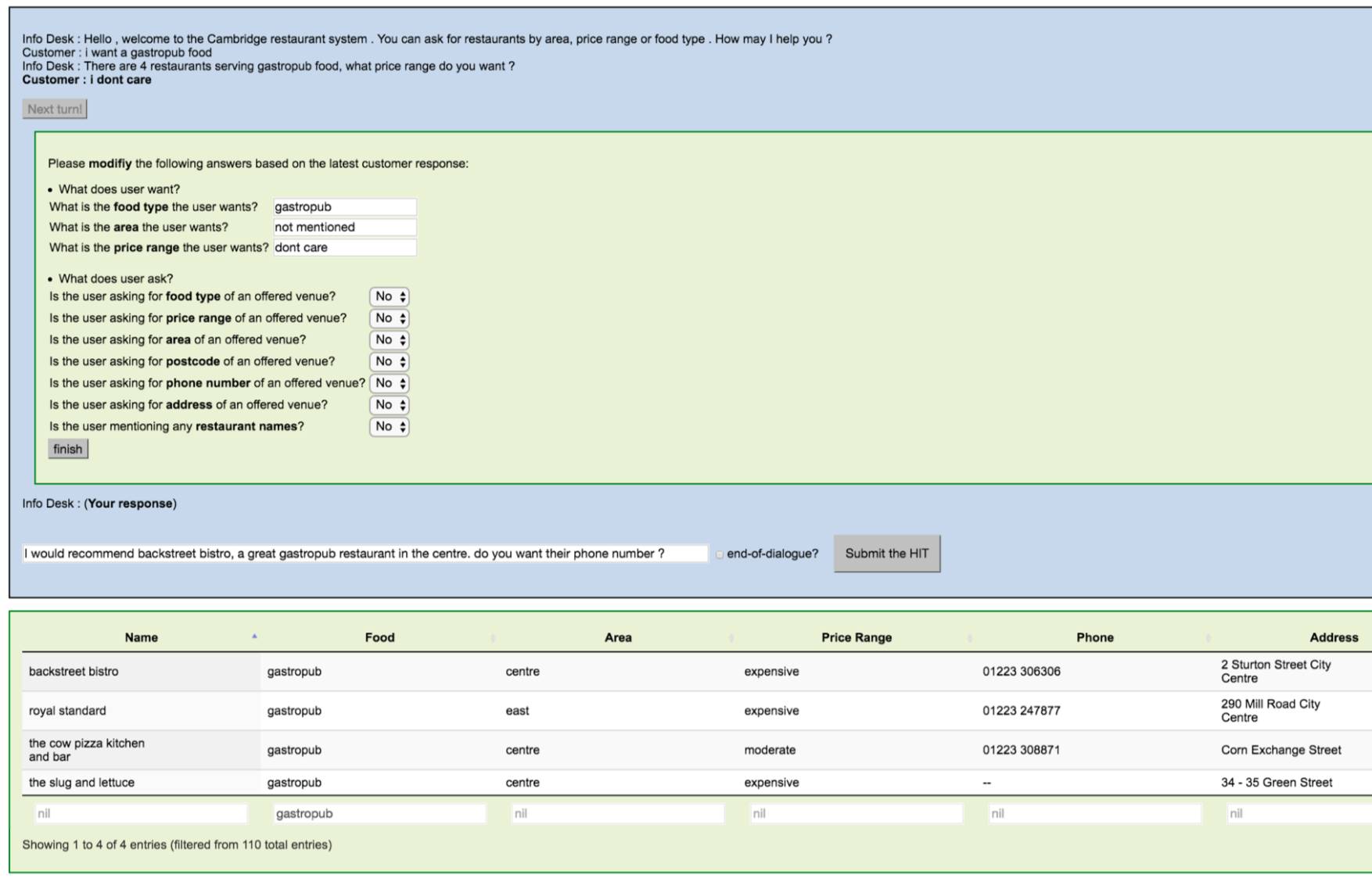
给出一个表格,众包工作人员需要浏览对话历史记录。
- 通过在本回合解释用户输入填写表单(顶部绿色),并根据历史记录和数据库结果键入适当的响应( 底部绿色)。 提交表单时更新数据库搜索结果。 表单可以分为infrom slot和可request slot,包含state tracker所需的所有标签。
- 还需要输出回应
1.3 优缺点
其优势在于:
每个人按轮次来标注,需要查看历史对话记录。使得数据的采集可以并行,减少标注者等待时间。
主要缺点:
- 可能不会涵盖所有的交互。(人主导)
- 可能包含不适合用作培训数据的对话(例如,如果群众工作者使用过于简单化或过于复杂的语言)
- 对话注释中可能有错误,需要开发人员过滤和清洗。
论文:
- A Network-based End-to-End Trainable Task-oriented Dialogue System
- Frames: a corpus for adding memory to goal-oriented dialogue systems
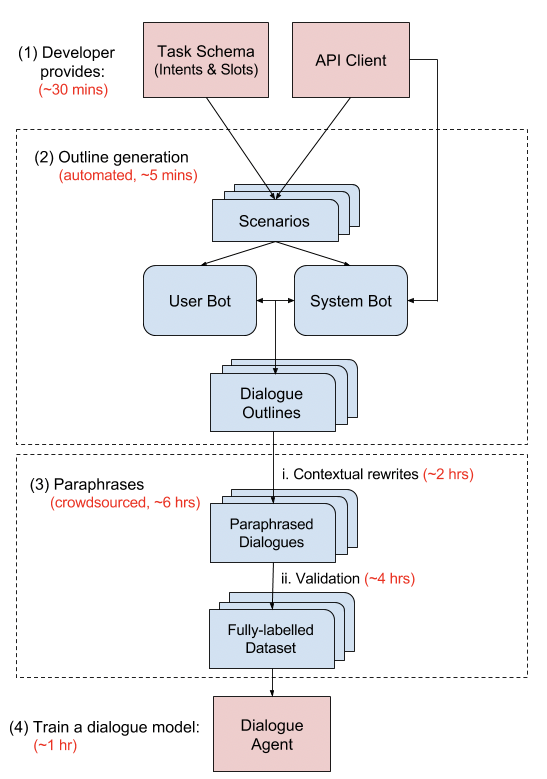
2. M2M框架
自动化任务无关的步骤以减少建立对话数据集所需的代价。
- 对话开发者提供任务Schema(intents&Slots)和API客户端,
- 自动机器人(User Bot&System bot)生成对话轮廓Outlines,(一个agenda based用户模拟器和一个基于有限状态机器的system agent)
- 众包重写成自然语言表达并验证slot span。
- 在数据集上用监督学习训练对话模型。
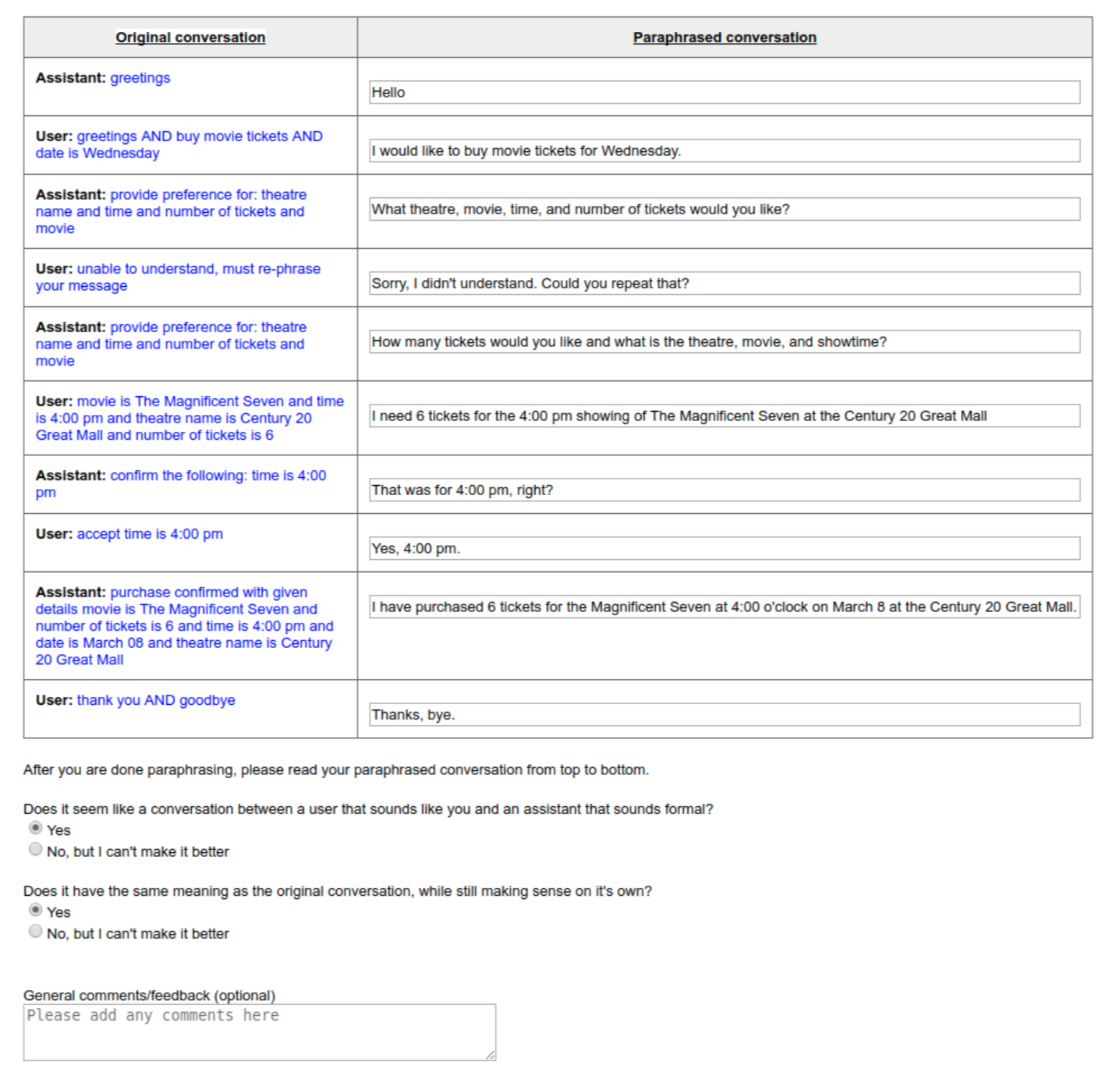
生成大纲与段落的示例。
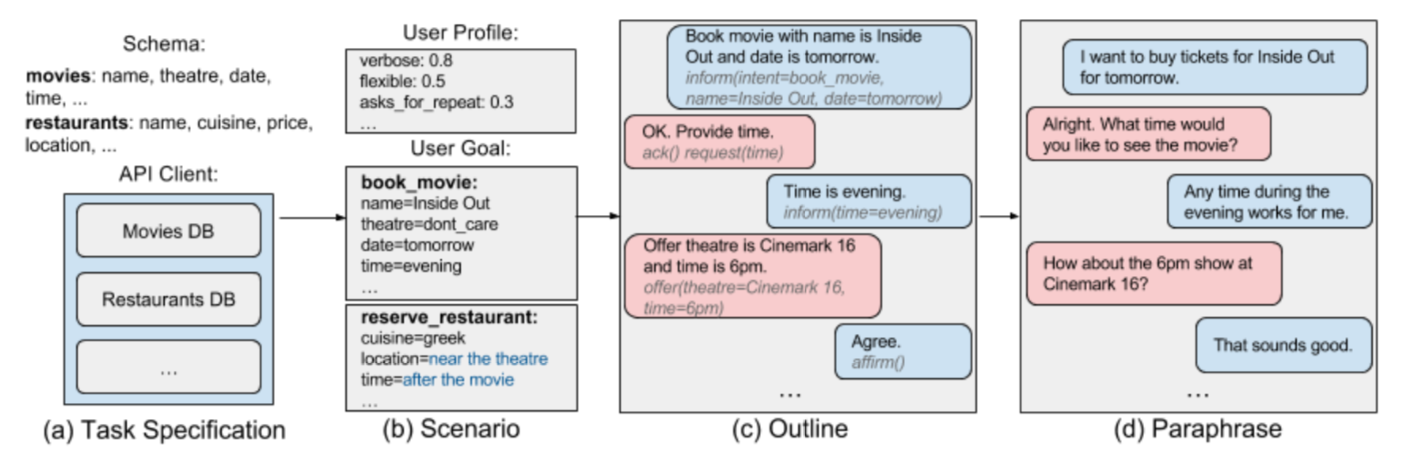
用户根据M2M生成的outline,来生成真正的对话。
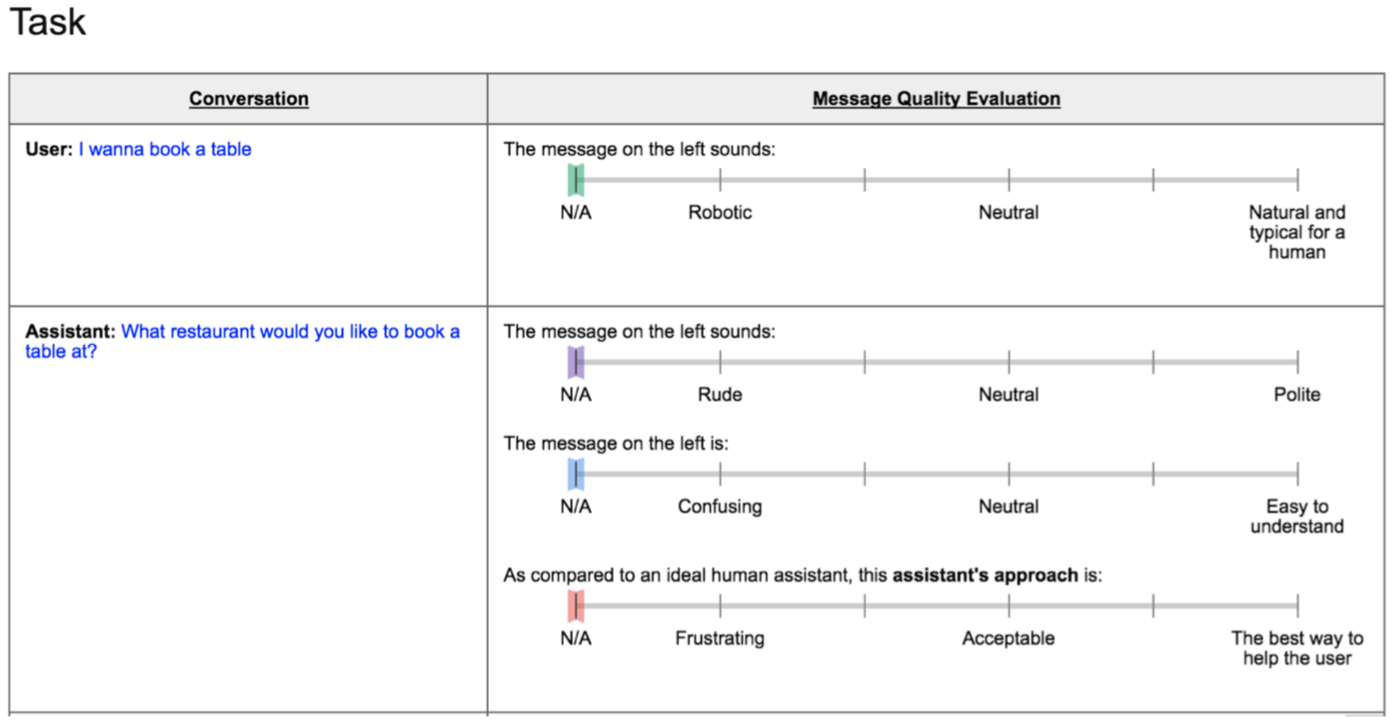
用户评价对话界面。

2.1 优势:
- Function driven,开发者提供Schema和API,不需要很精细设计(精力,周全)。
- 对话流多样(bot的设计)。
- 覆盖预期的用户行为。
- 标签的正确性。
在达到一定任务完成率,部署上线使用强化学习直接从用户反馈中改进它们。
2.2 评价:
DSTC2 与 M2M Restaurant 数据集在语言与对话流多样性的对比
| Metric | DSTC2 (Train) | M2M Rest. (Train) |
|---|---|---|
| Dialogues | 1611 | 1116 |
| Total turns | 11670 | 6188 |
| Total tokens | 199295 | 99932 |
| Avg. turns per dialogue | 14.49 | 11.09 |
| Avg. tokens per turn | 8.54 | 8.07 |
| Unique tokens / Total tokens | 0.0049 | 0.0092 |
| Unique bigrams / Total tokens | 0.0177 | 0.0670 |
| Unique transitions / Total turns | 0.0982 | 0.2646 |
| Unique subdialogues(k=3) / Total subdialogues(n=3) | 0.1831 | 0.3145 |
| Unique subdialogues(k=5) / Total subdialogues(n=5) | 0.5621 | 0.7061 |
| Unique full outlines / Total dialogues | 0.9243 | 0.9292 |

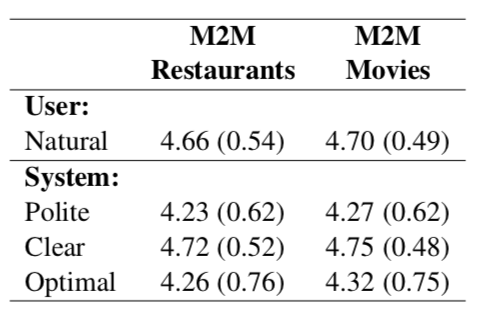
用 M2M 收集的对话的人类评价。众包人员对用户与系统对话给出得分的平均值(1-5 分), 括号内是标准偏差。
可能会遇到的问题
- Schema怎么设计,API如何接入,都是需要更具业务定制的解决方案。
- user bot采用rule-based,system bot机制?有限自动机?其实也是另一种rule-based,局限性?
- 众包的具体细节其实可以参考WOZ,是否能结合两者的优势。
- 数据集监督学习训练对话模型,后采用强化学习来优化模型。