为什么要数据归一化和归一化方法
转自:https://zhuanlan.zhihu.com/p/27627299
在喂给机器学习模型的数据中,对数据要进行归一化的处理。
为什么要进行归一化处理,下面从寻找最优解这个角度给出自己的看法。
例子
假定为预测房价的例子,自变量为面积,房间数两个,因变量为房价。
那么可以得到的公式为:
其中代表房间数,代表变量前面的系数。
其中代表面积,代表变量前面的系数。
首先我们祭出两张图代表数据是否均一化的最优解寻解过程。
未归一化:
归一化之后
为什么会出现上述两个图,并且它们分别代表什么意思。
我们在寻找最优解的过程也就是在使得损失函数值最小的theta1,theta2。
上述两幅图代码的是损失函数的等高线。
我们很容易看出,当数据没有归一化的时候,面积数的范围可以从0~1000,房间数的范围一般为0~10,可以看出面积数的取值范围远大于房间数。
影响
这样造成的影响就是在画损失函数的时候,
数据没有归一化的表达式,可以为:
造成图像的等高线为类似椭圆形状,最优解的寻优过程就是像下图所示:
而数据归一化之后,损失函数的表达式可以表示为:
其中变量的前面系数几乎一样,则图像的等高线为类似圆形形状,最优解的寻优过程像下图所示:
从上可以看出,数据归一化后,最优解的寻优过程明显会变得平缓,更容易正确的收敛到最优解。
这也是数据为什么要归一化的一个原因。
作用:对于不同的特征向量,比如年龄、购买量、购买额,在数值的量纲上相差十倍或者百千倍。如果不归一化处理,就不容易进行比较、求距离,模型参数和正确度精确度就会受影响,甚至得不出正确的结果。
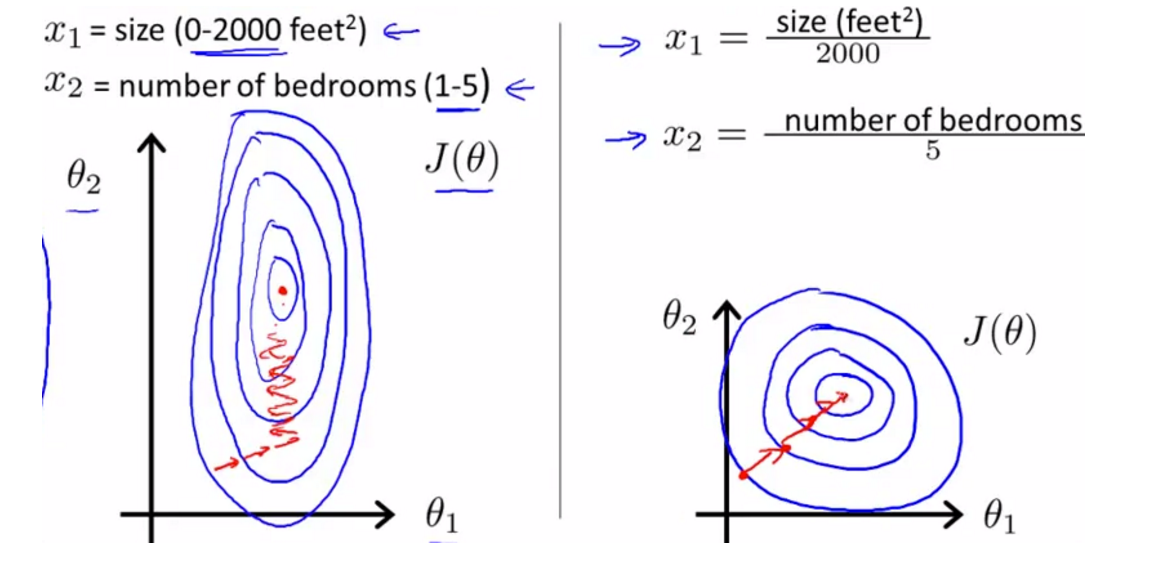
举个例子:用梯度下降法求解最优解时,下图展示没有归一化和归一化处理两种情况下的求解过程。
左图表示没有归一化的求解过程;右图表示有归一化的处理过程。
X1、X2表示特征向量,数值区间分别为[0,2000],[1,5].
图中蓝线为等高线,红色为梯度下降求解线,中心红点为最优解。
左图的Z字形为未归一化处理的梯度下降求解过程。
右图的1字形为归一化处理后的梯度下降求解过程。
对比可知,归一化处理后,等高线更圆,求解得到的梯度方向更能直指圆心,收敛速度更快,效率更高。
如果不归一化,不但收敛速度慢,很可能找不到最优解。
归一化除了能够提高求解速度,还可能提高计算精度。
比如:计算样本距离时,如果特征向量取值范围相差很大,如果不进行归一化处理,则值范围更大的特征向量对距离的影响更大,实际情况是,取值范围更小的特征向量对距离影响更大,这样的话,精度就会收到影响。
归一化常用方法
1、线性归一化函数(Min-Max Scaling)
x’ = (x-min(x))/(max(x)-min(x))
把原始数据取值转换到[0,1]之间。
实际使用时,不同样本集得到的max/min可能不同,造成归一化结果不稳定,从而使模型后续使用也不稳定。
可以经验值来代替max/min,比如人的年龄,max=100,min=0。避免不同样本集max/min的不同造成的模型偏差。
2、0均值标准化(Z-score standardization)
x’ = (x-u)/theta.
u为样本均值,theta为样本方差。
转换后的数值服从均值为0,方差为1的高斯正态分布。
应用场景:原始数据(近似)高斯分布。否则归一化后的效果会很差。
3、非线性归一化(Nonlinear Scaling)
包括对数log,指数e,正切等。
应用场景:数据分化比较大,有些很大,有些很小,可能用此方法将数值映射到一个比较小的范围进行处理。log(V,2),log(V,10).
小结:
1、对于需要求距离的分类、聚类、相似度、协方差等,数据符合或者近似符合高斯正态分布时,PCA降维时,常用0均值标准化,可以得到较好的效果。
2、对于其他情况,如果数据分化不是很大,可以用线性归一化处理。
3、如果数据分化很大,可以用非线性归一化处理。
参考文章
1、http://blog.csdn.net/zbc1090549839/article/details/44103801
2、http://www.open-open.com/lib/view/open1429697131932.html