论文背景
论文全称:FullyConvolutionalNetworksforSemanticSegmentation
论文链接:https://arxiv.org/abs/1411.4038
论文发表时间:2015.3.8
卷积神经网络是高效可视化的模型,能产生特征的层次化结构,针对语义分割问题,本文提出了一个全卷积的神经网络,可以接受任何尺寸的输入,并且产生相应尺寸的输出。结合当前的神经网络(AlexNet, the VGG net, and GoogLeNet)进行微调来应用到分割问题中。
本文找到了 一个新型的神经网络结构:
- 深的、信息粗糙的层的语义信息
- 浅的、信息精细的层的表象信息
突出贡献
- 可以有任意尺寸的输入;
- 利用反卷积(上采样)还原特征映射为输入图片尺寸,进行精确预测;
- 采用跳跃结构,应用到多层信息,使预测更精确。
算法简介
卷积神经网络的应用很广:
- 整张图片的分类;
- 利用结构化的输出提高定位准确度。
– 边界框检测
– 部分/关键点预测
– 局部对应
本文的方法是在每一个像素点上从粗略的信息到精细的信息进行预测,之前的方法都是用神经网络进行语义分割,每一个像素点都被标签为与之相近的目标或区域的类别,但是这一方法有缺陷,会导致储存空间。
本文使用了一个端到端、像素到像素的训练方法,超越了其他最新的算法,训练FCN算法:
- 进行像素级的预测,在最后一层的feature map上对每一个像素点进行softmax求loss。
- 有监督的预训练
利用现有网络的全卷积神经网络版本预测来自任意大小输入的密集输出,学习和推断都是一次扫描一整张图片,由前向传播完成推断,反向传播完成学习。上采样用于像素级的预测,下采样的池化用于学习。
方法是高效的,同时渐进地、明显地排除了复杂东西的需要,这个方法没有使用前处理和后处理,包含超像素,特征区域,由任意区域或局部分类器进行的事后精炼。通过重新诠释分类器神经网络为全卷积神经网络并且从学习表示中进行微调,从而将分类问题转换为密集预测。与之相反,之前的算法没有应用带监督的预训练的小型卷积神经网络。
语义分割面对语义与定位之间的内在张力:
- 全局信息解决目标是什么问题; 浅层卷积结果
- 局部信息解决目标在哪里。深层卷积结果
深度特征分层联结编码一个局部到局部金字塔的定位于语义。本文定义了一个新型的跳跃结构,结合了深的、粗糙的语义信息以及浅的、信息精细的层的表象信息。
算法详解
FCN神经网络结构
传统的分类神经网络有固定尺寸的输入,并且会产生非空间输出,全连接层有固定维度,并抛弃了空间坐标。

FCN将最后的三个全连接层换成11的卷积层,最后会得到一个10001*1的feature map,然后上采样得到heatmap。

FCN接受任意尺寸的输入,然后通过反卷积层对最后一层的卷积层的feature map进行上采样,使它还原到与输入图片尺寸,从而对每一个像素都产生一个预测,同时还保留了输入图片的空间信息,最后在特征图上对每一个像素点进行分类,逐像素地用softmax分类计算损失,相当于每个像素对应一个训练样本。
感受野计算
检测任务可别分为识别,检测,语义分割与实例分割,在混合动力候选分类任务,现在重新构造并且微调分类器来直接密集地进行语义分割预测。
卷积神经网络每一层的数据都是3维的矩阵,尺寸为h * w * d,h与w是空间维度,d是特征或通道维度,第一层为图片,尺寸为h * w,d个颜色通道。在更高层的定位对应于与通道路径联系的图片上的定位的是他们感受野。
卷积神经网络用于平移不变性,他们的基本元素作用在输入图片的区域,仅仅依赖相对空间坐标。
上一层有一个向量 xij是定位在坐标(i ,j ),
针对下一层,yij的计算:
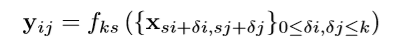
k:卷积核尺寸;
s:下采样步长;
f:层特征,一个矩阵运算(卷积,池化)。
多层之间的坐标转换:
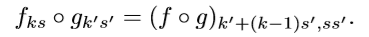
损失函数:
最后一层得到的不是一个向量。而是一个spatial map。
损失函数是最后一层的 spatial map上的 pixel 的 loss之和,在每一个 pixel 使用 softmax loss 。
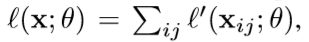
使用随机梯度下降在整张图片上计算损失。以最后一层的感受野作为mini-batch。
反卷积(deconvolution)
也被称为上采样(upsampling)过程,就是卷积的逆过程。
使用卷积核对每一个像素点进行乘法操作,然后根据对应位置、步长、pad进行尺寸还原,重叠部分进行加和,最终得到上采样之后的特征图。


跳跃结构(skip architecture)
对第五层池化后的结果进行放大32倍的反卷积得到输入图片的尺寸,但这样得到的结构仍不够准确,有一些细节无法恢复,于是对第四层和第三层的输出分别进行放大16倍和8倍的反卷积,将得到的结果求和,使得最后得到的结果更加准确,这样就兼顾了local与global信息。


训练
训练过程
整体训练可被分为4个阶段:
第一阶段:将经典的用于分类的神经网络的全连接层改为卷积1*1的卷积层
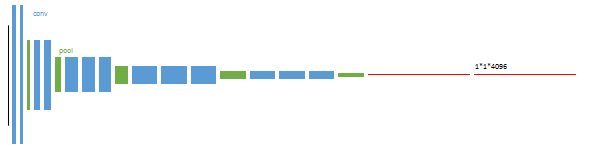
第二阶段:利用最后层的特征映射预测候选区域,之后上采样为输入图片尺寸,
反卷积(橙色)的步长为32,这个网络称为FCN-32s。
这一阶段使用单GPU训练约需3天。

升采样分为两次完成(橙色×2)。
在第二次升采样前,把第4个pooling层(绿色)的预测结果(蓝色)融合进来。使用跳级结构提升精确性。
第二次反卷积步长为16,这个网络称为FCN-16s。
这一阶段使用单GPU训练约需1天。

升采样分为三次完成(橙色×3)。
进一步融合了第3个pooling层的预测结果。
第三次反卷积步长为8,记为FCN-8s。
这一阶段使用单GPU训练约需1天。

参数
mini-batch:20张图片
learning rate:0.001
初始化:
分类网络之外的卷积层参数初始化为0。
反卷积参数初始化为bilinear插值。最后一层反卷积固定位bilinear插值不做学习。