首先理解一下cnn的原理。在传统的MLP中,隐含层通常和输入层都需要全连接,各个连接权重参数除了初始需要人为设定之外,模型在训练过程中都会不断修改权重参数,以达到最终的预测目的。在数据量不大的情况下,全连接是很好的,训练过程中不会损失任何样本信息。但是当样本数据增大时,全连接将会使得模型训练时间大大延长甚至模型无法训练完成,或者训练完成后出现过拟合。例如假设输入数据为一个包含100万个元素的矩阵,隐含层节点也有100万个,此时输入节点全连接到隐含层的权重数量为100万X100万=。。。,这么多参数需要通过样本数据去完成训练,很难,即使训练完成,也会出现过拟合。那么怎么克服呢?cnn就很好用了。
同样用上述假设,输入节点有一百万个,隐含层节点也有一百万个,现在我们将全连接方式改为局部连接,例如每个隐含层节点只连接10x10个输入层节点(感受野),那么一个隐含层节点就只会有100个参数需要训练,总共要训练的参数数量就为100x100万,这样一下参数数量就减少了一万倍。当然这样参数数量还是很多,下一步我们想象,如果这100万个隐藏层节点都为参数相同的节点(权值共享),这样的话我们经过这样的一个隐含层之后拿到的隐含层输出(特征图)是不是还是可以用来进行分类呢?答案是可以的,当然我们需要有若干个这样的隐含层对原始的输入数据进行相同的处理,而且每个隐含层的权重参数不能一样。经过这样的一个步骤之后,我们发现每个隐含层需要训练的数据居然直接就到了100个,也就是我们每个隐含层节点连接的输入层节点个数。这样的话,我们就大大减少了需要训练的参数个数,可以进行下一步的预测了。
在上面的描述中,我们把每个隐含层节点连接的输入层节点个数叫做感受野(receptive field)。这10x10个参数组成的权值矩阵叫做卷积核,每个卷积核和原始数据卷积一次之后的隐含层输出叫做特征图(feature map)。每个隐含层都只用一个卷积核和原图像进行卷积操作,这样叫做权值共享,因为卷积核本质上就是权值矩阵嘛。每个卷积核和原始数据卷积的隐含层组合起来之后就构成了整个的卷积层。
接着上面的说,我们的卷积层的输出结果应该是若干个特征图,数量取决于卷积核的数量。对于每一个特征图,我们还要对其进行池化处理,这本质上也是用来降低数据量的一种做法。例如常用的最大池化,在网上随便找了一张图,很直观,如下:
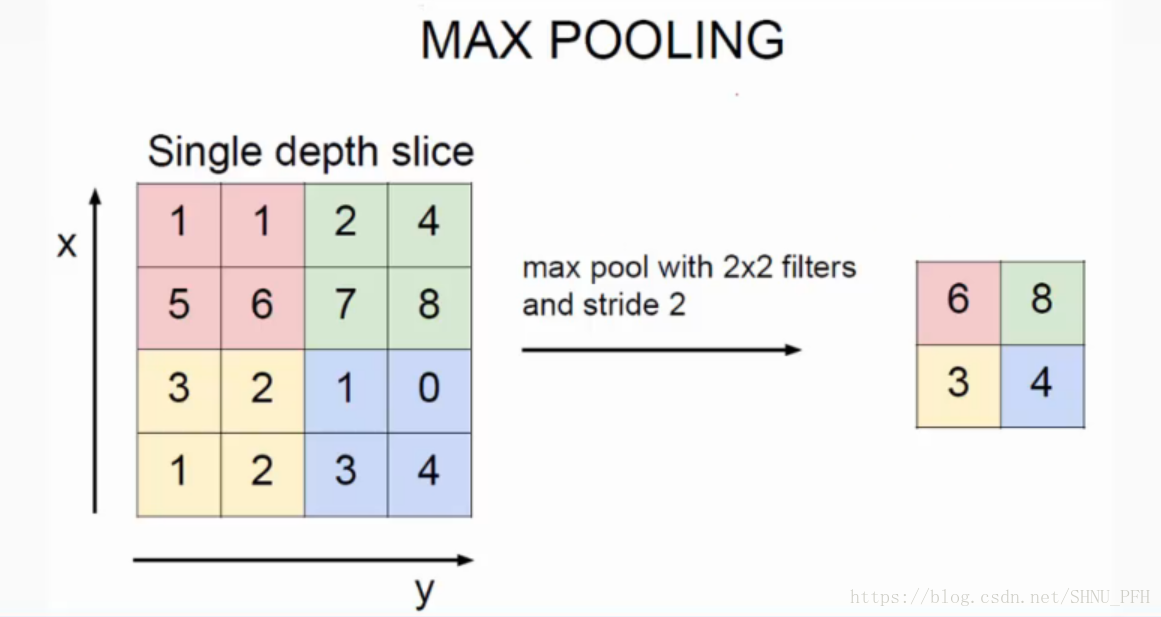
显然池化之后的特征图数据量是大大减小的,当然咱们的池子大小(图中为2*2)和步长(图中为2*2,分别为横竖两个方向)。
这样,经过了卷积层和池化层之后,还可以继续进行相同的卷积层和池化层操作,最后我们把输出由矩阵变成向量之后再进行一次全连接操作,然后经过非线性激活函数,最后再进行加权和计算和标准化等等操作,这些操作就像普通的MLP差不多了,目的就是输出最后简洁的结果,然后把实际结果和预期结果带入目标函数,最后对目标函数的输出进行优化最终达到训练模型的目的。
最后,在MLP中,每个隐含层输出是由输入层矩阵和权值矩阵直接相乘然后再代入激活函数得到,最终形式一般是一个矩阵,权值矩阵元素个数也就是参数数目非常多。而在CNN中,每个卷积核的参数数目比较少,和输入的矩阵也不是简单的相乘而是卷积的形式直接得到,卷积层中并没有激活函数的参与,而且由于每个卷积核都会产生一个特征图,最后整个卷积层的输出常常会是一个张量,而在卷积层和池化层之后的全连接层,才和普通的MLP一样,这主要是为了可以计算最后的模型输出和期望输出的差异,激活函数也在这一层被用到。
代码如下:
from tensorflow.examples.tutorials.mnist import input_data
mnist=input_data.read_data_sets("C:/Users/PengFeihu/Desktop/mnist",one_hot=True)
import tensorflow as tf
sess = tf.InteractiveSession()
#初始权重和偏置
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev = 0.1)
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
#定义卷积层和池化层函数
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides = [1,1,1,1], padding = 'SAME')
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize = [1,2,2,1], strides = [1,2,2,1], padding = 'SAME')
#将mnist数据集存放方式由1*784变回28*28
x = tf.placeholder(tf.float32, [None, 784])
y_ = tf.placeholder(tf.float32, [None,10])
x_image = tf.reshape(x, [-1,28,28,1])
#定义第一个卷积层
W_conv1 = weight_variable([5,5,1,32])
b_conv1 = bias_variable([32])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
#第二个卷积层
W_conv2 = weight_variable([5,5,32,64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
#全连接层,在全连接之前将h_pool2转换成一维向量
W_conv3 = weight_variable([7*7*64, 1024])
b_conv3 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat,W_conv3) + b_conv3)
#使用dropout避免模型过拟合
keep_prob = tf.placeholder(tf.float32)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
#最后链接一个softmax层,标准化输出结果
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_conv = tf.nn.softmax(tf.matmul(h_fc1_drop,W_fc2) + b_fc2)
#定义训练效果
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_*tf.log(y_conv),
reduction_indices=[1]))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
#准确率评价
correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
#开始训练
tf.global_variables_initializer().run()
for i in range(20000):
batch = mnist.train.next_batch(50)
if i%100 == 0:
train_accuracy = accuracy.eval(feed_dict = {x:batch[0], y_:batch[1],#?????????? x : batch[0}, y_:batch[1]是什么意思
keep_prob: 1.0})
print("step %d, train accuracy %g"%(i, train_accuracy))
train_step.run(feed_dict = {x: batch[0], y_: batch[1], keep_prob: 0.5})
#打印准确率
print("test accuracy %g"%accuracy.eval(feed_dict={
x:mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0
}))代码中的 feed_dict = {x:batch[0], y_: batch[1],keep_prob: 1.0}怎么拿来输出的准确率?