Delicious 算法
最直觉、最简单的算法,莫过于按照单位时间内用户的投票数进行排名。得票最多的项目,自然就排在第一位。
例如,旧版的 Delicious,有一个"热门书签排行榜",就是这样统计出来的。它按照"过去 60 分钟内被收藏的次数"进行排名。每过 60 分钟,就统计一次。
- 优点
简单、容易部署、内容更新相当快; - 缺点
排名变化不够平滑,前一个小时还排在前列的内容,往往第二个小时就一落千丈。
Hacker News 算法
Hacker News是一个网络社区,可以张贴链接,或者讨论某个主题。
每个帖子前面有一个向上的三角形,如果你觉得这个内容很好,就点击一下,投上一票。根据得票数,系统自动统计出热门文章排行榜。但是,并非得票最多的文章排在第一位,还要考虑时间因素,新文章应该比旧文章更容易得到好的排名。
帖子的分计算公式:
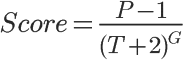
其中,
P表示帖子的得票数,减去1是为了忽略发帖人的投票。
T表示距离发帖的时间(单位为小时),加上2是为了防止最新的帖子导致分母过小(之所以选择2,可能是因为从原始文章出现在其他网站,到转贴至Hacker News,平均需要两个小时)。
G表示"重力因子"(gravityth power),即将帖子排名往下拉的力量,默认值为1.8,后文会详细讨论这个值。
从这个公式来看,决定帖子排名有三个因素:
第一个因素是得票数P。
在其他条件不变的情况下,得票越多,排名越高。
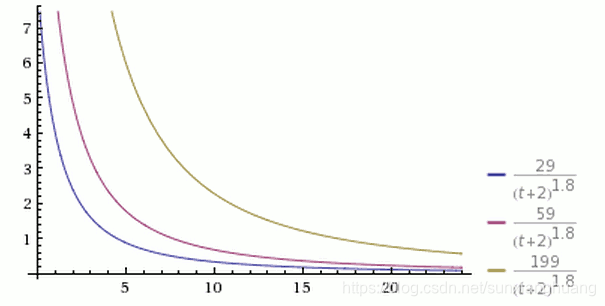
从上图可以看到,有三个同时发表的帖子,得票分别为200票、60票和30票(减1后为199、59和29),分别以黄色、紫色和蓝色表示。在任一个时间点上,都是黄色曲线在最上方,蓝色曲线在最下方。
如果你不想让"高票帖子"与"低票帖子"的差距过大,可以在得票数上加一个小于1的指数,比如(P-1)^0.8。
第二个因素是距离发帖的时间T。
在其他条件不变的情况下,越是新发表的帖子,排名越高。或者说,一个帖子的排名,会随着时间不断下降。
从前一张图可以看到,经过24小时之后,所有帖子的得分基本上都小于1,这意味着它们都将跌到排行榜的末尾,保证了排名前列的都将是较新的内容。
第三个因素是重力因子G。
它的数值大小决定了排名随时间下降的速度。
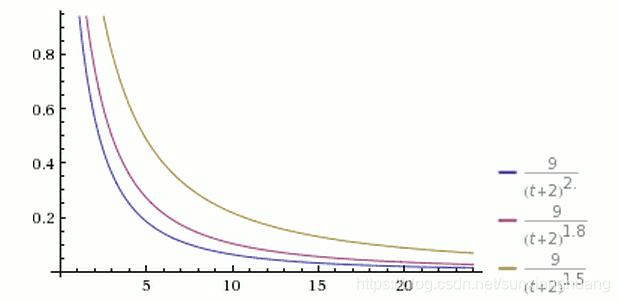
从上图可以看到,三根曲线的其他参数都一样,G的值分别为1.5、1.8和2.0。G值越大,曲线越陡峭,排名下降得越快,意味着排行榜的更新速度越快。
知道了算法的构成,就可以调整参数的值,以适用你自己的应用程序。
参考:https://blog.csdn.net/zhuhengv/article/details/50475685
Reddit 算法
Python版源码排序如下:
#Rewritten code from /r2/r2/lib/db/_sorts.pyx
from datetime import datetime, timedelta
from math import log
epoch = datetime(1970, 1, 1)
def epoch_seconds(date):
"""Returns the number of seconds from the epoch to date."""
td = date - epoch
return td.days * 86400 + td.seconds + (float(td.microseconds) / 1000000)
def score(ups, downs):
return ups - downs
def hot(ups, downs, date):
"""The hot formula. Should match the equivalent function in postgres."""
s = score(ups, downs)
order = log(max(abs(s), 1), 10)
sign = 1 if s > 0 else -1 if s < 0 else 0
seconds = epoch_seconds(date) - 1134028003
return round(order + sign * seconds / 45000, 7)
话题排序算法的数学描述如下图:

线性时间收缩&多数投票增长

“踩”的影响
Reddit是少有的有“踩”的网站之一。你可以在代码中看到score被定义为:“顶”的票数-“踩”的票数。
“踩”的票数对于得到了很多“顶”和“踩”的话题的得分有着很大的影响。它们的得分比较低仅仅是因为得到了反对票。这可以解释为什么Kittens(和其他非争议性的话题)的排名为何如此之高。:)
信心排序算法(评论排名)
#Rewritten code from /r2/r2/lib/db/_sorts.pyx
from math import sqrt
def _confidence(ups, downs):
n = ups + downs
if n == 0:
return 0
z = 1.0 #1.0 = 85%, 1.6 = 95%
phat = float(ups) / n
return sqrt(phat+z*z/(2*n)-z*((phat*(1-phat)+z*z/(4*n))/n))/(1+z*z/n)
def confidence(ups, downs):
if ups + downs == 0:
return 0
else:
return _confidence(ups, downs)
信心排序使用了Wilson评分区间,数学描述如下:
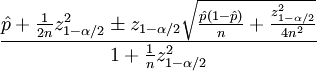
上述公式中的参数定义如下:
- p指的是好评数
- n指的是投票总数
- zα/2 是(1-α/ 2)标准正态分布分量
总结一下就是:
- 信心排序将投票看作是大家表决的统计抽样计票
- 信心排序用85%的置信度来确定评论的排名
投票越多,85%置信度下的评论的信心分数越接近真实分数
威尔逊区间对于小样本或者极端情况也具有良好作用
Randall 在他博客文章《信心排序是如何进行评论排序的》中举了一个很好的例子:
如果一个评论有1票“顶”,0票“踩”,那么它的“顶”就为100%,由于样本数据太少,系统将会将它排在底部。
但是如果它有10个“顶”而只有1个“踩”的话,系统就可以有足够的信心判定它应该排在那些有40个“顶”但是也有20个“踩”的评论(如果这个时候它得到了40个“顶”,那么几乎可以肯定它得到的“踩”小于20个)的前面。更好的是如果判断错误(15%的概率),它很快会得到更多的数据,因此,数据少的评论出现在了顶部。
提交时间对评论排序没有影响
提交时间对于信心排序算法来说是无关紧要的(这一点和热排序算法还有Hacker 新闻排序算法不同)。 评论排名靠的是信心分数和数据采样——也就是说的到的票数越多,信心分数也就越精确。
观察
我们用Randall的例子来观察一下信心排序是如何对评论进行排序的:

从上图你可以看到信心排序根本就不关心一个评论得到了多少票数,它关心的是“顶”的票数和总票数的比值。
内容源自:
https://www.oschina.net/translate/how-reddit-ranking-algorithms-work?print
http://amix.dk/blog/post/19588#How-Reddit-ranking-algorithms-work