这一节开始我们来开始做这个项目, 至于项目的新建还有文件结构, 我就不做详细介绍了,这些步骤在这个博客都有:http://www.cnblogs.com/derek1184405959/p/8733578.html 我呢,从来就不喜欢照搬别人的做, 反而喜欢多问几个为什么, 为什么要这么做? 因为我在之前遇到学习上的一个问题, 就是我看着老师讲的视频来就很会, 但是一旦脱离老师的视频, 要自己开发呢? 又不会了, 这是因为什么? 归根到底是因为我们没有明白为什么要那么做, 为什么要那么设计, 做项目的过程中要把自己当做项目负责人去做, 这样你才会学的更多, 上面提到的那个博客, 已经做的很好, 很详细了, 我主要是解释为什么这么做. 那么开始做吧.
三. models设计
3.1 项目初始化
(1)虚拟环境下安装

解释以下几点:
1. 为什么要使用虚拟环境? 因为django的版本各个版本有所不同, 而且django的插件也比较挑剔, 对有些版本适合, 对有些版本不适合, 所以我们可以建一个虚拟环境, 在虚拟环境下安装你想要的版本, 这样就不会因为版本的差异而产生bug了.
2.解释一下这几个插件是什么作用的, djangorestframework和django是项目的精髓, 这就不用说了吧, 然后即使markdown, 对于程序员来说, 这都不陌生吧, 这是一款编辑器, 因为我们要写api, api是要给自己或者别人用的, 那么自然而然少不了生成api文档吧, 用这个插件可以很方便的生产api说明.django-filter是django的依赖包, 一定要安装的, 接着是pillow是图片处理的插件, pymysql是python先mysql的库.
(2) 创建项目
按照博客来
(3)MYsql的配置
在setting.py文件改DATABASES为下面的内容, 其中数据库名字, 账号, 密码, ip, 端口(一般不用改)这些信息按照自己的数据库信息修改, 不要盲目照搬照抄.注意下面最后一句, 不要写成'OPTIONS':{'init_command': 'SET storage_engine=INNODB'} 不然会报错, 在图下解释原因
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'mxshop', #数据库名字
'USER': 'root', #账号
'PASSWORD': '123456', #密码
'HOST': '127.0.0.1', #IP
'PORT': '3306', #端口
#这里引擎用innodb(默认myisam)
#因为后面第三方登录时,要求引擎为INNODB
# 'OPTIONS':{'init_command': 'SET storage_engine=INNODB'}, #这样设置会报错,改为
"OPTIONS":{"init_command":"SET default_storage_engine=INNODB;"}
}
}原因是mysql版本间的不兼容: 上面那条语句适用了低版本的mysql, 下面那条适用于新版的mysql, 至于什么是新版本,什么是高版本, 在这不好做定论, 可以先试上面那个语句, 要是运行出错, 就用下面那条语句.
(4)项目目录结构

这里有个python import的小知识:
Python import module 的搜索路径由sys.path指定,实质为一个列表,列表索引先后决定搜索优先级。
模块要处于Python搜索路径中的目录里才能被导入,但我们不喜欢维护一个永久性的大目录,因为其他所有的Python脚本和应用程序导入模块的时候性能都会被拖累。本节代码动态地在该路径中添加了一个"目录",当然前提是此目录存在而且此前不在sys.path中。sys.path是个列表,所以在末尾添加目录是很容易的,用sys.path.append就行了。当这个append执行完之后,新目录即时起效,以后的每次import操作都可能会检查这个目录。如同解决方案所示,可以选择用sys.path.insert(0,…,这样新添加的目录会优先于其他目录被import检查。即使sys.path中存在重复,或者一个不存在的目录被不小心添加进来,也没什么大不了,Python的import语句非常聪明,它会自己应付这类问题。但是,如果每次import时都发生这种错误(比如,重复的不成功搜索,操作系统提示的需要进一步处理的错误),我们会被迫付出一点小小的性能代价。为了避免这种无谓的开销,本节代码在向sys.path添加内容时非常谨慎,绝不加入不存在的目录或者重复的目录。程序向sys.path添加的目录只会在此程序的生命周期之内有效,其他所有的对sys.path的动态操作也是如此。
sys.path.insert(1, path),定义搜索路径的优先顺序,序号从0开始,表示最大优先级,sys.path.insert()加入的是临时搜索路径,程序退出后失效。使用sys.path.append()方法可以临时添加搜索路径,方便更简洁的import其他包和模块。这种方法导入的路径会在python程序退出后失效。加入上面那三条语句是为了更好的import和维护, 这是我的见解, 不知道是不是这样.
3.2 user modules的设计
设计models的方法: 分析页面结构, 看看需要几个数据表, 在分析数据表的字段, 其实我认为这就是我们的分类和从组的能力,
设计数据库是一门很深的学问, 我也在慢慢在学习. 看我怎么设计这些models的,
因为前段时间我还运行这vue前端项目的, 不过现在后台服务器挂了, 不能运行了, 如图所示:
我想想办法吧.
这样吧, 服务器挂了, 我这边没办法解释了, 只有按照博客说的那样来吧, models这一块的设计没办法讲解了, 我们就这样先过去吧.
来看看博客的用户表吧, 先细说一点, 就是![]() UserProfile继承了AbstractUser这个类, 而这个类有一些基本的字段, 我们是为了省去定义那些必须的字段, 所以才继承这个的, AbstractUser这个django自带的用户表, 那么我们新建了用户表后, 系统怎么认的出我们的表呢, 在setting.py下:
UserProfile继承了AbstractUser这个类, 而这个类有一些基本的字段, 我们是为了省去定义那些必须的字段, 所以才继承这个的, AbstractUser这个django自带的用户表, 那么我们新建了用户表后, 系统怎么认的出我们的表呢, 在setting.py下:
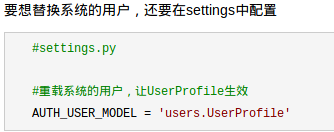
其他的字段我就不多说了, 比较常见.
3.3 goods modules的设计
(3)商品分类model 设计
借用一下别人的图:

可以看出, 这里总共有三类, 那么是不是我们要建三个表来表示呢? 可以建, 但这不是最好的方式, 试想一下, 如果我有n个类, 是不是要建n个表呢? 这样就有点不好了吧,我们可以这样, 我的类别表中有一个索引, 指向上一级类别的外键, 是不是就可以无线延展了, 就像我们学c语言链表一样, 这里我们也采用这种方式来. 在models中产生一个外键, 指向父类. 如下图所示:

其他的我就不多说了, 按照这里来写就是了.
(4)商品model设计

这里我就没什么说的, 直接按照教程写就是了, 那些字段也很容易看出来.
(4)首页商品轮播图model设计
因为首页的商品轮播图片是大图,跟商品详情里面的图片不一样,所以要单独写一个首页轮播图model
(5)商品广告和热搜model
照着教程写......
3.5.用户操作的model设计
.........
四 数据库迁移
(一) 这里说一下数据库的迁移操作:
1. tools->run manage.py task 打开后出现一个错误
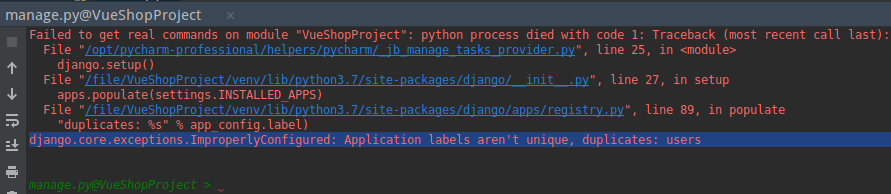
这个错误表示:django.core.exceptions.ImproperlyConfigured:应用程序标签不是唯一的,重复的:用户
因为我们新建工程的时候, 软件已经自动帮你创建了user app, 而且也在setting.py中配置好了,所以我们要把
INSTALLED_APPS中的users去掉,
再次运行, 出现错误:

解决办法: 点进去,

去掉末尾的那个逗号就可以了
然后继续点 run manage.py task, 之后我们就可以做数据库迁移了,
在命令行运行makemigrations ![]()
注意这里可以带appname, 也可以不带, 如果不带则做全部app的数据库迁移, 如果带了, 则对相应的app数据库迁移
运行此条命令有什么用呢?
运行这条命令后, django就知道要对哪些app进行迁移(注意: 这里还没有迁移), 迁移的记录在每个app下的migrations文件下的000x_initial.py文件下. 我们可以打开相应的文件
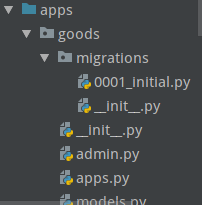

之后我们再运行migrate:

这样django就会执行上一步那些要迁移的记录, 做数据库相应的迁移, 我们在数据库就可以看到生产了好多相应的表

其中, django_migrations记录了迁移的记录

到此, 数据库的迁移完成了,
接下来我讲一下关于数据库的几点坑:
1. 数据库表的操作理论上可以基于软件操作, 也可以基于django的代码操作, 前外不要两者结合, 因为这样会出现出乎意料的bug
2. 如果要新增字段, 只需在原来的基础上修改, 修改重新运行 makemigrations 和migrate就行了.
3. 如果发现设计的表很乱, 可以去数据库把相应的表删除, 然后重新设计表结构, 重新生产表, 一定要删除原来的表
这一章就讲这么多.