从本篇开始将是 deeplearning.ai的第三门课程,构如何构建机器学习项目以及需要注意的点
Introduction to ML Strategy
Why ML Strategy
为什么要使用所谓ML Strategy,比如我们现在要设计一个图像分类器,我们已经得到了90%的accuracy,那么接下来我们要如何再去提高它的accuracy呢,如下,我们有非常非常多的方向和方法,但是哪个方法方向是最有效的,我们并不知道,所以需要ML Strategy来帮我们进行选择。

Orthogonalization
orthogonalization字面上理解就是正交化,在向量空间中呢,正交化即表示不相关,我的变化不会影响到你,你的变化不会影响到我。在ML Strategy中,orthogonalization表示,我们希望我们实施的策略具有针对性,比如在减小bias的同时,不希望variance有变化,这样有助于我们针对问题进行逐步调节,不会互相影响导致最后所有东西都在变化。
如下图,在ML项目中,我们首先希望模型能够很好的fit我们的训练集,然后希望能够很好的fit我们的dev set,再然后希望它能够fit我们的测试集,最后在现实中能够很好地运行。orthogonalization保证我们在已经调整模型使其可以很好fit我们训练集地情况下,我们在调dev set的时候,不会影响到我们的train accuracy。这样我们才能一步步往下走。而early stopping就不是一种满足orthogonalization的策略,因为它在减小dev error的时候同时增大了我们的bias,使train error增大。

那么针对fit training set,我们可以尝试更复杂的网络,使用更复杂的优化算法等。
针对fit dev set,我们可以运用regularization,增大我们的training set等。
针对fit test set,我们可以增大 dev set来防止模型对dev set 过拟合。
最后如果fit test set well,但不能在现实中很好的运用,我们就需要改变我们的dev set,因为现实数据与dev set分布不同或者改变我们的cost function,说明我们所最小化的东西不对。
Setting up your goal
Single number evaluation metric
对于这个问题,机器学习笔记有所讲述,即运用单一的数值来衡量我们模型的好坏会有助于我们推进我们模型的改进。比如我们运用分类的accuracy来衡量,或者运用综合了precision和recall的F1-score来衡量等。
Satisficing and Optimizing metric
有些时候我们很难将所有的因素结合成为一个single metric,如下,我们要同时考虑accuracy和running time。那么这个时候,我们可以将两个参数一个设定为Optimizing metric,即需要我们优化的参数,另一个设定为Satisficing metric,即需要满足的参数。那么我们satisficing metric设为需要小于100ms,即在满足running time小于100ms的条件下,accuracy最大的为最优。当然如果我们有N个因素,我们就需要将其中一个选为Optimizing metric,剩下的N-1全部为satisficing metric。

Train/dev/test distributions
这里再次强调dev set的作用,我们设计了很多模型并且使用trainning set去训练这些模型,然后需要通过dev set来对所有的模型测试,选出一个效果最好的,最后再使用test set进行测试。
对于数据集的分布,我们希望dev/test 这两部分的数据集要来自同一分布,只有这样dev set测试出来的效果好的模型,才有可能在test set上取得很好的结果,那么这就要求dev/test set要满足下面这个guideline。有了这个guideline才能保证我们的模型在fit dev/test set的情况下,有可能在现实中取得好的效果。

Size of the dev and test sets
对于数据集划分,即不再单纯按照60/20/20划分,而是根据已有的数据量大小进行划分,dev和test sets希望满足以下要求。至于这个要求也是要根据已有数据量的大小来决定,比如现在百万级,千万级的数据,1%即可。也有一种情况没有test set,只有dev set,但是这种情况不推荐,这就需要采用较大的dev set以保证,训练的模型不会对dev set过拟合。

When to change dev/test sets and metrics
有时候我们并不能一开始就预见我们选取的dev set和metrics是否能够帮助训练一个能够非常好的运用到实际当中的模型,所以在项目进行过程中,有时候我们需要改变我们的dev/test sets或者改变我们的metrics。
第一个例子:图像二分类问题(是否是猫)
我们现在有两个算法,一个error 3%,一个error 5%。当然从error的角度,我们选择算法A,但是算法A会错误地将很多淫秽图片判定为猫,这是我们作为用户来说不希望看到的。那么这个时候说明如果将算法A放到实际中,那么效果不好,于是我们需要改变我们的error。

第二个例子:一样的问题
我们用于dev/test是非常清晰的图片,而用户上传的图片是非常blurry的,那么这个时候我们的分类器放到实际中效果并不好,于是我们需要改变我们的dev set。

这里同样体现了orthogonalization,第一步我们定义metric去评定我们的模型,第二步我们需要如何改变metric使它能够work well。
Comparing to human-level performance
Why human-level performance
因为近年深度学习的飞速发展,深度学习在许多领域都取得了重大突破,接近甚至赶超了人类在这些领域所能达到的accuracy。那么了解human-level performance能够帮助我们进一步提高我们的正确率,这里提出一个叫做bayes optimal error,表示最优的误差,无论如何都无法超过的误差,即有些图片太模糊,无法识别,有些音频太嘈杂,无法判断等。那么human-level performance和bayes optimal error之间还有一段间隔。
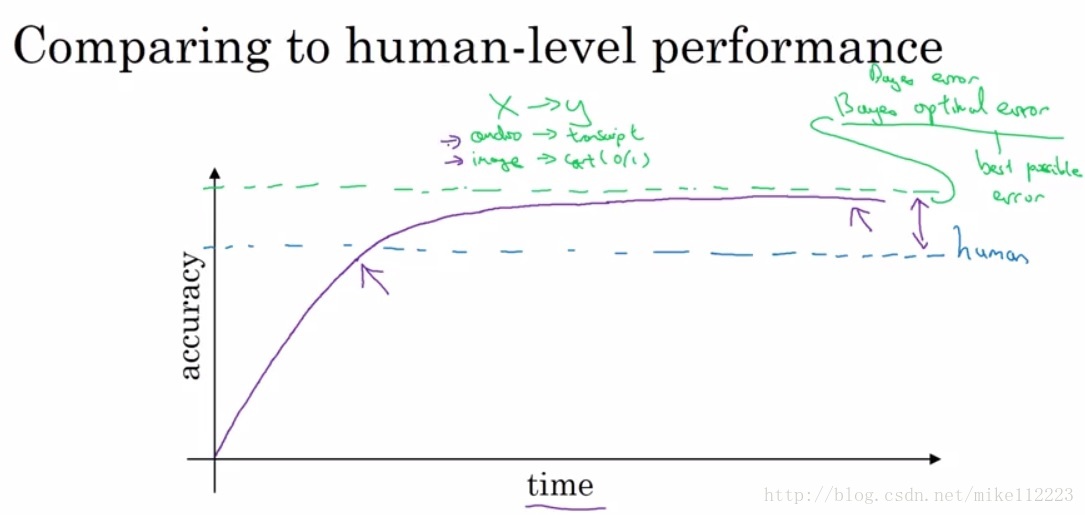
从上图中,我们可以看出在accuracy低于human-level的时候,accuracy增长的很快,而超过human-level之后就会上升的很慢,这个原因是什么呢。因为在低于human-level的时候,我们可以:
1. Get labeled data from humans
2. Gain insight from manual error analysis: Why did a person get this right?
3. Better analysis of bias/variance
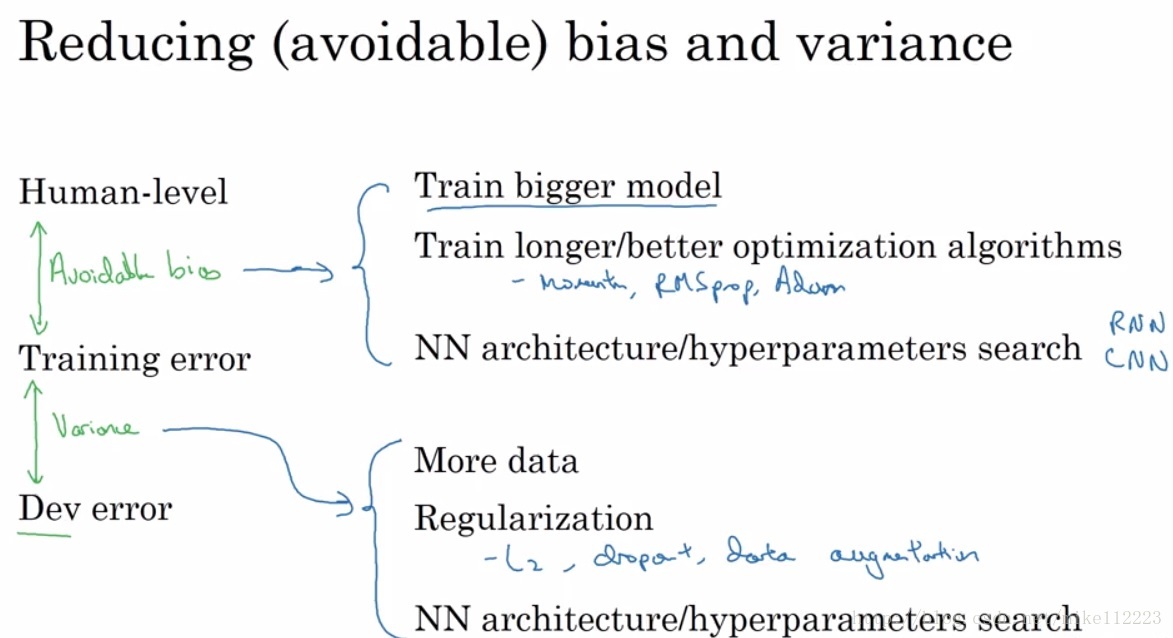
那么我们为什么需要human-level performance呢,这是为了更好的判断我们的模型所存在的问题,到底是bias的问题大,还是variance的问题大,这样决定我们先着手解决哪个问题。我们知道variance是根据train/dev error之间的差距来决定的,可是bias的话,我们不能单纯使用train error和0来决定,于是我们引入human-level error,取train error 和human-level做差和train/dev error进行比较,谁大决定先解决谁。由于这里的bias不再是train error 与 0 的差,于是我们将其定义为”avoidable bias”。即通过优化这个误差是可以消除的。

Understanding human-level performance
Human-level error没有一个很固定的值,如下图,都可以作为human-level error,这一般是根据我们的目的来决定的。如果我们要发表一篇论文,那么我们决定使用Typical doctor,因为如果我们的error小于Typical doctor,我们有理由相信它是一个好的成果。如果我们想要以Bayes error作为上限,那么我们使用Team of experienced doctors。因为我们知道Bayes optimal error是一定小于任何human-level的,但是我们又不会知道确切值,所以我们使用最小的human-level来近似Bayes optimal error。

Surpassing human-level performance
如下图左,当我们的train error 没有超过我们的human-level error的时候,我们对human-level/train error做差与train/dev error做差进行比较,来确定我们下一步干嘛。如下图,0.2大于0.1,所以我们要降低variance。
下图右,如果我们的training error 已经高于human-level error,这个时候呢,我们优化的方法和方向将不明确,但这并不意味着没有办法再make progress了。因为我们不知道真正的bayes optimal error是多少,理论上我们是可以接近这个值的。

Improving your model performance
接下来进行总结,对于有监督学习来说,有两个基本的假设:
1. 我们可以非常好地拟合我们的training set,即我们可以基本消除avoidable bias。
2. 训练出的模型能够很好的泛化到我们的dev/test set上,即variance也可以很小。
小广告
淘宝choker、耳饰小店 物理禁止
女程序员编码时和编码之余 都需要一些美美的choker、耳饰来装扮自己
男程序员更是需要常备一些来送给自己心仪的人
淘宝小店开店不易 希望有缘人多多支持 (O ^ ~ ^ O)
本号是本人 只是发则小广告 没有被盗 会持续更新深度学习相关博文和一些翻译
感谢大家 不要拉黑我 ⊙﹏⊙|||°