VGG介绍
VGGNet 是牛津大学计算机视觉组(Visual Geometry Group)和 Google DeepMind 公司的研究员一起研发的的深度卷积神经网络,在 ILSVRC 2014 上取得了第二名的成绩,将 Top-5错误率降到7.3%。
VGGNet 探索了卷积神经网络的深度与其性能之间的关系,通过反复堆叠3´3的小型卷积核和2´2的最大池化层,VGGNet 成功地构筑了16~19层深的卷积神经网络。VGGNet 相比之前 state-of-the-art 的网络结构,错误率大幅下降,并取得了 ILSVRC 2014 比赛分类项目的第2名和定位项目的第1名。
同时 VGGNet 的拓展性很强,迁移到其他图片数据上的泛化性非常好。VGGNet 的结构非常简洁,整个网络都使用了同样大小的卷积核尺寸(3´3)和最大池化尺寸(2´2)。到目前为止,VGGNet 依然经常被用来提取图像特征。VGGNet 训练后的模型参数在其官方网站上开源了,可用来在 domain specific 的图像分类任务上进行再训练(相当于提供了非常好的初始化权重),因此被用在了很多地方。
网络结构
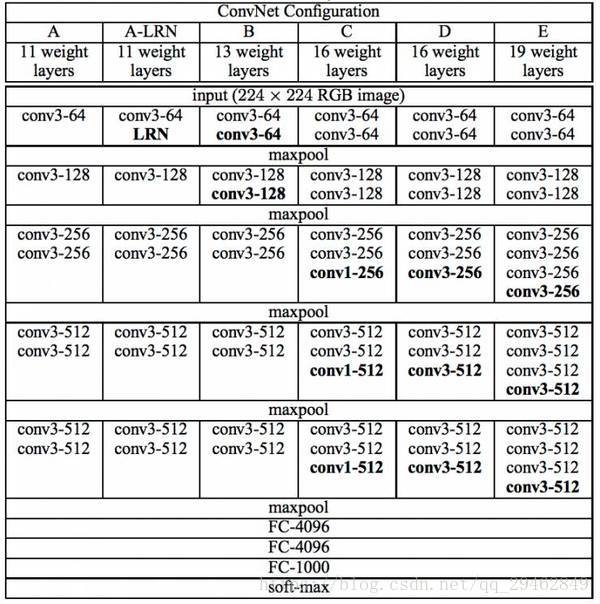
VGGNet 论文中全部使用了3´3的卷积核和2´2的池化核,通过不断加深网络结构来提升性能。下图所示为 VGGNet 各级别的网络结构图,以及随后的每一级别的参数量,从11层的网络一直到19层的网络都有详尽的性能测试。虽然从A到E每一级网络逐渐变深,但是网络的参数量并没有增长很多,这是因为参数量主要都消耗在最后3个全连接层。前面的卷积部分虽然很深,但是消耗的参数量不大,不过训练比较耗时的部分依然是卷积,因其计算量比较大。这其中的D、E也就是我们常说的 VGGNet-16 和 VGGNet-19。C相比B多了几个1´1的卷积层,1´1卷积的意义主要在于线性变换,而输入通道数和输出通道数不变,没有发生降维。
简化
由于VGG模型参数过大,在这里只讨论VGG11模型,并在mnist数据集上进行测试。因为mnist数据集中的图像尺寸为28*28,所以对max_pooling处理次数有所要求,这一点在下面的源码中有对应。注意,因为VGG属于模型参数比较大的网络,当应用在自己的数据时(比如224*224)一定要小心!!!
源代码
#tensorflow基于mnist数据集上的VGG11网络,可以直接运行
from tensorflow.examples.tutorials.mnist import input_data
import tensorflow as tf
#tensorflow基于mnist实现VGG11
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
x = tf.placeholder(tf.float32, [None, 784])
y_ = tf.placeholder(tf.float32, [None, 10])
sess = tf.InteractiveSession()
#Layer1
W_conv1 =tf.Variable(tf.truncated_normal([3, 3, 1, 64],stddev=0.1))
b_conv1 = tf.Variable(tf.constant(0.1,shape=[64]))
#调整x的大小
x_image = tf.reshape(x, [-1,28,28,1])
h_conv1 = tf.nn.relu(tf.nn.conv2d(x_image, W_conv1,strides=[1, 1, 1, 1], padding='SAME') + b_conv1)
#Layer2 pooling
W_conv2 = tf.Variable(tf.truncated_normal([3, 3, 64, 64],stddev=0.1))
b_conv2 = tf.Variable(tf.constant(0.1,shape=[64]))
h_conv2 = tf.nn.relu(tf.nn.conv2d(h_conv1, W_conv2,strides=[1, 1, 1, 1], padding='SAME') + b_conv2)
h_pool2 = tf.nn.max_pool(h_conv2, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1], padding='SAME')
#Layer3
W_conv3 = tf.Variable(tf.truncated_normal([3, 3, 64, 128],stddev=0.1))
b_conv3 = tf.Variable(tf.constant(0.1,shape=[128]))
h_conv3 = tf.nn.relu(tf.nn.conv2d(h_pool2, W_conv3,strides=[1, 1, 1, 1], padding='SAME') + b_conv3)
#Layer4 pooling
W_conv4 = tf.Variable(tf.truncated_normal([3, 3, 128, 128],stddev=0.1))
b_conv4 = tf.Variable(tf.constant(0.1,shape=[128]))
h_conv4 = tf.nn.relu(tf.nn.conv2d(h_conv3, W_conv4,strides=[1, 1, 1, 1], padding='SAME') + b_conv4)
h_pool4= tf.nn.max_pool(h_conv4, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1], padding='SAME')
#Layer5
W_conv5 = tf.Variable(tf.truncated_normal([3, 3, 128, 256],stddev=0.1))
b_conv5 = tf.Variable(tf.constant(0.1,shape=[256]))
h_conv5 = tf.nn.relu(tf.nn.conv2d(h_pool4, W_conv5,strides=[1, 1, 1, 1], padding='SAME') + b_conv5)
#Layer6
W_conv6 = tf.Variable(tf.truncated_normal([3, 3, 256, 256],stddev=0.1))
b_conv6 = tf.Variable(tf.constant(0.1,shape=[256]))
h_conv6 = tf.nn.relu(tf.nn.conv2d(h_conv5, W_conv6,strides=[1, 1, 1, 1], padding='SAME') + b_conv6)
#Layer7
W_conv7 = tf.Variable(tf.truncated_normal([3, 3, 256, 256],stddev=0.1))
b_conv7 = tf.Variable(tf.constant(0.1,shape=[256]))
h_conv7 = tf.nn.relu(tf.nn.conv2d(h_conv6, W_conv7,strides=[1, 1, 1, 1], padding='SAME') + b_conv7)
#Layer8
W_conv8 = tf.Variable(tf.truncated_normal([3, 3, 256, 256],stddev=0.1))
b_conv8 = tf.Variable(tf.constant(0.1,shape=[256]))
h_conv8 = tf.nn.relu(tf.nn.conv2d(h_conv7, W_conv8,strides=[1, 1, 1, 1], padding='SAME') + b_conv8)
h_pool8 = tf.nn.max_pool(h_conv8, ksize=[1, 2, 2, 1],
strides=[1, 1, 1, 1], padding='SAME')
#Layer9-全连接层
W_fc1 = tf.Variable(tf.truncated_normal([7*7*256,1024],stddev=0.1))
b_fc1 = tf.Variable(tf.constant(0.1,shape=[1024]))
#对h_pool2数据进行铺平
h_pool2_flat = tf.reshape(h_pool8, [-1, 7*7*256])
#进行relu计算,matmul表示(wx+b)计算
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
keep_prob = tf.placeholder(tf.float32)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
#Layer10-全连接层,这里也可以是[1024,其它],大家可以尝试下
W_fc2 = tf.Variable(tf.truncated_normal([1024,1024],stddev=0.1))
b_fc2 = tf.Variable(tf.constant(0.1,shape=[1024]))
h_fc2 = tf.nn.relu(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
h_fc2_drop = tf.nn.dropout(h_fc2, keep_prob)
#Layer11-softmax层
W_fc3 = tf.Variable(tf.truncated_normal([1024,10],stddev=0.1))
b_fc3 = tf.Variable(tf.constant(0.1,shape=[10]))
y_conv = tf.matmul(h_fc2_drop, W_fc3) + b_fc3
#在这里通过tf.nn.softmax_cross_entropy_with_logits函数可以对y_conv完成softmax计算,同时计算交叉熵损失函数
cross_entropy = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y_conv))
#定义训练目标以及加速优化器
train_step = tf.train.AdamOptimizer(1e-3).minimize(cross_entropy)
#计算准确率
correct_prediction = tf.equal(tf.argmax(y_conv,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
#初始化变量
saver = tf.train.Saver()
sess.run(tf.global_variables_initializer())
for i in range(20000):
batch = mnist.train.next_batch(10)
if i%100 == 0:
train_accuracy = accuracy.eval(feed_dict={
x:batch[0], y_: batch[1], keep_prob: 1.0})
print("step %d, training accuracy %g"%(i, train_accuracy))
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
#保存模型
save_path = saver.save(sess, "./model/save_net.ckpt")
print("test accuracy %g"%accuracy.eval(feed_dict={
x: mnist.test.images[:3000], y_: mnist.test.labels[:3000], keep_prob: 1.0}))实验结果
由于mnist数据集相对比较简单,在迭代8次左右基本上完成收敛,这一点也说明VGG网络的优越性!!!
step 0, training accuracy 0
step 100, training accuracy 0.7
step 200, training accuracy 0.9
step 300, training accuracy 0.9
step 400, training accuracy 0.9
step 500, training accuracy 0.9
step 600, training accuracy 1
step 700, training accuracy 1