Tensorflow基于CNN的AutoEncoder
完整代码:https://github.com/SongDark/cnn_autoencoder_mnist
一、概述
AutoEncoder属于无监督学习,由一个编码器Encoder和一个解码器Decoder组成,是一个Encoder-Decoder结构,它学习的目标是还原输入,不需要提供标签。
二、数据源
使用Mnist作为训练数据,Mnist的获取可以参考这篇博客:
获取MNIST数据的几种方法
三、Encoder和Decoder结构
Encoder输入图片输出编码,Decoder输入编码输出图片,因此用多层卷积结构实现Encoder,用多层解卷积结构实现Decoder。下面代码实现的结构,支持任意指定编码维度(output_dim)。
class CNN_Encoder(BasicBlock):
def __init__(self, output_dim, sn=False, name=None):
super(CNN_Encoder, self).__init__(None, name or "CNN_Encoder")
self.output_dim = output_dim
self.sn = sn # spectral norm
def __call__(self, x, sn=False, is_training=True, reuse=False):
with tf.variable_scope(self.name, reuse=reuse):
net = lrelu(conv2d(x, 64, 4, 4, 2, 2, sn=self.sn, padding="SAME", name="conv1"), name="l1")
net = lrelu(bn(conv2d(net, 128, 4, 4, 2, 2, sn=self.sn, padding="SAME", name="conv2"), is_training, name="bn2"), name="l2")
net = lrelu(bn(conv2d(net, 256, 4, 4, 2, 2, sn=self.sn, padding="SAME", name="conv3"), is_training, name="bn3"), name="l3")
net = tf.reshape(net, [-1, 4*4*256])
net = lrelu(bn(dense(net, 1024, sn=self.sn, name="fc4"), is_training, name="bn4"), name="l4")
out = dense(net, self.output_dim, sn=self.sn, name="fc5")
return out
class CNN_Decoder(BasicBlock):
def __init__(self, sn=False, name=None):
super(CNN_Decoder, self).__init__(None, name or "CNN_Decoder")
self.sn = sn
def __call__(self, x, is_training=True, reuse=False):
with tf.variable_scope(self.name, reuse=reuse):
net = tf.nn.relu(dense(x, 1024, name='fc1'))
net = tf.nn.relu(bn(dense(net, 256*4*4, name='fc2'), is_training, name='bn2'))
net = tf.reshape(net, [-1, 4, 4, 256])
net = tf.nn.relu(bn(deconv2d(net, 128, 4, 4, 1, 1, padding="VALID", name='dc3'), is_training, name='bn3'))
net = tf.nn.relu(bn(deconv2d(net, 64, 4, 4, 2, 2, padding="SAME", name='dc4'), is_training, name='bn4'))
out = tf.nn.sigmoid(deconv2d(net, 1, 4, 4, 2, 2, padding="SAME", name="dc5"))
return out
四、AutoEncoder实现
核心代码
# 核心代码
def build_placeholder(self):
self.source = tf.placeholder(shape=(self.batch_size, 28, 28, 1), dtype=tf.float32)
self.target = tf.placeholder(shape=(self.batch_size, 28, 28, 1), dtype=tf.float32)
def build_network(self):
self.embedding = self.encoder(self.source, is_training=True, reuse=False)
self.pred = self.decoder(self.embedding, is_training=True, reuse=False)
def build_optimizer(self):
self.loss = mse(self.pred, self.target, self.batch_size)
self.solver = tf.train.AdamOptimizer(learning_rate=2e-4, beta1=0.5).minimize(self.loss, var_list=self.encoder.vars + self.decoder.vars)
五、恢复效果
经过试验,用上面的Encoder和Decoder,需要将编码维度至少设为8以上,才能有比较好的恢复效果。原本想尝试压缩成2维,但是基本无法还原。
下图是编码长度为10的结果,每一行4附图,奇数位为Encoder输入的原图,偶数位为Decoder恢复图。

六、编码可视化
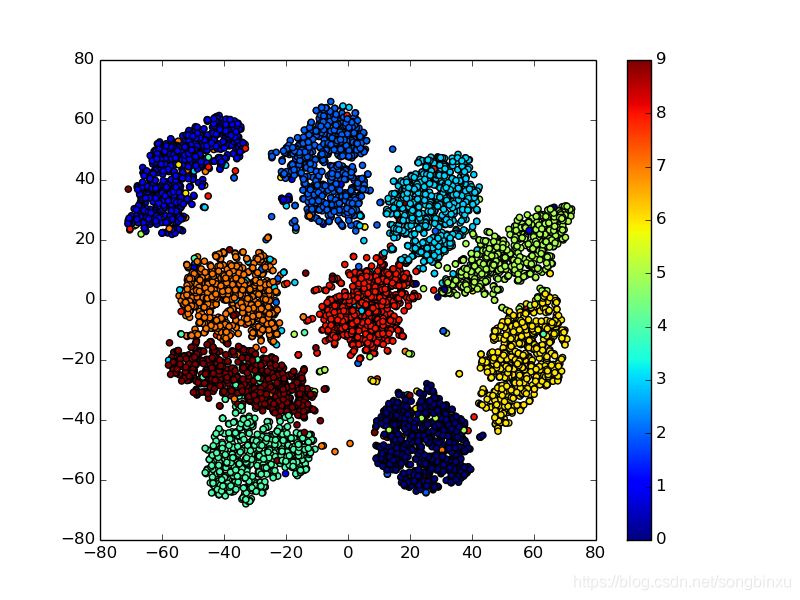
用t-sne将10维的编码降维至2维,以在平面直角坐标系中可视化。
# 核心代码
from sklearn.manifold import TSNE
model = TSNE(n_components=2, random_state=0)
embs = model.fit_transform(embs)
plt.scatter(embs[:, 0], embs[:, 1], c=labels)
plt.colorbar()
t-sne只是对Encoder的编码做了降维,可以看到降维后,数字0(深蓝)、6(黄)、9(红)靠得很近,因为它们比较相似,编码效果与我的直观感受是一致的。
完整代码
https://github.com/SongDark/cnn_autoencoder_mnist