克隆hera
暂时还未开源 后面补上。
创建表
当使用git把hera克隆到本地之后,首先在hera/hera-admin/resources目录下找到hera.sql文件,在自己的数据库中新建这些必要的表,并插入初始化的数据。
此时可以在hera/hera-admin/resources目录下找到application.yml文件。在文件里修改数据源hera的数据源(修改druid.datasource下的配置)即可进行下面的操作。
spring:
profiles:
active: @env@ ##当前环境 打包时通过-P来指定
http:
multipart:
max-file-size: 100Mb #允许上传文件的最大大小
max-request-size: 100Mb #允许上传文件的最大大小
freemarker:
allow-request-override: true
cache: false
check-template-location: true
charset: utf-8
content-type: text/html
expose-request-attributes: false
expose-session-attributes: false
expose-spring-macro-helpers: false
suffix: .ftl
template-loader-path: classpath:/templates/
request-context-attribute: request
druid:
datasource:
username: root #数据库用户名
password: XIAOSUDA #数据库密码
driver-class-name: com.mysql.jdbc.Driver #数据库驱动
url: jdbc:mysql://localhost:3306/hera?characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&autoReconnect=true&allowMultiQueries=true
initial-size: 5 #初始化连接池数量
min-idle: 1 #最小生存连接数
max-active: 16 #最大连接池数量
max-wait: 5000 #获取连接时最大等待时间,单位毫秒。配置了maxWait之后,缺省启用公平锁,并发效率会有所下降,如果需要可以通过配置useUnfairLock属性为true使用非公平锁。
time-between-connect-error-millis: 60000 # Destroy线程会检测连接的间隔时间,如果连接空闲时间大于等于minEvictableIdleTimeMillis则关闭物理连接,单位是毫秒
min-evictable-idle-time-millis: 300000 # 连接保持空闲而不被驱逐的最长时间,单位是毫秒
test-while-idle: true #申请连接的时候,如果检测到连接空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效
test-on-borrow: true #申请连接时执行validationQuery检测连接是否有效
test-on-return: false # 归还连接时执行validationQuery检测连接是否有效
connection-init-sqls: set names utf8mb4
validation-query: select 1 #用来检测连接是否有效的sql,要求是一个查询语句。如果validationQuery为null,testOnBorrow、testOnReturn、testWhileIdle都不会其作用。
validation-query-timeout: 1 #单位:秒,检测连接是否有效的超时时间。底层调用jdbc Statement对象的void setQueryTimeout(int seconds)方法
log-abandoned: true
stat-mergeSql: true
filters: stat,wall,log4j
connection-properties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000
server:
port: 8080
context-path: /hera
clean:
path: ${server.context-path}
#hera全局配置
hera:
defaultWorkerGroup : 1 #默认worker的host组id
preemptionMasterGroup : 1 #抢占master的host组id
excludeFile: jar;war
maxMemRate : 0.80 #已使用内存占总内存的最大比例,默认0.80。当worker内存使用达到此值时将不会再向此work发任务
maxCpuLoadPerCore : 1.0 #cpu load per core等于最近1分钟系统的平均cpu负载÷cpu核心数量,默认1.0。当worker平均负载使用达到此值时将不会再向此work发任务
scanRate : 1000 #任务队列扫描频率(毫秒)
systemMemUsed : 4000 # 系统占用内存
perTaskUseMem : 500 # 假设每个任务使用内存500M
requestTimeout: 10000 # 异步请求超时时间
channelTimeout: 1000 # netty请求超时时间
heartBeat : 3 # 心跳传递时间频率
downloadDir : /opt/logs/spring-boot
hdfsLibPath : /hera/hdfs-upload-dir #此处必须是hdfs路径,所有的上传附件都会存放在下面路径上
schedule-group : online
maxParallelNum: 2000 #master 允许的最大并行任务 当大于此数值 将会放在阻塞队列中
connectPort : 9887 #netty通信的端口
admin: biadmin # admin用户
taskTimeout: 12 #单个任务执行的最大时间 单位:小时
env: @env@
# 发送配置邮件的发送者
mail:
host: smtp.mxhichina.com
protocol: smtp
port: 465
user: xxx
password: xxx
logging:
config: classpath:logback-spring.xml
path: /opt/logs/spring-boot
level:
root: INFO
org.springframework: ERROR
com.dfire.common.mapper: ERROR
mybatis:
configuration:
mapUnderscoreToCamelCase: true
#spark 配置
spark :
address : jdbc:hive2://localhost:10000
driver : org.apache.hive.jdbc.HiveDriver
username : root
password : root
master : --master yarn
driver-memory : --driver-memory 1g
driver-cores : --driver-cores 1
executor-memory : -- executor-memory 1g
executor-cores : --executor-cores 1
---
## 开发环境
spring:
profiles: dev
logging:
level:
com.dfire.logs.ScheduleLog: ERROR
com.dfire.logs.HeartLog: ERROR
---
## 日常环境 通常与开发环境一致
spring:
profiles: daily
---
## 预发环境
spring:
profiles: pre
druid:
datasource:
url: jdbc:mysql://localhost:3306/lineage?characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull&autoReconnect=true&allowMultiQueries=true
username: root
password: root
#spark 配置
spark :
address : jdbc:hive2://localhost:10000 #spark地址
master : --master yarn
driver-memory : --driver-memory 2g
driver-cores : --driver-cores 1
executor-memory : -- executor-memory 2g
executor-cores : --executor-cores 1
---
## 正式环境
spring:
profiles: publish
druid:
datasource:
url: jdbc:mysql://localhost:3306/lineage?characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull&autoReconnect=true&allowMultiQueries=true
username: root
password: root
#spark 配置
spark :
address : jdbc:hive2://localhost:10000
master : --master yarn
driver-memory : --driver-memory 2g
driver-cores : --driver-cores 1
executor-memory : -- executor-memory 2g
executor-cores : --executor-cores 1
打包部署
当上面的操作完成后,即可使用maven的打包命令进行打包
mvn clean package -Dmaven.test.skip -Pdev
打包后可以进入hera-admin/target目录下查看打包后的hera.jar 。此时可以简单使用java -server -Xms4G -Xmx4G -Xmn2G -jar hera.jar启动项目,此时即可在浏览器中输入
localhost:8080/hera
即进入登录界面,账号为hera 密码为biadmin,点击登录即进入系统。
顺便附上我的启动脚本
#!/bin/sh
JAVA_OPTS="-server -Xms4G -Xmx4G -Xmn2G -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+CMSParallelRemarkEnabled -XX:CMSFullGCsBeforeCompaction=5 -XX:+CMSParallelInitialMarkEnabled -XX:CMSInitiatingOccupancyFraction=80 -verbose:gc -XX:+PrintGCTimeStamps -XX:+PrintGCDetails -Xloggc:/opt/logs/spring-boot/gc.log -XX:MetaspaceSize=128m -XX:+UseCMSCompactAtFullCollection -XX:MaxMetaspaceSize=128m -XX:+CMSPermGenSweepingEnabled -XX:+CMSClassUnloadingEnabled -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/opt/logs/spring-boot/dump"
log_dir="/opt/logs/spring-boot"
log_file="/opt/logs/spring-boot/all.log"
jar_file="/opt/app/spring-boot/hera.jar"
#日志文件夹不存在,则创建
if [ ! -d "${log_dir}" ]; then
echo "创建日志目录:${log_dir}"
mkdir -p "${log_dir}"
echo "创建日志目录完成:${log_dir}"
fi
#父目录下jar文件存在
if [ -f "${jar_file}" ]; then
#启动jar包 错误输出的error 标准输出的log
nohup java $JAVA_OPTS -jar ${jar_file} 1>"${log_file}" 2>"${log_dir}"/error.log &
echo "启动完成"
exit 0
else
echo -e "\033[31m${jar_file}文件不存在!\033[0m"
exit 1
fi
测试
此时就登录上了。下面需要做的是在worker管理这里添加执行任务的机器IP,然后选择一个机器组(组的概念:对于不同的worker而言环境可能不同,可能有的用来执行spark任务,有的用来执行hadoop任务,有的只是开发等等。当创建任务的时候根据任务类型选择一个组,要执行任务的时候会发送到相应的组的机器上执行任务)。
对于执行work的机器ip调试时可以是master,生产环境建议不要让master执行任务。如果要执行map-reduce或者spark任务,要保证你的work具有这些集群的客户端。
那么我们就在work管理页面增加要执行的work地址以及机器组。
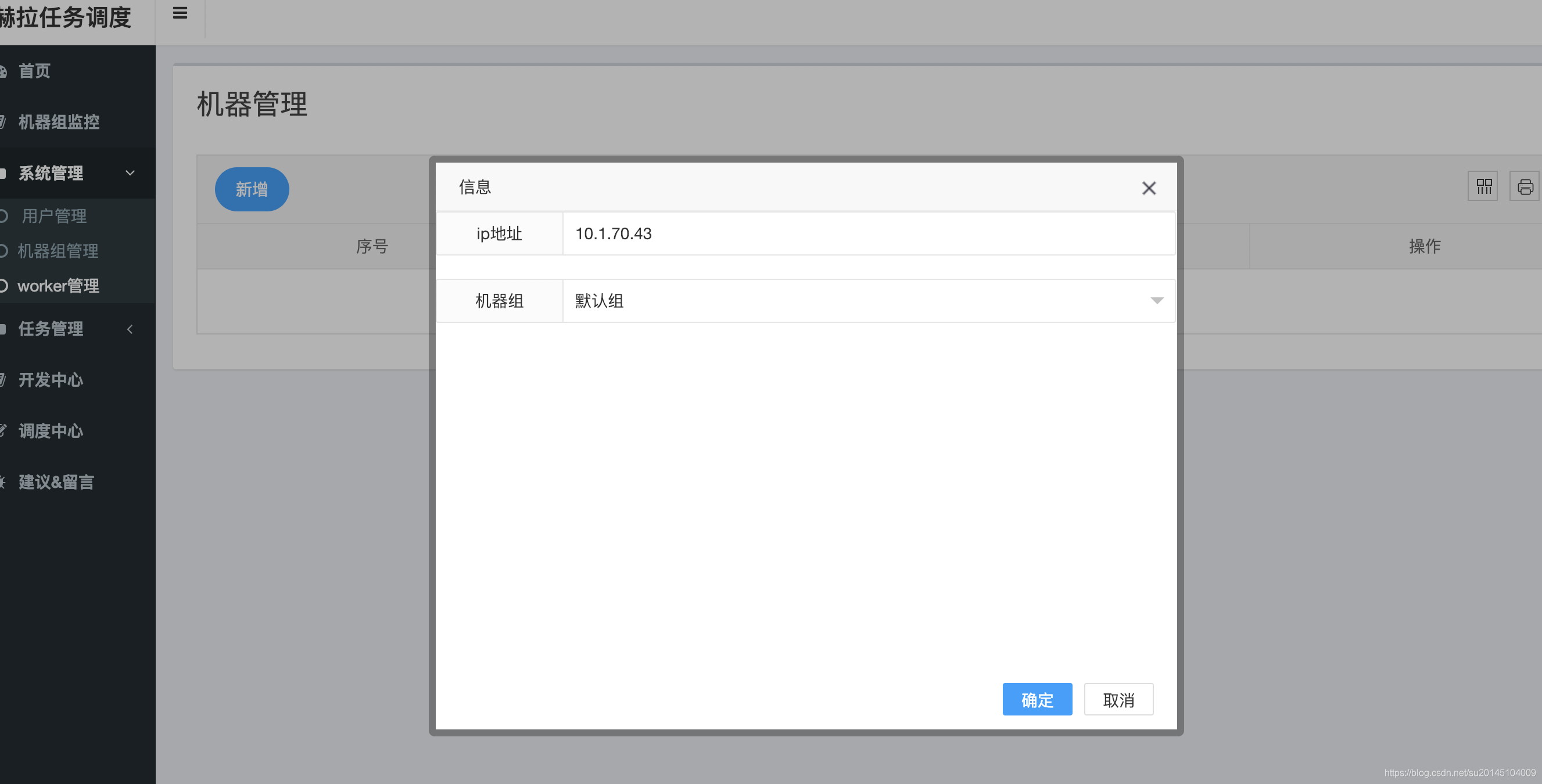
此时有30分钟的缓冲时间,master才会检测到该work加入。为了测试,此时我们可以通过重启master来立刻使该work加入执行组(后面会增加一键刷新work信息)。
重启后我们可以进入调度中心 ,在搜索栏里搜索1,然后按回车
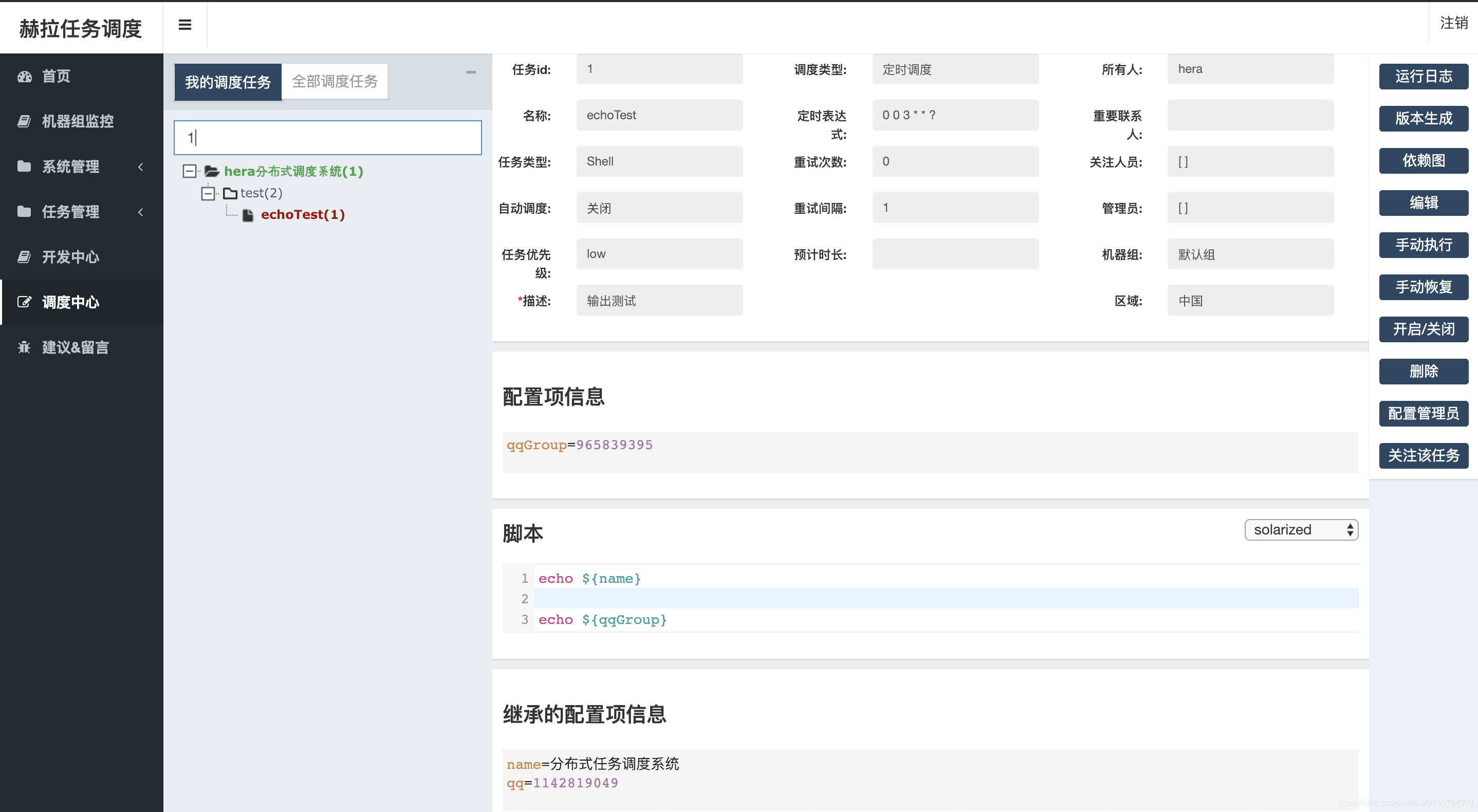
会发现一个echoTest任务 ,此时我们还不能执行任务,因为我们的所有任务的执行者登录用户。比如此刻我使用hera登录的,那么此时一定要保证你的work机器上有hera这个用户。
否则执行任务会出现sudo: unknown user: hera 异常。
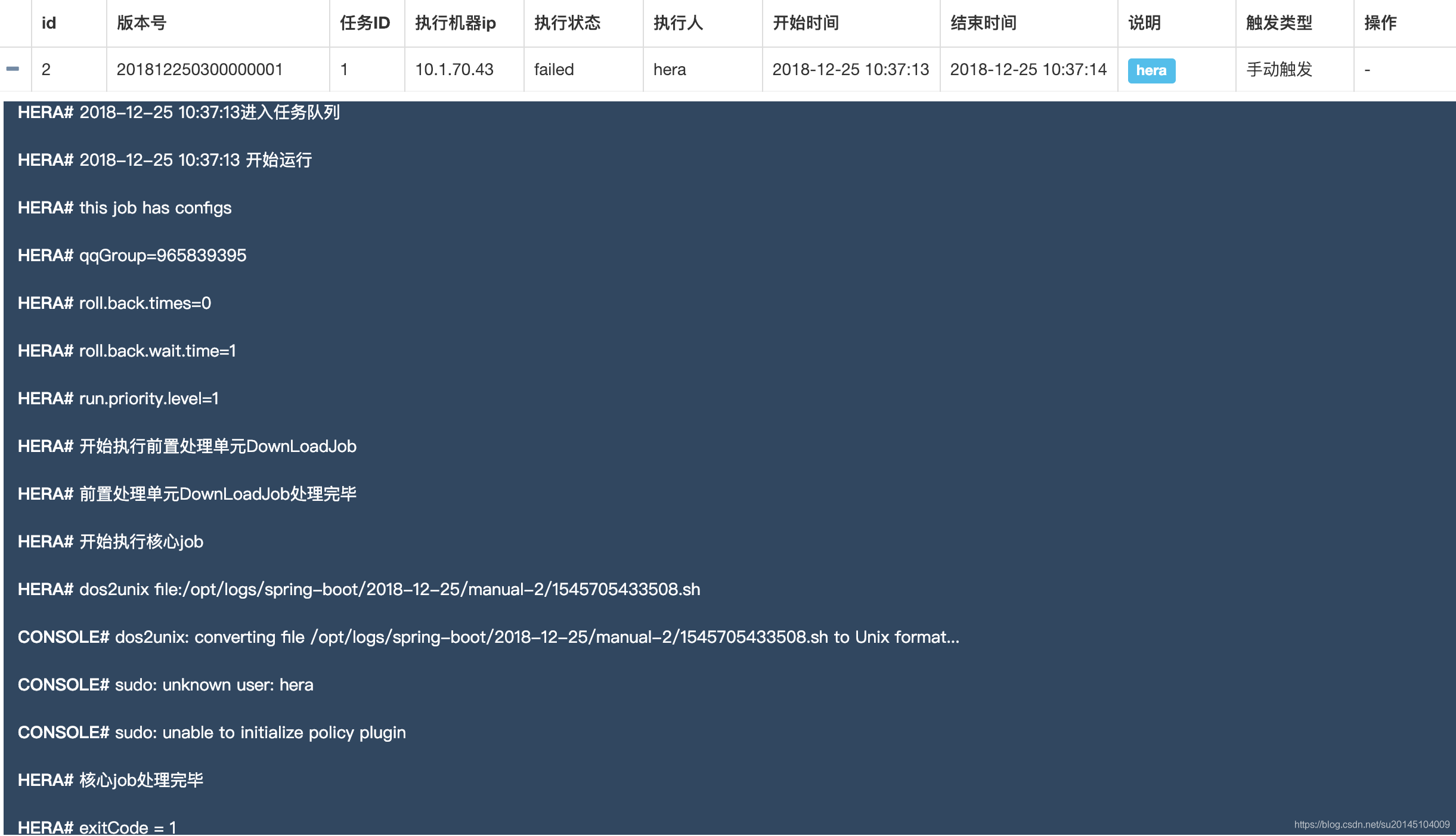
此时可以向我们填写的work机器上增加hera用户。
useradd hera
如果是mac系统 那么可以使用以下命令创建hera用户
sudo dscl . -create /Users/hera
sudo dscl . -create /Users/hera UserShell /bin/bash
sudo dscl . -create /Users/hera RealName "hera分布式任务调度"
sudo dscl . -create /Users/hera UniqueID "1024"
sudo dscl . -create /Users/hera PrimaryGroupID 80
sudo dscl . -create /Users/hera NFSHomeDirectory /Users/hera
此时点击手动执行->选择版本->执行。此时该任务会运行,点击右上角的查看日志,可以看到任务的执行记录。
此时如果任务执行失败,error日志内容为
sudo: no tty present and no askpass program specified
那么此时要使你启动hera项目的用户具有sudo -u hera的权限(无须输入root密码,即可执行sudo -u hera echo 1 ,具体可以在sudo visudo中配置)。
比如我启动hera的用户是wyr
那么首先在终端执行sudo visudo命令,此时会进入文本编辑
然后在后面追加一行
wyr ALL=(ALL) NOPASSWD:ALL
如下图:

这样就会在切换用户的时候无须输入密码。当然如果你使用的是root用户启动,即可跳过这段。
如果一切配置完成,那么即可看到输出任务执行成功的日志。
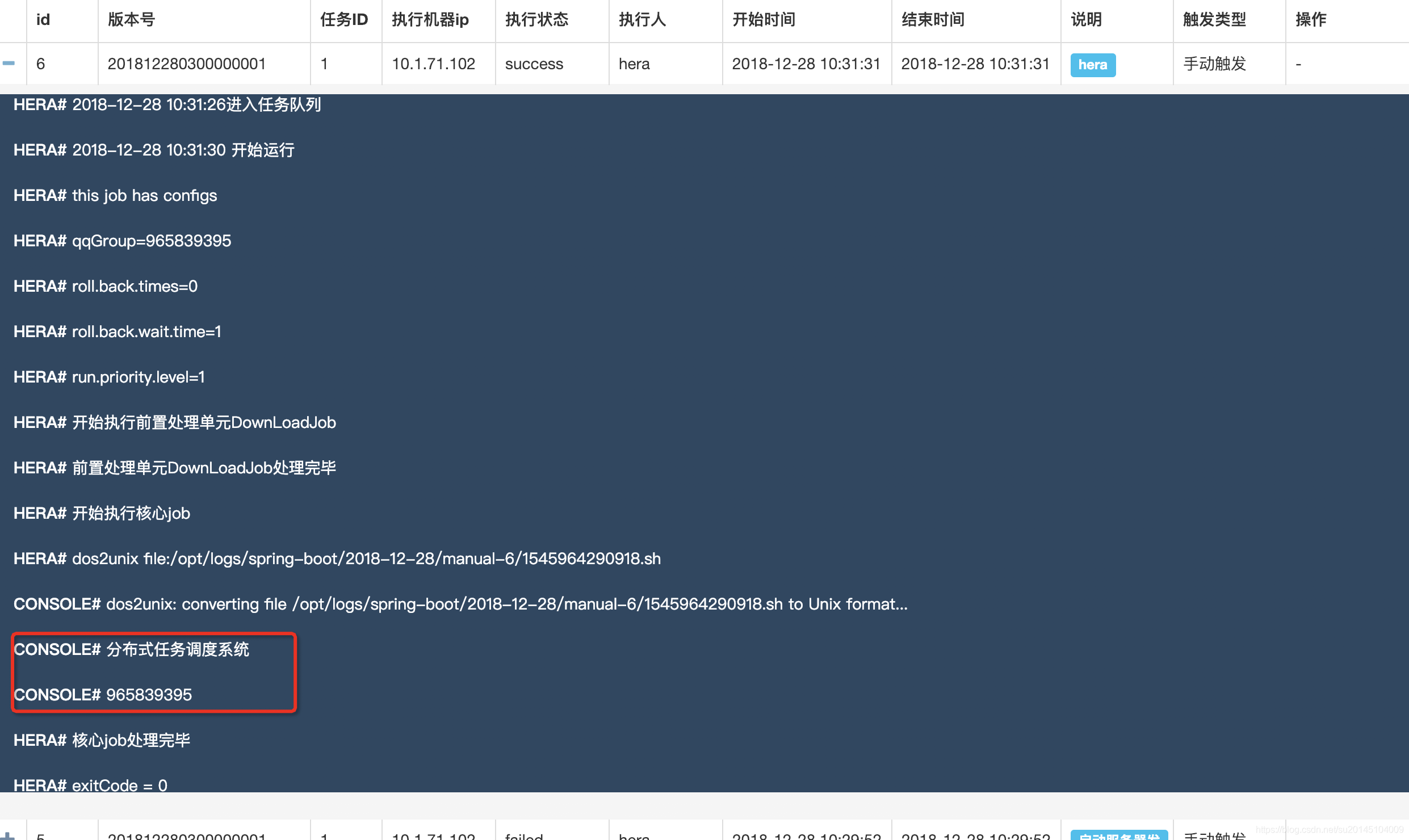
至此 已经完成了 任务的手动执行。