一、浏览器的工作原理
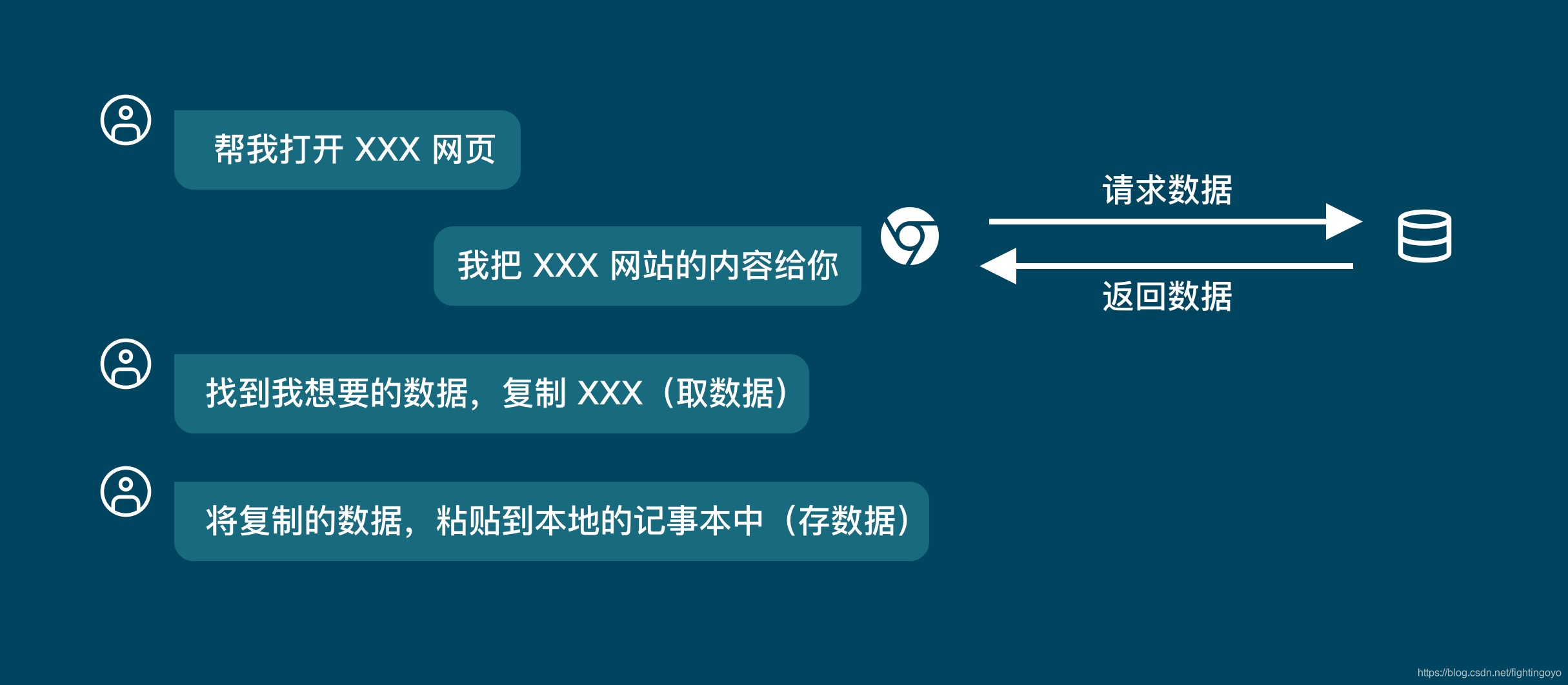
当我们要将网页的信息保存到本地时,通常是打开网页,然后通过复制网页的文本,接着粘贴到本地
从上图中,只有我们和浏览器。但是实际上还有一方,那就是「服务器」。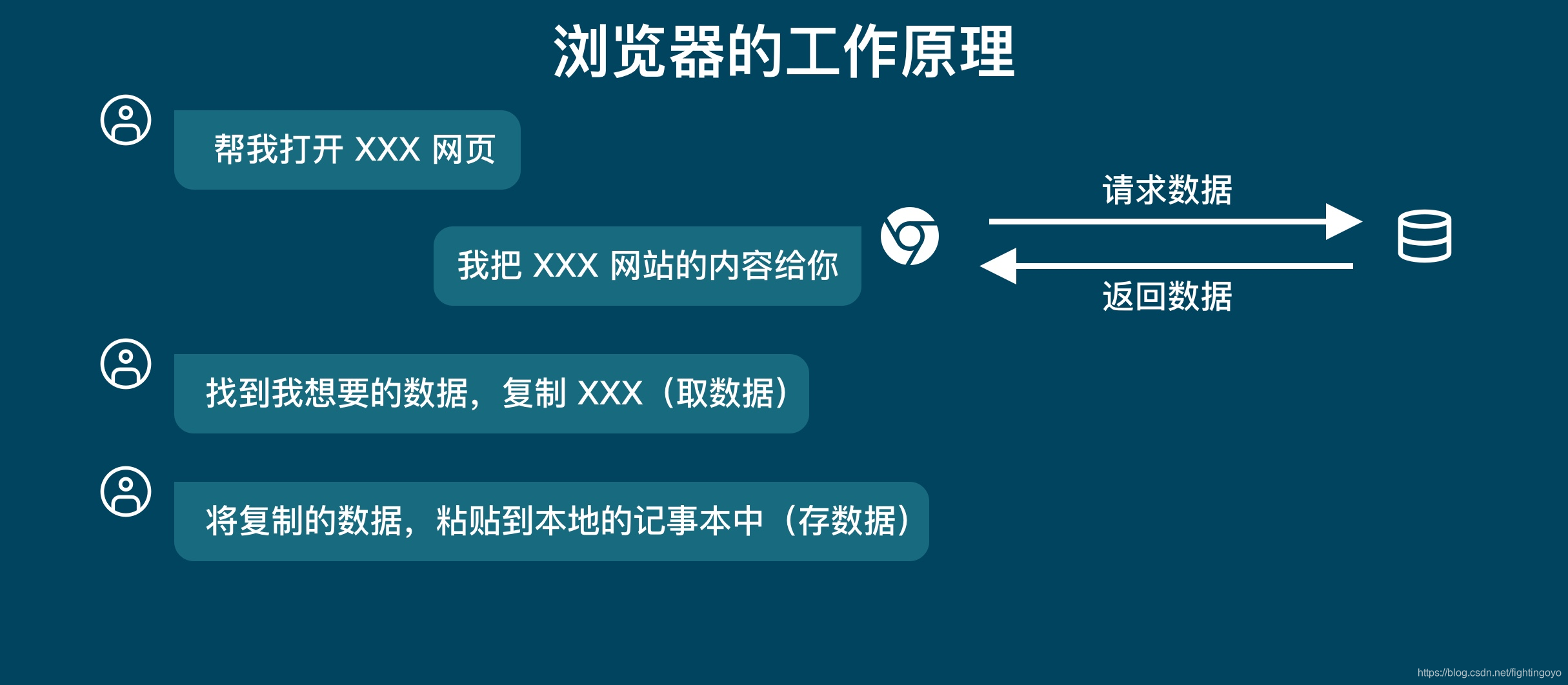
- Request
当我们在浏览器中输入一个网址,也叫做URL(Uniform Resource Locator),然后浏览器就会去存储放着这个网址资源文件的服务器获取这个网址的内容,这个过程就叫做「请求」(Request)。 - Response
当服务器收到了我们的「请求」之后,它会把对应的网站数据返回给浏览器,这个过程叫做「响应」(Response)。
所以当你用浏览器去浏览网页的时候,都是浏览器去向服务器请求数据,服务器返回数据给浏览器的这样一个过程。

当浏览器收到服务器返回的数据时,它会先「解析数据」,把数据变成人能看得懂的网页页面。
当我们浏览这个网页的时候,我们会「筛选数据」,找出我们需要的数据,比如说一篇文章、一份论文等。然后我们把这一篇文章,或者是一篇论文保存到本地,这就叫做「存储数据」。
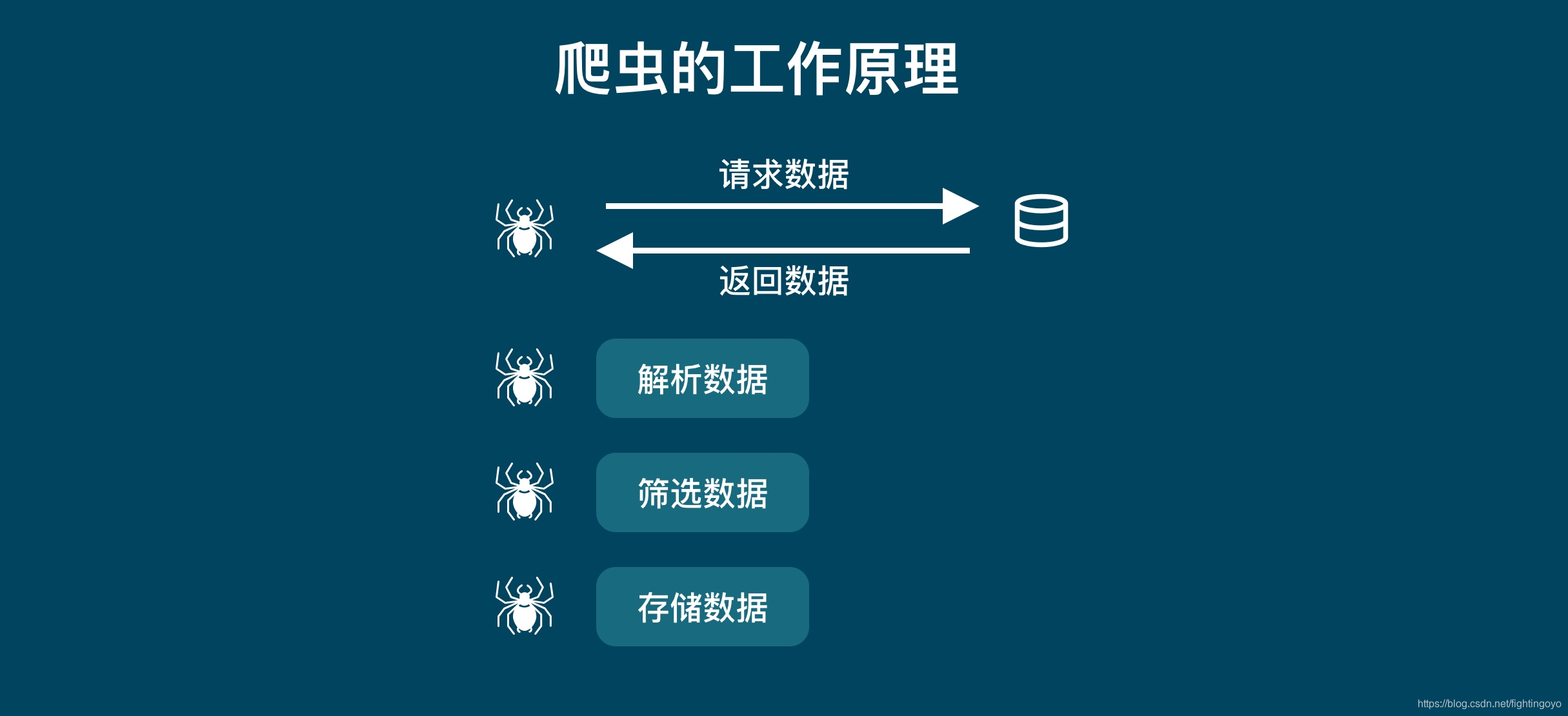
二、爬虫的工作原理
当你要去某个网站批量下载文章,如果单纯的使用浏览器的话,那么你就得打开浏览器,输入网址,页面加载完成后,寻找对应文章,一个一个的去点下载按钮。
如果这个过程使用爬虫来处理,那么爬虫就会代替我们去服务器请求数据,然后爬虫帮我们去解析数据,然后按照我们设定好的规则批量把文章下载下来,存储到特定文件中。
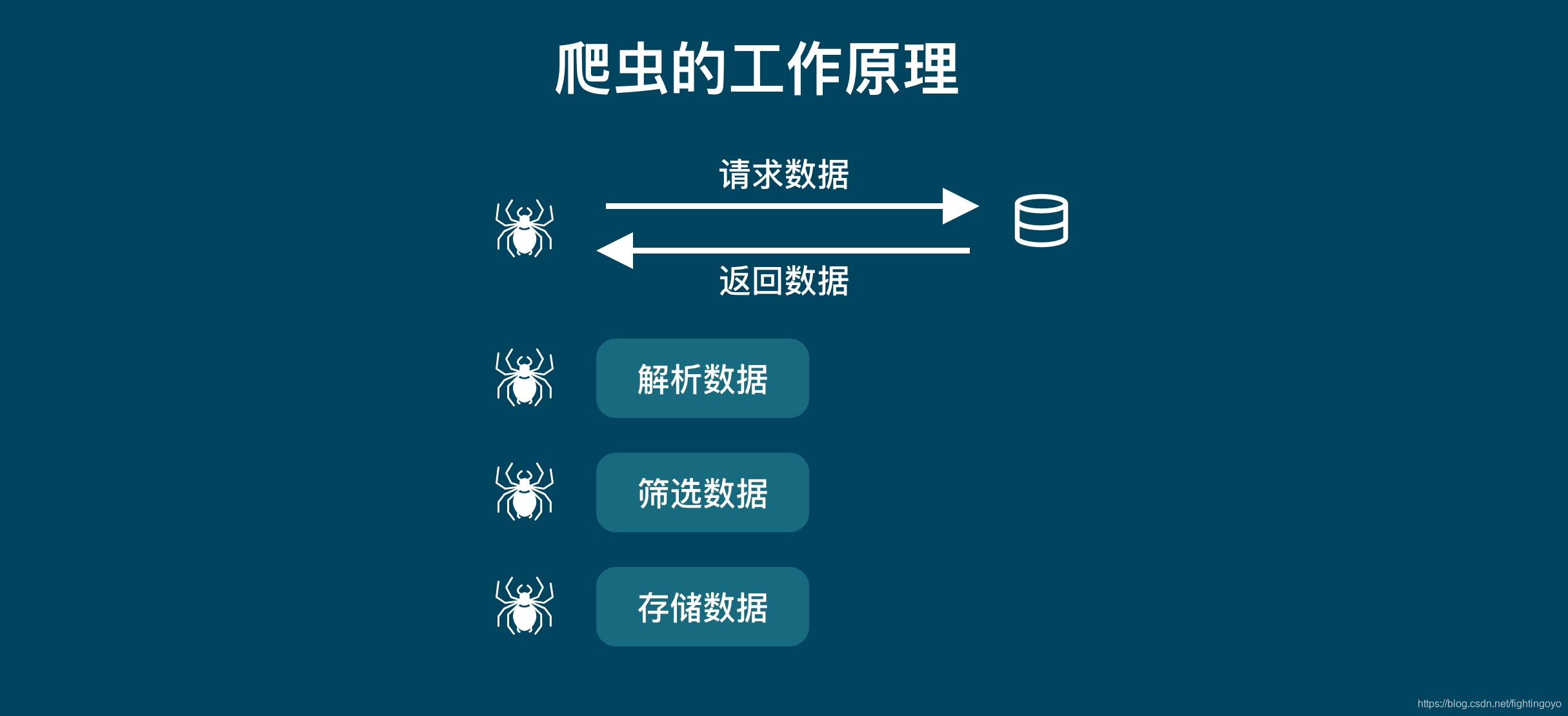
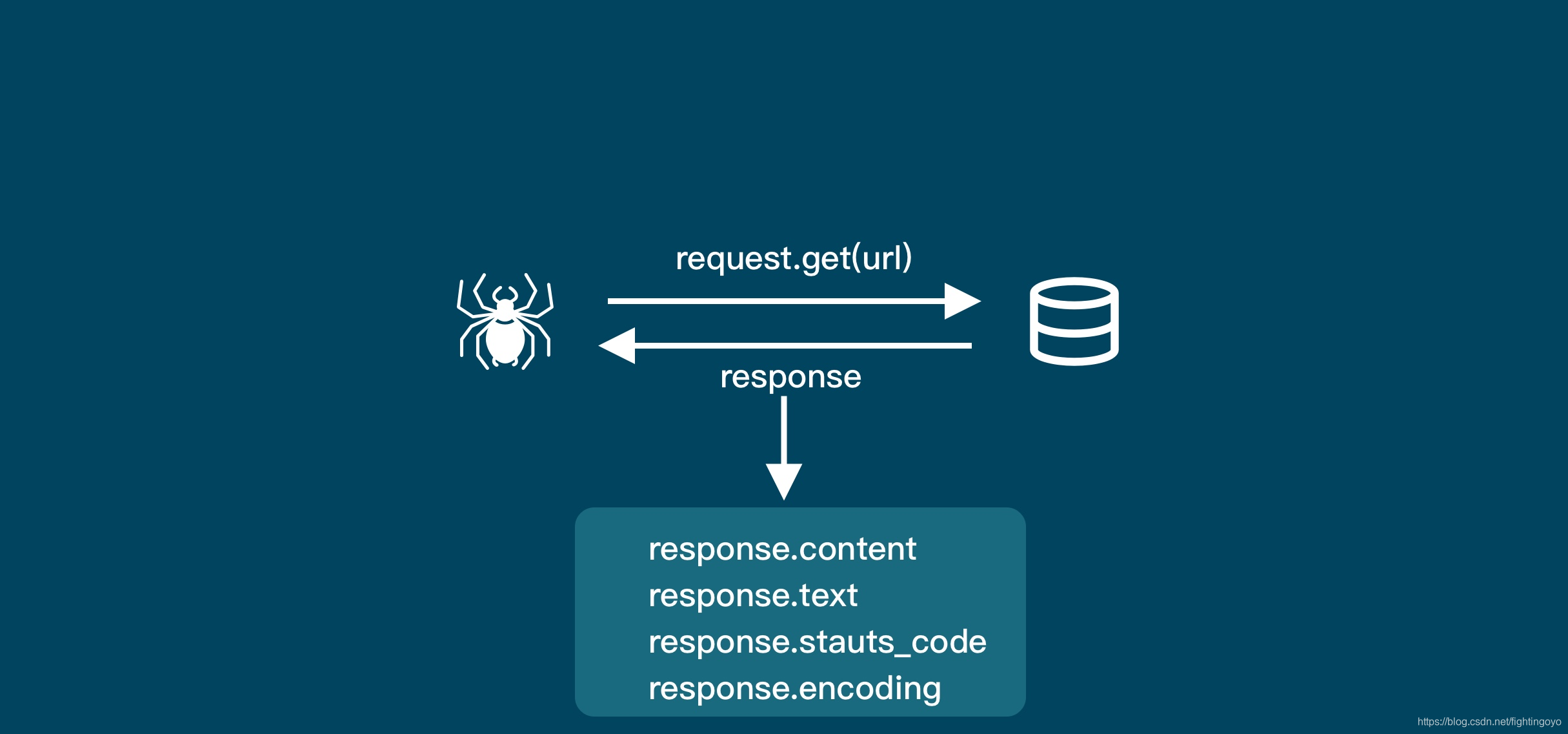
对于爬虫来说,「请求」和「响应」都是去「获取数据」。他们是一个步骤的两个部分。所以把他们统一之后,爬虫的工作原理就是下图:

- 获取数据。爬虫会拿到我们要它去爬的网址,像服务器发出请求,获得服务器返回的数据。
- 解析数据。爬虫会将服务器返回的数据转换成人能看懂的样式。
- 筛选数据。爬虫会从返回的数据中筛选出我们需要的特定数据。
- 存储数据。爬虫会根据我们设定的存储方式,将数据保存下来,方便我们进行后一步的操作。
三、requests库
这是爬虫的第一步:获取数据。
在电脑中安装requests库的方法如下:
- 在Mac电脑里打开终端软件(terminal),输入pip3 install requests,然后点击enter即可;
- Windows电脑里叫命令提示符(cmd),输入pip install requests 即可。
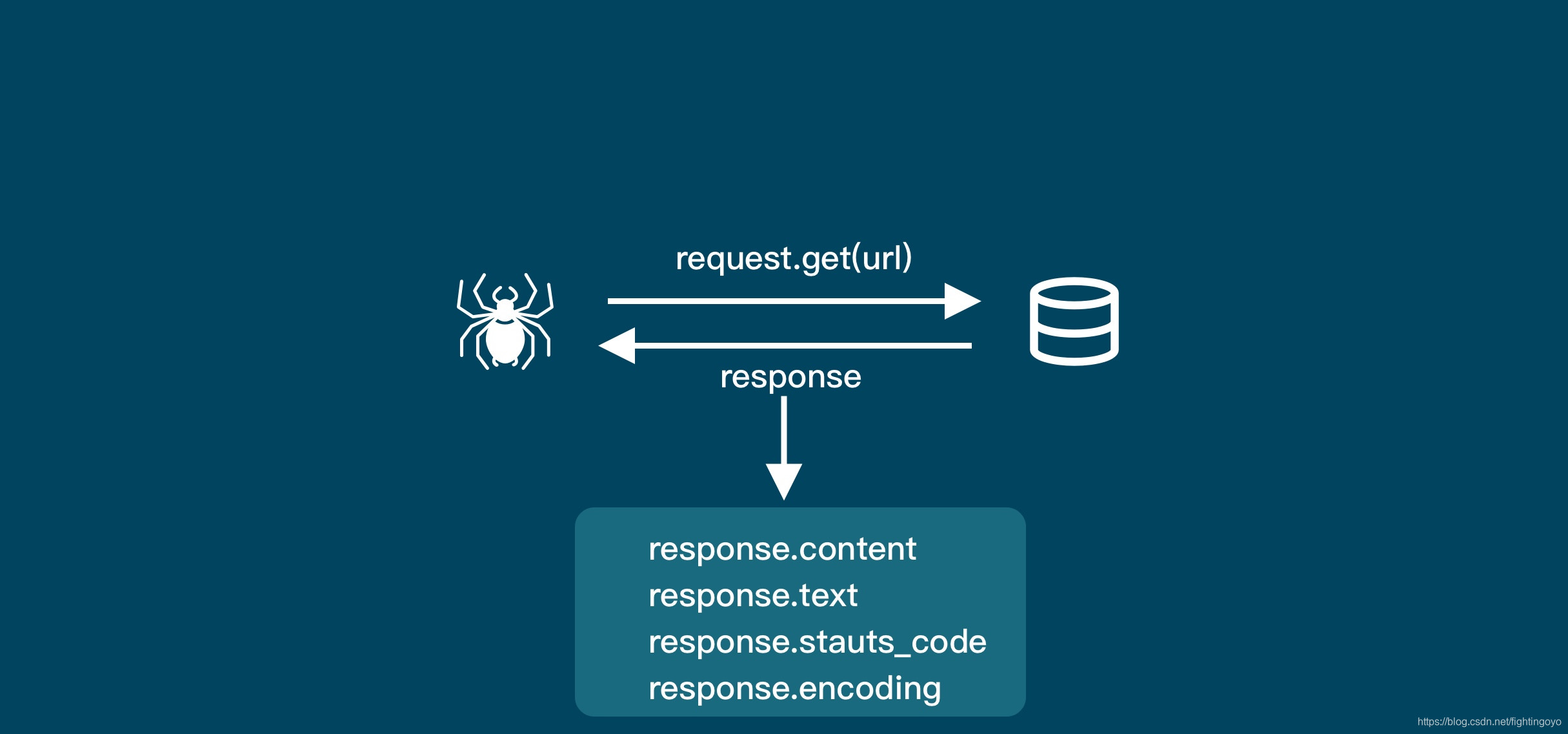
1. requests.get()
import requests
#在使用前需要先通过 import 来引入 requests 库
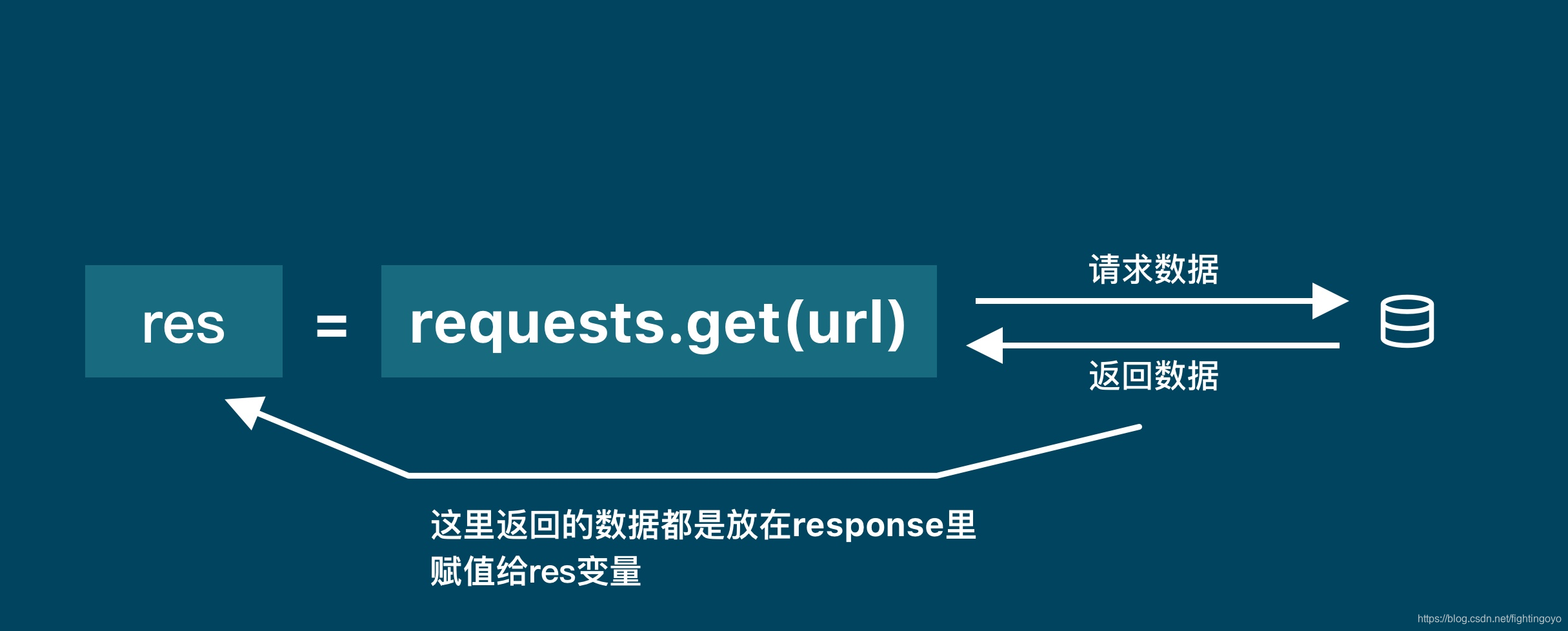
res = requests.get('URL')
#我们通过调用requests库中的get()方法来获取数据,这个方法需要一个参数,这个参数就是你需要请求的网址。当请求得到「响应」时,服务器返回的数据就被赋值到 res 这个变量上面
- 案例:使用requests.get()下载《滕王阁序》
import requests
response = requests.get('https://xiaoke.kaikeba.com/example/gexu/tengwanggexu.txt')
2. response对象
Python是一门面向对象编程的语言,在面向对象的世界中,一切皆可为对象。在这里Response也是一个对象,他有自己的属性和方法。在我们知道一个数据是什么对象的时候,就可以去使用它对应的属性和方法。
刚刚通过requests.get()拿到的就是一个response对象。
import requests
response = requests.get('https://xiaoke.kaikeba.com/example/gexu/tengwanggexu.txt')
print(type(response)) # 打印response的数据类型
# 输出结果:
<class 'requests.models.Response'>
代码运行结果显示,res是一个对象,它是一个requests.models.Response类。
response对象的四大常用属性:
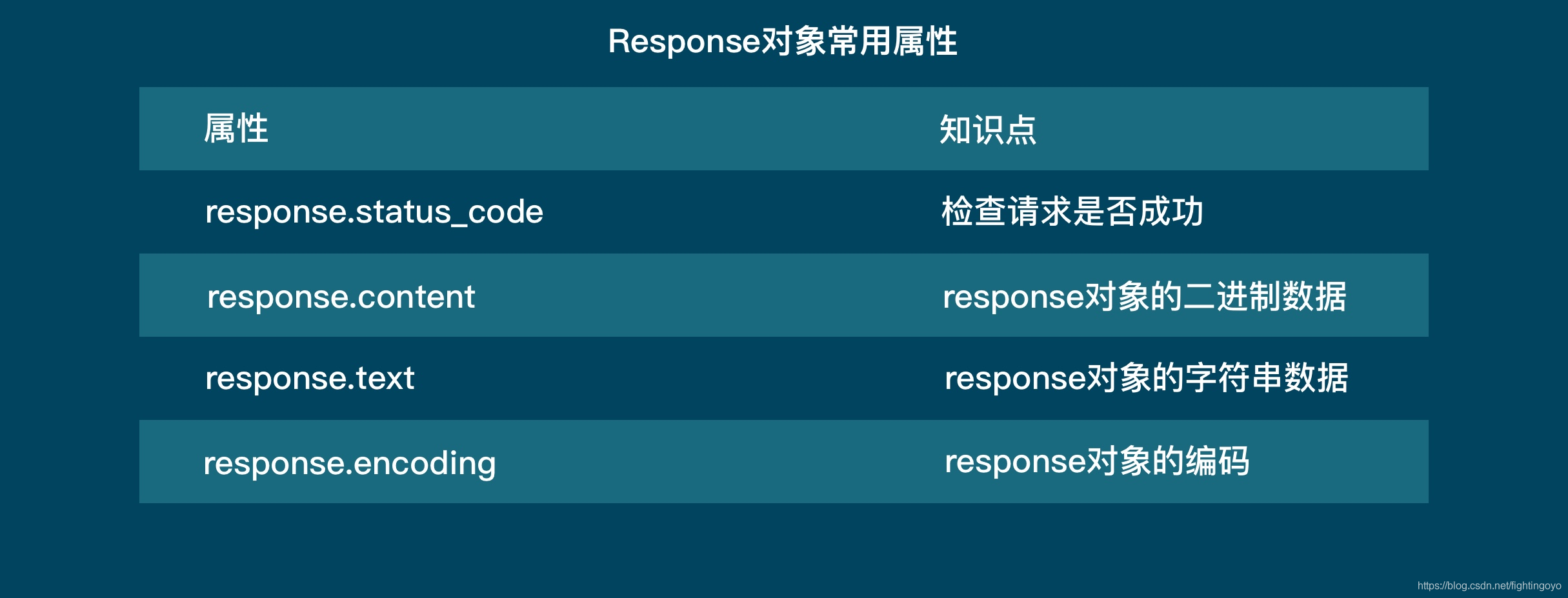
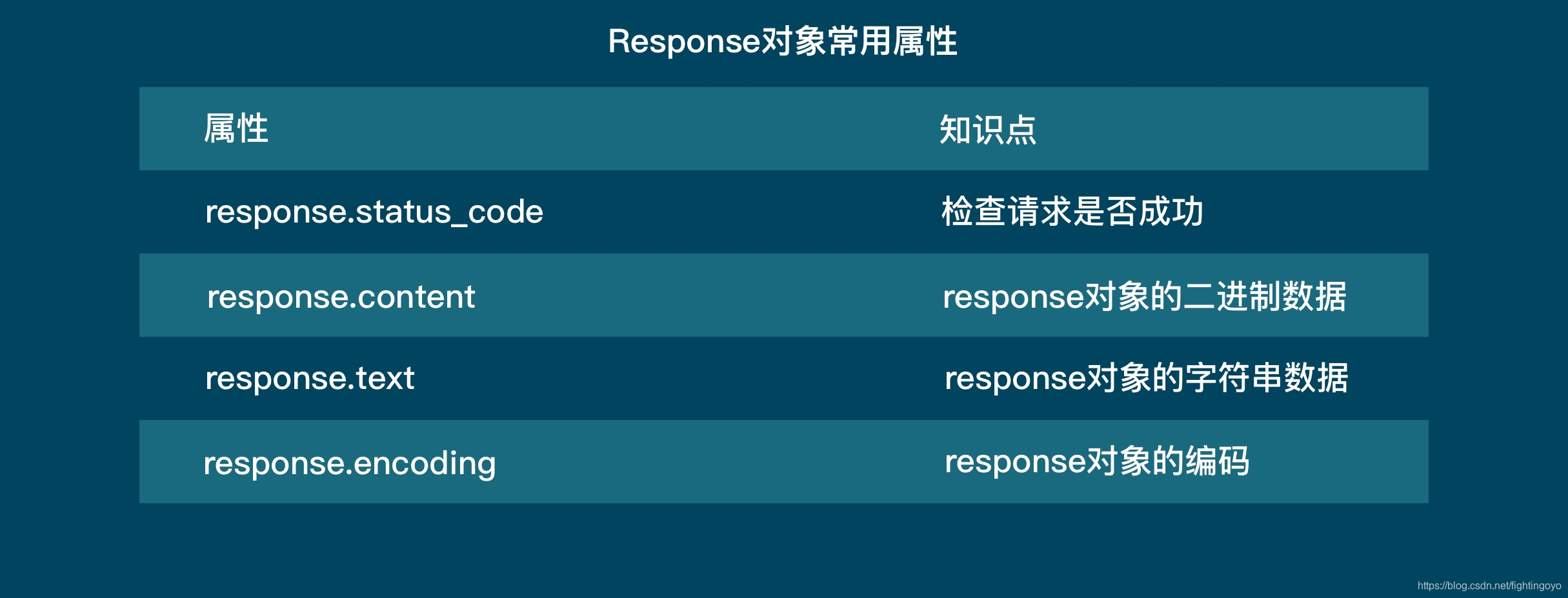
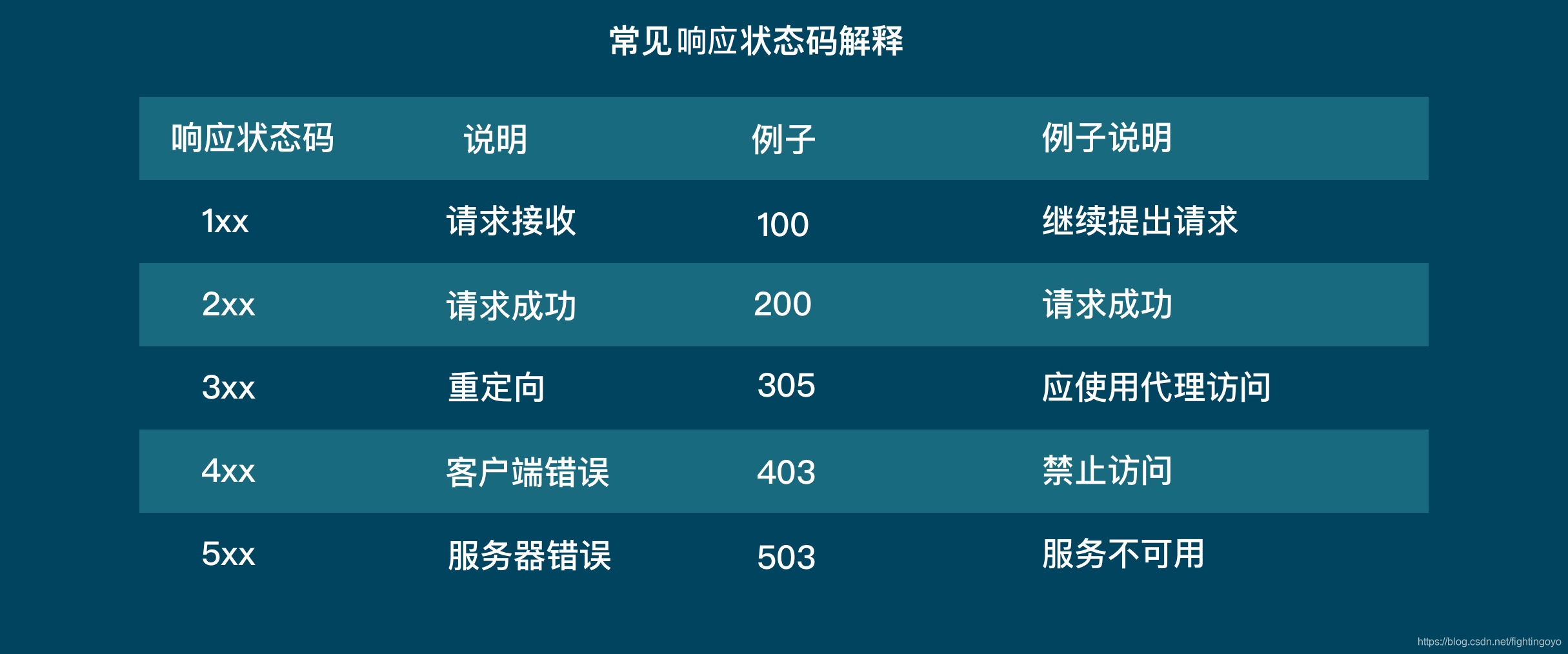
- response.status_code
import requests
response = requests.get('https://xiaoke.kaikeba.com/example/gexu/tengwanggexu.txt')
print(response.status_code)
# 输出结果:
200
这段代码把response的status_code打印出来,如果是200,那么就意味着这个请求是成功的。服务器收到了我们的请求,并返回了数据给我们。

- response.content
它保存着服务器返回的数据的二进制内容。
案例:去下载一张周杰伦的图片
import requests
# 发出请求,并把返回的结果放在变量response中
response = requests.get('http://b-ssl.duitang.com/uploads/blog/201501/20/20150120134050_BXihr.jpeg')
# 把Reponse对象的内容以二进制数据的形式返回
pic = response.content
# 新建了一个文件jay.jpeg,这里的文件没加路径,它会被保存在程序运行的当前目录下
# 图片内容需要以二进制wb读写。
photo = open('jay.jpeg','wb')
# 获取pic的二进制内容
photo.write(pic)
# 关闭文件
photo.close()
# 输出结果为:我们能在本地得到一张周杰伦的图片
- response.text
这个属性其实就是将 response.content 的二进制数据转换为字符串,适用于文字或者是网页源代码的下载.
import requests
# 用request去下载《滕王阁序》,将返回的 response 对象保存到 res 变量中
response = requests.get('https://xiaoke.kaikeba.com/example/gexu/tengwanggexu.txt')
# 把Response对象的内容以字符串的形式返回
novel = response.text
# 打印变量novel
print(novel)
# 输出结果为整篇《滕王阁序》
import requests
# 用request去下载《滕王阁序》,将返回的 response 对象保存到 res 变量中
response = requests.get('https://xiaoke.kaikeba.com/example/gexu/tengwanggexu.txt')
# 把Response对象的内容以字符串的形式返回
novel = response.text
# 将《滕王阁序》保存到本地
with open('滕王阁序.txt','w') as twg:
twg.write(novel)
- response.encoding
import requests
# 用request去下载《滕王阁序》,将返回的 response 对象保存到 res 变量中
response = requests.get('https://xiaoke.kaikeba.com/example/gexu/tengwanggexu.txt')
# 把Response对象的内容以字符串的形式返回
response.encoding='gbk'
novel = response.text
print(novel)
以上经过encoding之后的novel打印出来为一堆乱码。
这是因为所有的文本数据都有编码类型。这篇文章的编码格式原本是’utf-8’。一般来说,requests库会帮我们自动去判断编码类型,不需要手动指定。
但是如果遇到一些需要自己去指定数据的编码类型的情况,就可以使用“response.encoding”去改变“response”拿到的数据的编码类型。我们手动指定了编码类型为‘gbk’而不是‘utf-8’。所以导致了编码类型不一致,出现了乱码!
再将更改为’gbk‘的编码变更回’utf-8’,这样就能正常打印输出了。
import requests
# 用request去下载《滕王阁序》,将返回的 response 对象保存到 res 变量中
response = requests.get('https://xiaoke.kaikeba.com/example/gexu/tengwanggexu.txt')
# 把Response对象的内容以字符串的形式返回
response.encoding='gbk'
response.encoding='utf-8'
novel = response.text
print(novel)
四、总结
-
浏览器工作原理
-
爬虫工作原理
-
爬虫的四个步骤

-
requests库
五、练习
- 获取文章《蜀道难》全部内容,并且打印出全文内容。 文章网址为:https://xiaoke.kaikeba.com/example/gexu/shudaonan.txt。
import requests
# 使用requests.get()获取数据
response = requests.get('https://xiaoke.kaikeba.com/example/gexu/shudaonan.txt')
# 打印数据请求的状态
print(response.status_code)
# 将返回的数据以text形式赋值给变量
article = response.text
# 打印articel
print(article)
- 将《蜀道难》存储到本地
import requests
# 使用requests.get()获取数据
response = requests.get('https://xiaoke.kaikeba.com/example/gexu/shudaonan.txt')
# 打印数据请求的状态
print(response.status_code)
# 将返回的数据以text形式赋值给变量
article = response.text
# 创建"蜀道难.txt"的文件,并以写入模式打开
sdn = open('蜀道难.txt','w')
# 将网站返回的内容写入txt文件中
sdn.write(article)
# 关闭文件
sdn.close()
- 下载一张彭于晏的图片。图片地址为:https://ss3.bdstatic.com/70cFv8Sh_Q1YnxGkpoWK1HF6hhy/it/u=21565698,717792087&fm=26&gp=0.jpg
import requests
# 使用requests.get()获取数据
response = requests.get('https://ss3.bdstatic.com/70cFv8Sh_Q1YnxGkpoWK1HF6hhy/it/u=21565698,717792087&fm=26&gp=0.jpg')
# 将数据以二进制的形式存储到变量中
pic = response.content
# 以"彭于晏.jpg"创建文件,并以'wb'模式打开
with open('彭于晏.jpg','wb') as myfile:
# 将图片写入文件中
myfile.write(pic)
