学习率控制每次更新参数的幅度,是比较重要的模型超参,过高和过低的学习率都可能对模型结果带来不良影响,合适的学习率可以加快模型的训练速度。
学习率太大会导致权重更新的幅度太大,有可能会跨过损失函数的最小值,导致参数值在极优值两边徘徊,即在极值点两端不断发散,或者剧烈震荡,随着迭代次数增大损失没有减小的趋势。如果学习率设置太小,参数更新速度太慢,导致无法快速地找到好的下降的方向,随着迭代次数增大模型损失基本不变,需要消耗更多的训练资源来保证获取到参数的最优值。对于学习率的设置,刚开始更新的时候,学习率尽可能的大,当参数快接近最优值的时候,学习率逐渐减小,保证参数最后能够达到最优值。而且希望跌打的次数足够少,这样不仅可以加快训练的速度,还可以减少资源的消耗。
- 基于经验的手动调整
通过尝试不同的固定学习率,如0.1,0.01,0.001等,观察迭代次数和损失的变化关系,找到损失函数下降最快对应的学习率。
- 固定学习率
对于新手,建议将学习率设为一个固定值,可以根据训练情况(包括损失函数值和准确率)随时调节学习率。例如,开始时将学习率设置为一个较大的值,设在0.01~0.1,然后通过观察损失函数和准确率的值。如果出现下降缓慢、不再下降或者出现震荡的情况,就将学习率调小,也就是逐次减小的策略。
- 均匀分布降低策略
这一策略与步数步长(Stepsize)相关,每当循环次数达到Stepsize整数倍时,其学习率为learning_rate=base_lr*gamma^(floor(iter/stepsize)),其中iter是当前迭代到第几步,stepsize是每stepsize步时将学习率进行gamma函数调整,原始学习率为base_kr,例如原始学习率base_lr为0.01,每10000步(stepsize)时对学习率进行调整,每一次调整时学习率由0.01变成0.0058(0.01*gamma^(1)=0.01*0.57721)。这一策略的好处是随着迭代次数的变化可以自动降低学习率,不需要人工操作。
- 指数级衰减
指数级衰减与均匀步长原理类似,它先用指数级减少的速度快速减少学习率,使模型接近最优解,然后再逐步减少学习率,不断迭代达到最优解,这样使模型在训练后期更加稳定。在Tensorflow中可以按照下面的公式调整学习率。
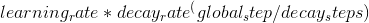
其中learningrate是事先设定的初始学习率,globalstep是当前迭代轮数,decaysteps是指衰减步长,即多少轮后对学习率进行调整,decayrate是指衰减系数,取值范围为(0,1),例如设为0.8.这实质上就是一个常数的指数得到新一轮的逐渐减少的学习率。例如初始学习率为0.01,衰减系数为0.8,衰减步长为每10000步进行一次更新,则第一次更新时学习率为0.01*0.8^(10000/10000)=0.008,第二次更新时,学习率变成0.00512.
代码如下:
# coding:utf-8
import matplotlib.pyplot as plt
import tensorflow as tf
num_epoch = tf.Variable(0, name='global_step', trainable=False)
y = []
z = []
N = 200
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for num_epoch in range(N):
# 阶梯型衰减
learing_rate1 = tf.train.exponential_decay(
learning_rate=0.5, global_step=num_epoch, decay_steps=10, decay_rate=0.9, staircase=True)
# 标准指数型衰减
learing_rate2 = tf.train.exponential_decay(
learning_rate=0.5, global_step=num_epoch, decay_steps=10, decay_rate=0.9, staircase=False)
lr1 = sess.run([learing_rate1])
lr2 = sess.run([learing_rate2])
y.append(lr1)
z.append(lr2)
x = range(N)
fig = plt.figure()
ax = fig.add_subplot(111)
ax.set_ylim([0, 0.55])
plt.plot(x, y, 'r-', linewidth=2)
plt.plot(x, z, 'g-', linewidth=2)
plt.title('exponential_decay')
ax.set_xlabel('step')
ax.set_ylabel('learing rate')
plt.show()可视化效果如下所示:

- AdaGrad动态调整
AdaGrad策略是按照参数更新频率动态调整参数的更新步长,参数更新越低频,更新越大;反之,参数更新越快,参数更新时变化越小,防止参数跳跃最优值。不同特征具有不同学习率,稀疏特征的更新速率高,而其他特征更新速率低,提高了梯度下降的稳健性。
- AdaDeIta自动调整
AdaDelta是对AdaGrad策略的一种改进,优化其学习率急剧下降问题。与AdaGrad相比,AdaDelta不再累加所有的梯度平方和,而是将历史梯度窗口控制在某一固定范围内,基本思想是用一阶的方法近似模拟二阶牛顿法。
- 动量法(Momentum)动态调整
动量法就是模拟物理上加速模型的学习过程,例如小球从高处滚下,其速度会越来越快,直到最低处。梯度下降方法中更加不稳定,每次迭代计算的梯度含有比较大的噪声。引入动量法就是为了解决这一问题。其在更新时保留部分之前更新的方向,同时利用当前这一批数据的梯度微调最终的更新方向。这样可以在一定程序上增加稳定性,从而学习得更快,并且还能部分摆脱局部最优的能力,所以其优点是当前后的梯度方向一致时,能够加速学习;当前后的梯度方向不一致时,能够抑制震荡,更加稳定。
- RMSProp动态调整
RMSProp与Momentum方法类似,每次迭代都按照一定比例对学习率进行衰减,这个比例称为衰减系数。与AdaGrad算法相比,RMSProp用移动平均代替梯度的累积,从而解决学习率过早趋向于0而结束训练,并通过衰减系数控制历史学习率的保留。
- 随机梯度下降
随机梯度下降是对批量梯度下降的改进,与批量梯度下降法相比,SGD每次更新时只随机取一个样本计算梯度,所以速度较快。但是,在频繁更新的情况下,会导致结果不稳定,波动较大,所以现在的SGD一般都指随机小批量梯度下降(MGD),即随机抽取一批样本,以此更新参数。通常一小批数据含有的样本数量为50~256。
- Adam自动调整
Adam首先计算梯度的一阶矩E(x)和二阶矩E(X2)估计,并据此为不同参数设置独立的自适应学习率。传统的随机梯度下降中是按照固定学习率更新所有参数权重,而在Adam策略中,它为每一个参数保留一个学习率以提升在稀疏梯度上的性能。同时,与RMSProp类似,它基于移动平均的思想为每一个参数保留近期学习率,所以Adam算法在非稳态和在线问题上有很有优秀的性能。
下面用Tensorflow对MNIST数据集进行分类,使用不同的优化器查看准确度的变化,代码如下:
import tensorflow as tf
import ssl
ssl._create_default_https_context=ssl._create_unverified_context
from tensorflow.examples.tutorials.mnist import input_data
mnist=input_data.read_data_sets("./mnist_data",one_hot=True)
#定义学习率、迭代次数、批大小、批数量(总样本数除以批大小)等参数,设置输入层大小为784,即将28*28的像素展开为一维行向量(一个输入图片784个值)。第一层和第二层隐层神经元数量均为256输出层的分类类别为0~9的数字,即10个类别
learning_rate=0.005 #学习率
training_epochs=20 #迭代次数
batch_size=100 #批大小
batch_count=int(mnist.train.num_examples/batch_size) #批数量
n_hidden_1=256 #第一层和第二层隐层神经元数量均为256 #根据训练集的特征个数
n_hidden_2=256
n_input=784#设置输入层的大小为784
n_classes=10 #(0-9数字)
X=tf.placeholder("float",[None,n_input]) #第二个参数为维度 None为无穷大
Y=tf.placeholder("float",[None,n_classes])
#使用tf.random_normal()生成模型权重值参数矩阵和偏置参数,并将其分别存储于weights和biases变量中,并定义多层感知机的神经网络模型
weights={
'weight1':tf.Variable(tf.random_normal([n_input,n_hidden_1])),
'weight2':tf.Variable(tf.random_normal([n_hidden_1,n_hidden_2])),
'out':tf.Variable(tf.random_normal([n_hidden_2,n_classes]))
}
biases={
'bias1':tf.Variable(tf.random_normal([n_hidden_1])),
'bias2':tf.Variable(tf.random_normal([n_hidden_2])),
'out':tf.Variable(tf.random_normal([n_classes]))
}
def multilayer_perceptron_model(x):#wx+b
layer_1=tf.add(tf.matmul(x,weights['weight1']),biases['bias1'])
layer_2=tf.add(tf.matmul(layer_1,weights['weight2']),biases['bias2'])
out_layer=tf.matmul(layer_2,weights['out'])+biases['out']
return out_layer
#使用输入变量X初始化模型,定义损失函数为交叉熵,采用梯度下降法作为优化器(除此之外 还可选MomentumOptimizer、AdagradOptimizer、AdamOptimizer等,见注释部分
#并对模型中tf.placeholder定义的各参数初始化
logits=multilayer_perceptron_model(X) #多层感知机
#
loss_op=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=logits,labels=Y)) #定义损失函数为交叉熵
#用来更新和计算影响模型训练和模型输出的网络参数,使其逼近或达到最优值,从而最小化(或最大化)损失函数E(x)
# 这种算法使用各参数的梯度值来最小化或最大化损失函数E(x)。最常用的一阶优化算法是梯度下降。
optimizer=tf.train.GradientDescentOptimizer(learning_rate)
# optimizer=tf.train.MomentumOptimizer(learning_rate,0.2)
# optimizer=tf.train.AdamOptimizer(learning_rate)
# optimizer=tf.train.AdagradOptimizer(learning_rate)
# optimizer=tf.train.AdadeltaOptimizer(learning_rate)
# optimizer=tf.train.RMSPropOptimizer(learning_rate,0.2)
train_op=optimizer.minimize(loss_op)
init=tf.global_variables_initializer()#参数初始化
#将训练集样本输入模型进行训练,并计算每个批次的平均损失,在每次迭代时输出模型的平均损失
with tf.Session() as sess:
sess.run(init)
for epochs in range(training_epochs):
avg_cost=0
for i in range(batch_count):
train_x,train_y=mnist.train.next_batch(batch_size)
_,c=sess.run([train_op,loss_op],feed_dict={X:train_x,Y:train_y})
avg_cost+=c/batch_count #计算每个批次的平均损失
print("Epoch:",'%02d' % (epochs+1),"avg cost={:.6f}".format(avg_cost))
#模型训练完成,使用测试集样本对其评估,并计算其正确率
pred=tf.nn.softmax(logits) #Apply softmax to logits
correct_pediction=tf.equal(tf.argmax(pred,1),tf.argmax(Y,1))
accuracy=tf.reduce_mean(tf.cast(correct_pediction,"float"))
print("Accuracy:",accuracy.eval({X:mnist.test.images,Y:mnist.test.labels}))
使用随机梯度下降优化器的准确率为:
![]()
使用动量法(Momentum)动态调整优化器的准确率为:
![]()
使用Adam自动调整优化器的准确率为:
![]()
使用AdaGrad动态调整的优化器准确率为:

使用AdaDeIta自动调整的优化器的准确率为:

使用RMSProp动态调整优化器的准确率为:
