zookeeper的来由
最大一个特点就是解决分布式一致性问题。简单讲,数据一致性就是指在对一个副本数据进行更新的同时,必须确保也能更新其他副本(其他副本可能在各个不同的服务器节点),否则不同副本之间的数据将不再一致。那么解决这样的一致性问题,大家肯定想到使用锁,但使用简单的使用锁实在太影响性能。所以有很多一致性协议出现,二阶段提交协议,三阶段提交协议,还有Paxos算法等。
1.2PC(Two-Phase Commit)二阶段提交和3PC(Two-Phase Commit)三阶段提交
在分布式系统中,每一个机器节点虽然能明确的知道自己在进行事务操作过程中的结果是成功还是失败,但却无法直接获取其他分布式节点的操作结果。因此,当一个事务操作需要跨越多个分布式节点的时候,为了保持事务的ACID特性,就需要引入一个"协调者"(分布式节点的某一个节点),统一调度所有分布式节点。这些被调度的分布式称为"参与者"。协调者负责调度参与者的行为,并最终决定这些参与者是否要把事务真正的提交。基于这样的思想,就出现了2PC和3PC,3PC是2PC的提升。
2PC如下图:
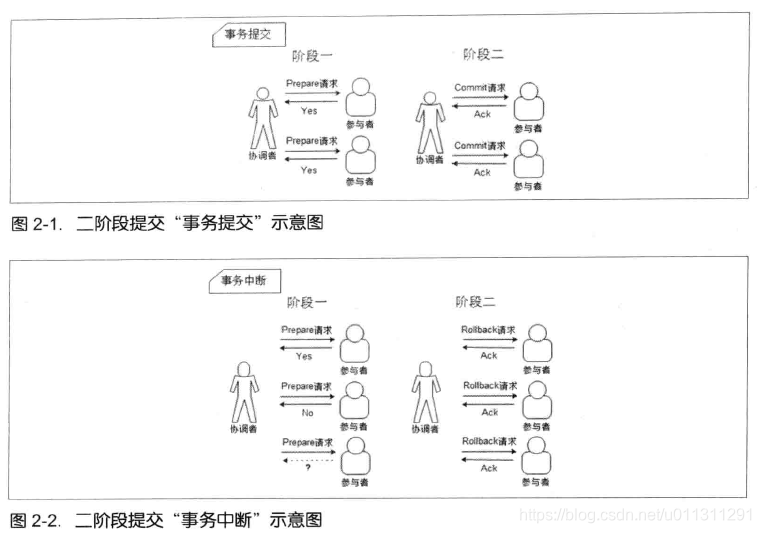
3PC如下图:
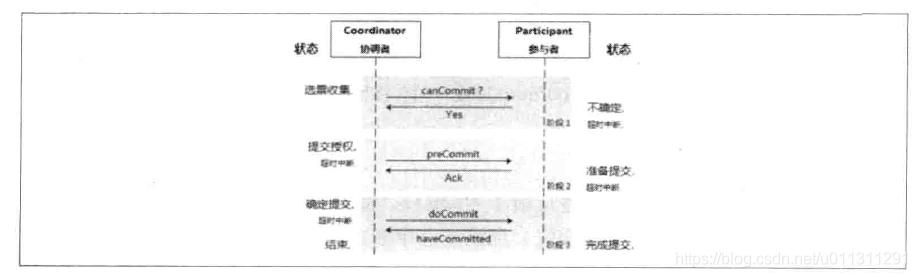
2PC,3PC对事务的执行其实都差不多
优点:原理简单,实现方便
缺点:当出现网络故障的时候,无法保证数据的一致性
2.Paxos
Paxos是莱斯利兰伯特于1990年提出的一种基于消息传递,且具有高度容错特性的一致性算法,是目前公认解决分布式一致性问题最有效的算法之一。Paxos算法引入"过半"的理念,也就是少数服从多数原则,支持分布式节点角色之间轮换,这可以避免分布式单点宕机问题,也保证了数据一致性。
Zookeeper
zookeeper并没有直接采用Paxos算法,而是采用了一种被称为ZAB(zookeeper Atomic Broadcast)的一致性协议。
zookeeper的设计目的
将那些复杂且容易出错的分布式一致性服务封装起来,构成一个高效可靠的原语集,并以一些列简单易用的接口提供给用户使用。
zookeeper的特性
1.顺序一致性
从同一个客户端发起的事务请求,最终将会严格的按照其发起的顺序被应用到ZooKeeper中
2.原子性
所有事务请求处理结果在整个集群中所有机器上的应用情况是一致的
3.单一试图
无论客户端连接的是哪个Zookeeper服务器,其看到的服务端数据模型都是一致的
4.可靠性
5.实时性
zookeeper仅仅保证在一定的时间段内,客户端最终一定能从服务器上读取到最新的数据状态
zookeeper的设计
1.简单的数据模型
zookeeper分布式通过一个共享的,树型结构的名字空间来进行协调,由一些列的Znode数据节点构成,数据模型类似于一个文件系统,但zookeeper是将全量数据存储在内存中,以实现高服务吞吐,减少延迟的目的。
2.可以构建集群
集群中存在超过一半的机器能够正常工作,那么整个集群就能够正常对外服务,zookeeper的客户端会选择和集群中的任意一台机器共同创建一个TCP连接,而一旦服务器一旦出现问题,客户端会自动连接到集群中的其他机器。
3.顺序访问
客户端的每一个更新请求,zookeeper都会分配一个全局唯一的递增编号,以保证顺序
4.高性能
因为zookeeper将全量数据在内存中,所以具有高性能
zookeeper的集群角色
没有沿用Master/Slave概念,而是引入可Leader,Follower和Observer三种角色
1.Leader
主要工作:
(1)事务请求的唯一调度者和处理者,保证集群事务处理的顺序性
(2)集群内部各服务器的调度者
2.Follower
主要工作
(1)处理客户端非事务请求,转发事务请求给Leader服务器
(2)参与事务请求Proposal的投票
(3)参与Leader选举投票
3.Observer
工作原理上和Follower基本一致,唯一区别在于不参与任务形式投票,包括事务请求Proposal的投票和Leader选举投票。
通常用于在不影响集群事务处理能力前提下提升集群的非事务处理能力。
zookeeper监听器Watcher
Watcher是Zookeeper中的一个很重要的特性,Zookeeper允许用户在指定节点上注册一些Watcher,并且在一些特定事件触发的时候
zookeeper会将事件通知到感兴趣的客户端上。
应用程序使用zookeeper的目的
1.数据发布/订阅
2.负载均衡
3.命名服务
4.分布式协调/通知
5.集群管理
6.Master选举
7.分布式锁和分布式队列等功能
zookeeper的安装和使用
先要装java1.8,然后下载zookeeper包,解压
1.先设置配置文件
将conf目录下的zoo_sample.cfg更名为zoo.cfg
2.使用bin/zkServer.sh start 启动zookeeper
3.使用jps查看java进程名称
4.使用bin/zkServer.sh status查看zookeeper的状态
5.使用bin/zkCli.sh启动客户端和zookeeper服务器进行连接
连接成功以后可以使用help查看各种命令
6.查看目录 ls /
7.通过get /zookeeper/quota查看有什么数据,还有当前磁盘的信息
8.创建节点 create /test 111,意思就是创建一个文件目录test,然后再创建节点111,然后使用ls可以查看
9.可以通过set /test 222将此节点111修改为222
10.删除目录 rmr /test
zookeeper集群搭建
官方建议1,3,5这样奇数搭建
只需要在一个服务器上配置,然后往其它服务器进行拷贝就可以了,拷贝可以是整个zookeeper文件夹
比如下面配置3个服务器
1.在conf zoo.cfg中添加服务器编号
server.1=hadoop-senior01.test.com(主机名或者IP,10.42.27.1):2888(进行数据同步端口号):3888(选主通信端口号)
server.2=hadoop-senior02.test.com:2888:3888
server.3=hadoop-senior03.test.com:2888:3888
2.然后再data 目录下创建文件myid,内容为编号id,比如1,2,3
3.然后启动3个服务,使用bin/zkServer.sh status查看zookeeper的状态,看哪个是主,哪个是从
4.可以使用bin/zkCli.sh -server hadoop-senior01.test.com:2181(端口号) 连接各个服务
java客户端的API使用
1.可以使用zookeeper自带的API
2.使用开源客户端ZkClient
3.使用开源客户端Curator
zookeeper的典型应用
1.数据的发布/订阅
比如:创建节点/configServer/app1/database/cfg,记录数据库的连接信息,所有的服务器都监听该节点,假设数据库连接信息变更,则所有服务器立马就会受到变更消息,重新更改自己的连接。
2.用来集群管理,Master选择