分布式任务调度是非常常见的一种应用场景,一般对可用性和性能要求不高的任务,采用单点即可,例如linux的crontab,spring的quarz,但是如果要求部署多个节点,达到高可用的效果,上面的方案就不适用了。
实际上任务调度的实现有两种情况,第一种是通过mq来实现,mq做好了数据切分,负载均衡的效果,本文说的是另一种情况。
一、不重复
如果只达到这个要求,有很多方法,假设任务处理的是一张表中的数据,那可以根据某个字段取模达到不重复的效果。
二、不遗漏
如果用上面的方案解决了重复的问题,有一个节点挂掉,需要其他节点接管挂掉节点的任务,这就要求分布式任务调度必须有指挥中心,否则很容易造成重复或者遗漏。
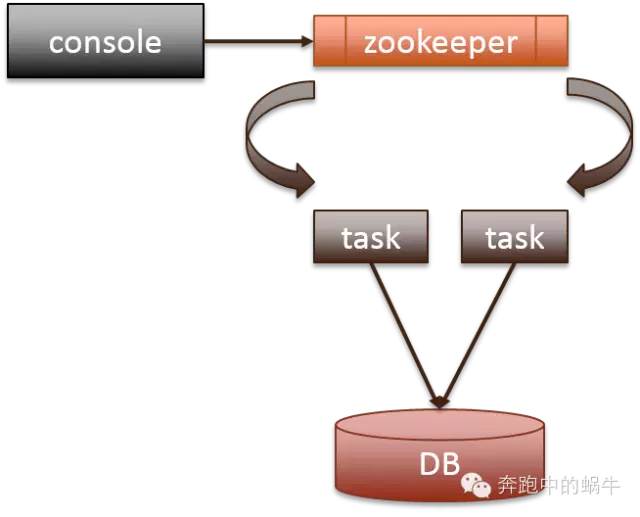
上图是tbschedule的架构图,基本满足了分布式任务调度的要求,zookeeper有两个功能,一个是配置数据存储,另一个是作为调度中心,管理界面直接连接zookeeper取得配置信息,并且修改配置,通过zookeeper通知任务修改配置项。
要求不高的话可以直接拿来用,虽然文档少,但是代码量很少,可以直接通过读代码了解功能。
tbschedule已经满足了大多数需求,代码写的也非常优秀,但是有几个地方是可以改进的,
1、前面提到的,一般情况下,我们是不需要多个节点同时工作的,只要有一个节点工作,挂掉其他节点能接替就可以了。因为取数据通常不是性能瓶颈,瓶颈在处理数据,多个节点的目的无非是为了高可用。如果通过sql取模进行分片,sql的性能非常低,走不了索引。如果表数据已经做了水平拆分,那可以直接根据数据源切分任务项。
2、tbschedule是把所有任务都处理完才算结束,但是有些场景要求只执行一次,哪怕还有任务要处理,tbschedule需要增加一个配置项;
3、执行时间修改必须在每个执行周期后才能生效,这个经常在调试的时候出现麻烦,这样做确实是最简单的做法,避免了很多问题,但是如果开发人员要配置任务每分钟执行一次,结果写错了配置成每天执行一次,就完美的落入陷阱,等半天也看不到执行,还以为配置错了,重启可以解决;
4、没有负载均衡效果,tbschedule认为每台机器的配置都是一样的,就算配置一样,数据项不一样也容易引起其中一个节点压力特别大。需要根据机器的负载情况、程序的繁忙情况做一个加权平均来做负载。
更多精彩内容,请关注本人公众号