-
什么是爬虫?
爬虫就是从网上获得数据,它是通过编程来实现的。对于非计算机专业的人来说,一提到编程两个字,可能就会觉得自己做不到。但其实并不是这样,编程就是通过写代码,来让计算机实现你的想法。你解决问题的想法,就会影响你编程时写的代码。对于爬虫这件事情,就是从网上获取数据,那么相对应的代码就不会有太大的变化。比如你爬取58同城的求职和爬猫眼电影的电影数据的代码并不会有太大的差别。我写过的每个关于爬虫的代码,基本60%以上的部分是一样的。
-
爬虫的思路
爬虫的目的是从网上获取对你有需要的数据,那么目的确定,思路就能确定。思路确定,代码就能确定。
爬虫的思路就是:
1、获取url(网址)。2、发出请求,获得响应。3、提取数据。4、保存数据。
下面逐个解释。
1.获取url(网址):
url是统一资源定位符,对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。就是我们平时所说的网址。
浏览器就是通过网址向服务器发送请求,来获取信息的。浏览器和服务器的关系如下图所示:
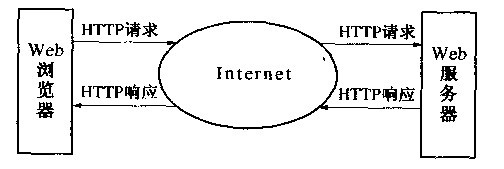
浏览器向服务器发出请求,服务器给浏览器响应。一个浏览器可以访问很多个服务器,访问具体哪个服务器是根据浏览器中输入的url,比如www.baidu.com。就是访问百度的服务器。
有时url可以直接复制就可以了,但有时如果想要获取的数据在许多网页,比如我想获得前20页的租房数据,那么一个一个复制网址太麻烦,可以通过找到规律,然后构造出来所有的url。
还有时url特别长,你可以适当的去掉里面的字符串,比如淘宝网搜索口红之后的url是’https://s.taobao.com/search?q=口红&imgfile=&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm=a21bo.2017.201856-taobao-item.1&ie=utf8&initiative_id=tbindexz_20170306’。
你可以将它改成’https://s.taobao.com/search?q=口红’,效果是一样的。
2.发送请求,获得响应
服务器里有大量的信息,浏览器是没有信息的,它只负责发送请求和得到响应。比如我想获得一些电影的数据,那我就先得到我需要数据所在的url,比如’https://movie.douban.com/’,然后通过浏览器向豆瓣的服务器发送请求,获得响应的响应。但是我们写爬虫并不是通过浏览器获得数据,而是通过python写的爬虫代码来获得数据。但是如果服务器识别出了发送给它的请求时爬虫发出的,那么服务器就会停止返回数据。这就需要写一些代码将我们写的爬虫包装成浏览器,向服务器发送请求,并获得响应。响应就是该网页的源代码,可以在网页中右击选择网页源代码看到。
3.提取数据。
提取数据就是在第二步中,我获得了服务器给我的响应,但这些响应大多数不是我想要的,我只需要其中的一部分,比如说服务器给我返回了如下所示的信息

但这些信息看起来眼花缭乱,我只想要下图所示的信息

或者如下图所示看起来更整齐的数据
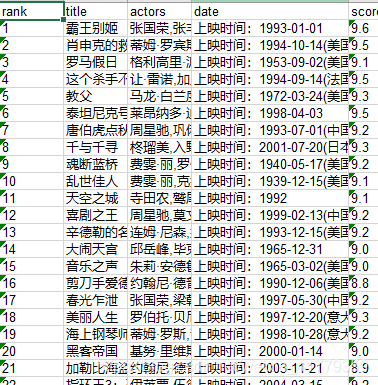
这样的信息少而整齐,方便存储,这就是数据的提取。就像一层过滤网一样,将没用的东西过滤掉,将有用的东西留下来。数据提取的方法有许多,比如正则表达式,还有beautifusoup库。正则表达式是比较常用的方法,它是根据网页的源代码来提取数据的,不需要考虑网页的结构。
4.数据的保存
数据的保存就是将第三步提取的信息保存到Excel或数据库中,方便下次使用时查看和分析。数据保存这一步需要写的代码几乎是固定不变的,没什么技术含量,也不需要刻意去记,每次使用复制粘贴就可以。代码如下图所示:
#数据保存
f=xlwt.Workbook(encoding='utf-8')
sheet01=f.add_sheet(u'sheet1',cell_overwrite_ok=True)
sheet01.write(0,0,'name') #第一行第一列
sheet01.write(0,1,'score')
sheet01.write(0,2,'price')
sheet01.write(0,3,'recommand_ratio')
sheet01.write(0,4,'people_num')
sheet01.write(0,5,'location')
#写内容
for i in range(len(DATA)):
sheet01.write(i+1,0,DATA[i]['name'])
sheet01.write(i+1,1,DATA[i]['score'])
sheet01.write(i+1,2,DATA[i]['price'])
sheet01.write(i+1,3,DATA[i]['recommend_ratio'])
sheet01.write(i+1,4,DATA[i]['people_num'])
sheet01.write(i+1,5,DATA[i]['location'])
f.save(u'E:\\猫眼电影.xls')
- 总结
爬虫就四步,1、获得url。2、发送请求,获得响应。3、提取数据。4保存数据。
第二步和第四步过程的代码几乎是不变的,不需要多深的理解,看几个例子就可以记下来了,每次写代码这两个部分可以直接复制。第三步提取数据是每次写爬虫变化最大的地方,也是写爬虫代码最需要时间的和思考的地方,我觉得也是爬虫的核心,需要认真学习和理解。第一步获得url主要就是看翻页之后网址的变化,然后根据变化的规律去把每一页的url构造出来,比如淘宝网搜索关键字口红后每一页的url是:
第一页:‘https://s.taobao.com/search?q=口红s=44’
第二页:‘https://s.taobao.com/search?q=口红s=88’
第三页:‘https://s.taobao.com/search?q=口红s=132’
…
那么够造出所有这些url的代码就是:
比如我们先要前10的url吧
urls=['https://s.taobao.com/search?q=口红s={}'.format(i*44) for i in range(1,11)]
这就是爬虫的整体框架,是不是很简单,那就把它拿下吧。