版权声明:本文为博主原创文章 http://blog.csdn.net/su20145104009 https://blog.csdn.net/su20145104009/article/details/85778303
赫拉
大数据平台,随着业务发展,每天承载着成千上万的ETL任务调度,这些任务集中在hive,shell脚本调度。怎么样让大量的ETL任务准确的完成调度而不出现问题,甚至在任务调度执行中出现错误的情况下,任务能够完成自我恢复甚至执行错误告警与完整的日志查询。hera任务调度系统就是在这种背景下衍生的一款分布式调度系统。随着hera集群动态扩展,可以承载成千上万的任务调度。它是一款原生的分布式任务调度,可以快速的添加部署wokrer节点,动态扩展集群规模。支持shell,hive,spark脚本调度,可以动态的扩展支持python等服务器端脚本调度。
项目地址:[email protected]:scx_white/hera.git
版本介绍
在hera系统中支持历史版本的数据重跑。
每一个任务都会生成版本,版本时间根据cron表达式来产生。其中版本在脚本中没有使用内置变量时无用。
版本号的生成规则为:yyyyMMddHHmm000000 + 任务ID号 ,其实日期的替换就是根据版本的前12位来识别的。
版本的使用
在hera中我们内置了一些时间变量。其原理根据velocity模版进行变量替换。所有的时间变量都在HeraDateTool类中,有需要自定义需求的可以自行增加。
比如我写了一个脚本,内容如下
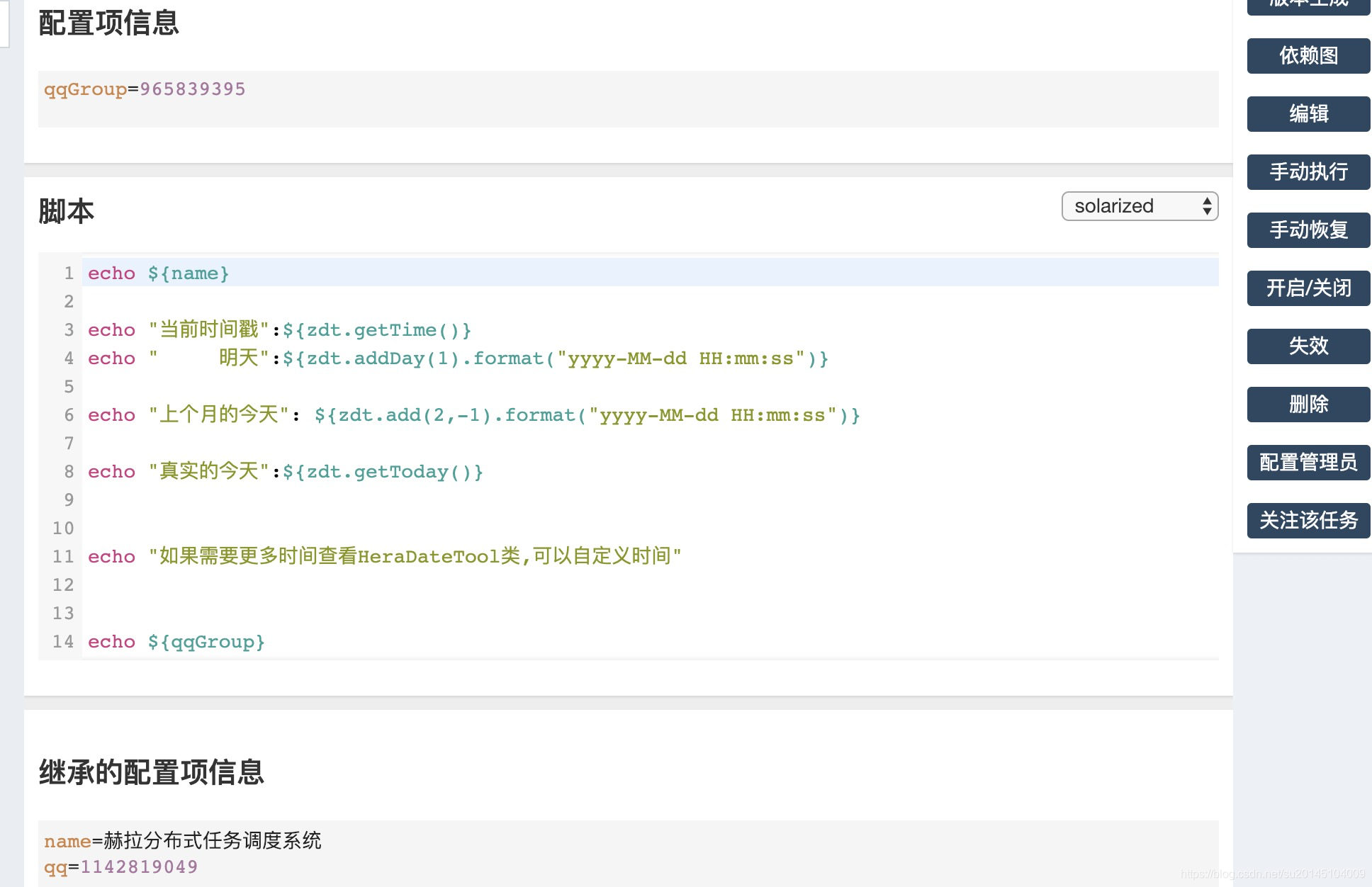
点击手动执行,执行时选择一个版本。
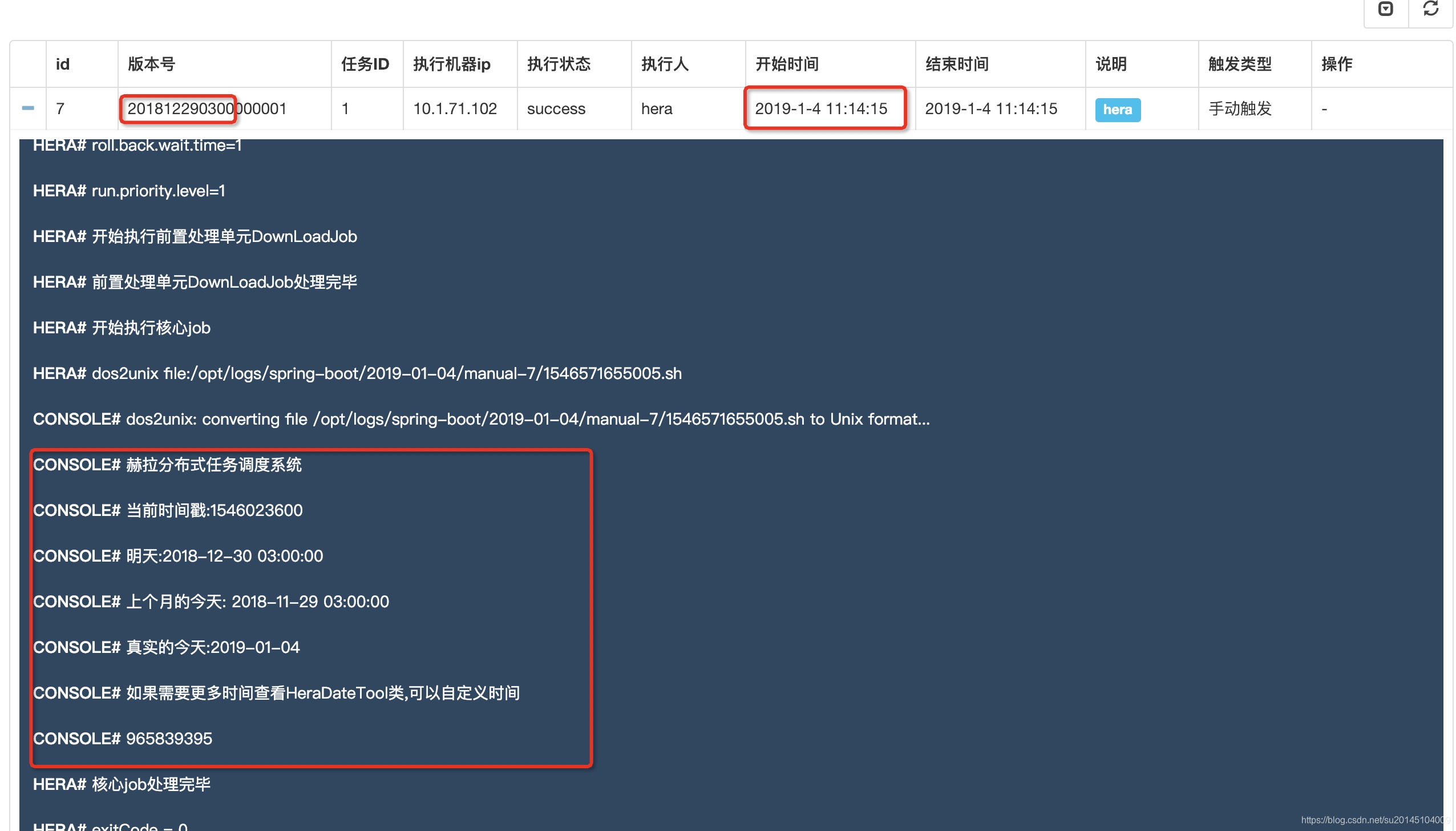
通过执行日志信息我们可以发现使用的版本为:201812290300000001 然后执行的时间为2019年1月4日,脚本输出的时间是以脚本时间版本时间为准的。通过选择不同时间的版本,我们可以在跑数据时使用hera内置时间变量,来进行拉取指定的时间的数据。
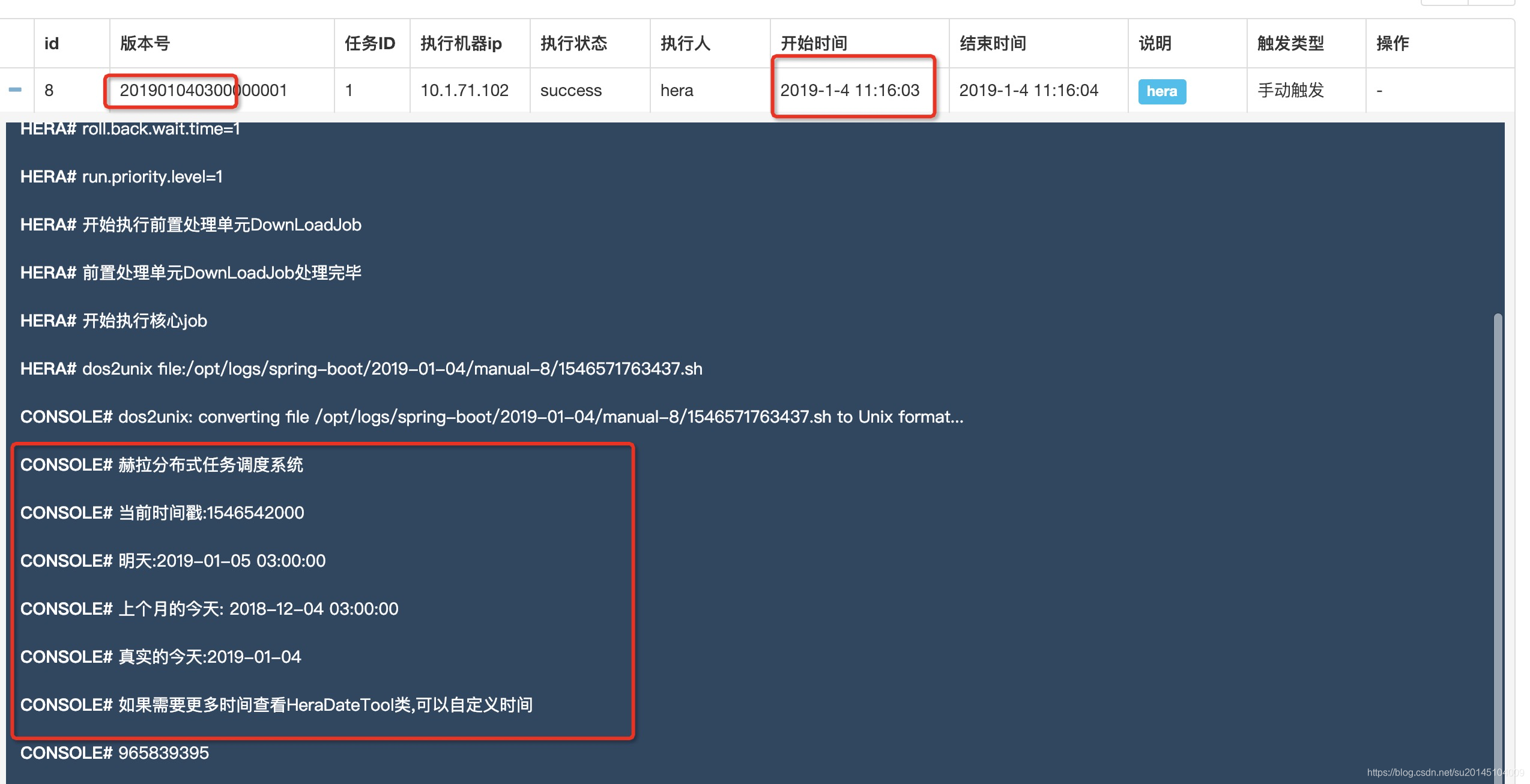
例子同上。
加入群聊

个人微信(失效加我拉你进去)