近日,小米传来好消息!
小米自研声音识别算法在音频标记(Audio Tagging)任务中取得重要进展。以公开数据集 AudioSet-2M 的音频数据作为训练集的音频标记模型,在业界首次突破 50 mAP 的分数,是截至目前所有音频标记任务论文中的最好成绩。
推动数据集 AudioSet 音频标记 mAP 指标进入 50+ 时代,标志着小米声音识别算法已在国际上性能排名第一。

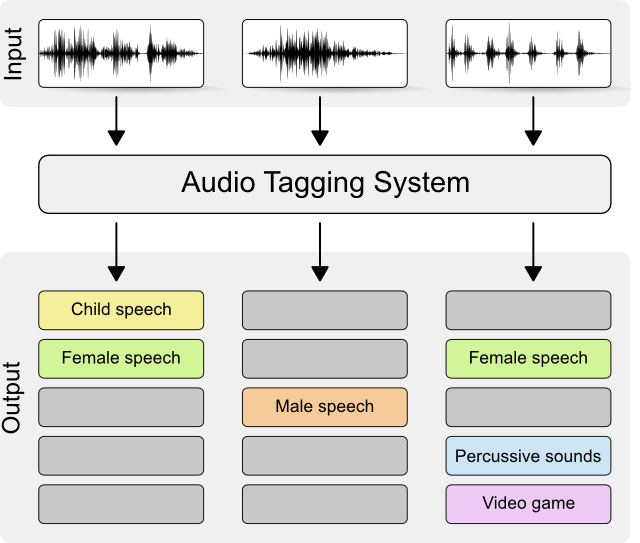
音频标记算法可以识别广泛的声音,有助于让环境中的声音也能用文字等其他模态同等地表达,让声音被“看”见。
小米此次自研声音识别算法的重要进展,能够在小米手机、小米音箱、小米手环/手表、CyberOne/CyberDog 等丰富的设备场景中,给用户带来更加高效和准确的声音识别体验。
01
登顶声音领域 ImageNet
刷新音频标记技术最高指标
音频标记任务的目标是对音频进行多标签分类,使计算机能够理解音频内容,从而可应用于音频搜索、危险事件识别、机器故障监测、辅助无障碍等广泛场景。例如,对于视觉障碍者来说,音频标记技术可以帮助他们识别和理解周围环境中的声音,弥补视觉上的能力缺失。
Audio Tagging 任务(图片来源:DCASE 挑战赛官网)
此外,近期大语言模型(Large Language Model, LLM)受到了广泛的关注,学界和产业界也在积极推进音频大模型(Large Audio Model, LAM)的研究。已知的研究成果几乎都用到了预训练的音频标记模型用作音频编码,为整个大模型提供关键的音频信息提取能力。这使得音频标记任务不仅具有广泛的应用价值,也为未来音频大模型的研发提供技术基础。
Google 发布的 AudioSet 是音频标记任务影响力最大的数据集,被认为是声音领域的 ImageNet (计算机视觉领域最著名的数据集,由著名学者李飞飞等主持发布)。AudioSet 由来自 YouTube 的 200 余万条 10 秒的音频构成,总时长约为 5800 小时。通过人工听辨,这些音频被层次化地用 527 类标签标注。

AudioSet 数据集被发布者 Google 划分为了 balanced train、unbalanced train 和 evaluation 三个子集,前两个子集用于训练,最后一个子集用于测试。其中 balanced train 通常也被称为 “AudioSet-20K”,balanced train 和 unbalanced train 的合并则被称为 “AudioSet-2M”。各研究机构在发表研究成果时,通常都会在论文中给出使用 AudioSet-2M 作为训练集、使用 evaluation 作为测试集的结果,以便公平地在各机构间横向对比算法性能。Mean Average Precision (mAP) 是评价声音识别性能最通用的指标,其中 Average Precision(AP)表征特定类别 precision-recall 曲线的面积,mAP 为各类别 AP 的平均,mAP 越大越好。
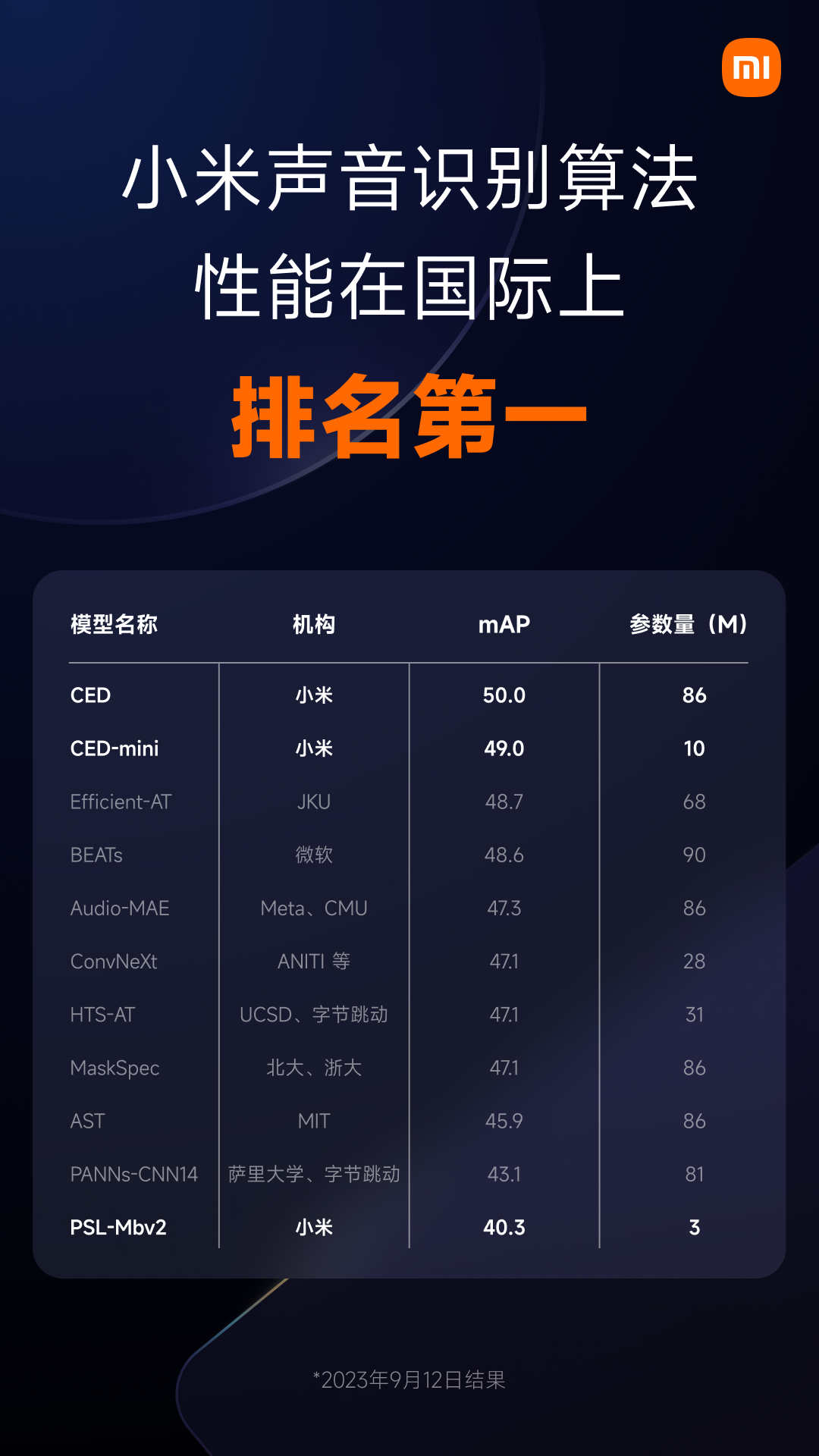
以 AudioSet-2M 的音频数据作为训练集,小米的模型在业界首次突破了 50mAP,刷新了音频标记技术指标,成为了截至目前性能最好的模型。此外,小米还发布了一个 mini 版模型,适合资源受限的场景。Mini 版模型的参数量压缩到了原模型的约九分之一,远小于其他机构的模型(详见榜单),但仍然优于其他所有机构的模型性能。
02
解译技术方案
更高效的知识蒸馏
小米此次能够把 AudioSet 的 mAP 指标做到 50,其关键在于:1. 用更大的模型;2. 造更多的数据。(*这里“造数据”指的是数据扩增(Data Augmentation),即对训练集通过一些比如随机加噪等手段生成更多的数据,并没有使用额外的数据集,因此横向对比仍然是公平的。)
更大的模型和更多的数据能使算法性能提升,这听起来似乎是显然的。但模型过于巨大会难以部署,包括导致推理缓慢,从而失去实用价值。但是,榜单中可以看到,小米的模型虽然在性能指标上排名第一,参数量却并不比其他模型更大。尤其是,小米排名第一的模型即使参数量进一步压缩到其他机构最好模型的七分之一,仍然超过其他所有机构的模型性能。这主要得益于知识蒸馏(Knowledge Distillation, KD)技术。
▍什么是知识蒸馏(KD)技术?
KD 并不能算是新技术,早在 2015 年就已由 Hinton(神经网络奠基人之一,图灵奖获得者)提出,主要思路是用一个性能强大但不利于部署的 teacher 模型对一个参数量较小的 student 模型进行指导,期望 student 模型达到和 teacher 模型近似的性能,从而获得同时具备高性能和低参数量的模型。
小米声学语音团队曾在 2022 年的语音顶会 ICASSP 上基于 KD 发表了 PSL 模型训练框架并开源(*论文下载地址:https://arxiv.org/pdf/2204.13430.pdf),参数量只有当时 SOTA 的近 1/30,却能够在数据量小于 AudioSet-2M 的 AudioSet-20K 训练集上做到性能接近 SOTA (PSL mAP 35,SOTA 38)。
2022 年的 PSL 框架的性能没有做到更强,主要是因为当时没有找到把更大的模型作为 teacher 进行 KD 的方法。KD 有在线和离线两种方式,在线 KD 会在每次训练迭代中计算 teacher 模型输出,离线 KD 则是把 teacher 模型输出预先保存到磁盘上。显然离线 KD 的空间换时间的方案可以使训练速度快得多,也大大节约每次实验的 GPU 占用,但离线 KD 的方案和数据扩增难以同时进行。
在 KD 中使用数据扩增的训练方式称为 Consistent Teaching (CT),当数据扩增的力度较大时,离线 KD 的磁盘占用量会增长很多倍,即使是磁盘价格低廉的今天,其成本仍然难以承受。而 CT 又至关重要,我们通过实验发现,如果能够成功应用 CT,可以使 ViT-Base 模型性能比不使用 CT 相对提升 16% ,这是一个非常巨大的提升点。
▍我们做了哪些改进?
我们提出了 Consistent Ensemble Distillation (CED) 训练框架改进 KD。具体地,CED 对传统 KD 作了三点主要改进:
使用随机种子代替输出向量,作为离线 KD 的存储内容,这在计算量没有明显升高的前提下,极大地降低了存储量。
实验了用 Top-K 分数代替全类别分数进行存储以及若干平滑算法,使 Top-K 结果并不导致性能明显下降,这进一步降低存储。
使用一些工程技巧使数据的读取从随机读取转变为顺序整块读取,这一改进使得训练时在机械磁盘上存取数据能达到和固态硬盘接近的速度。
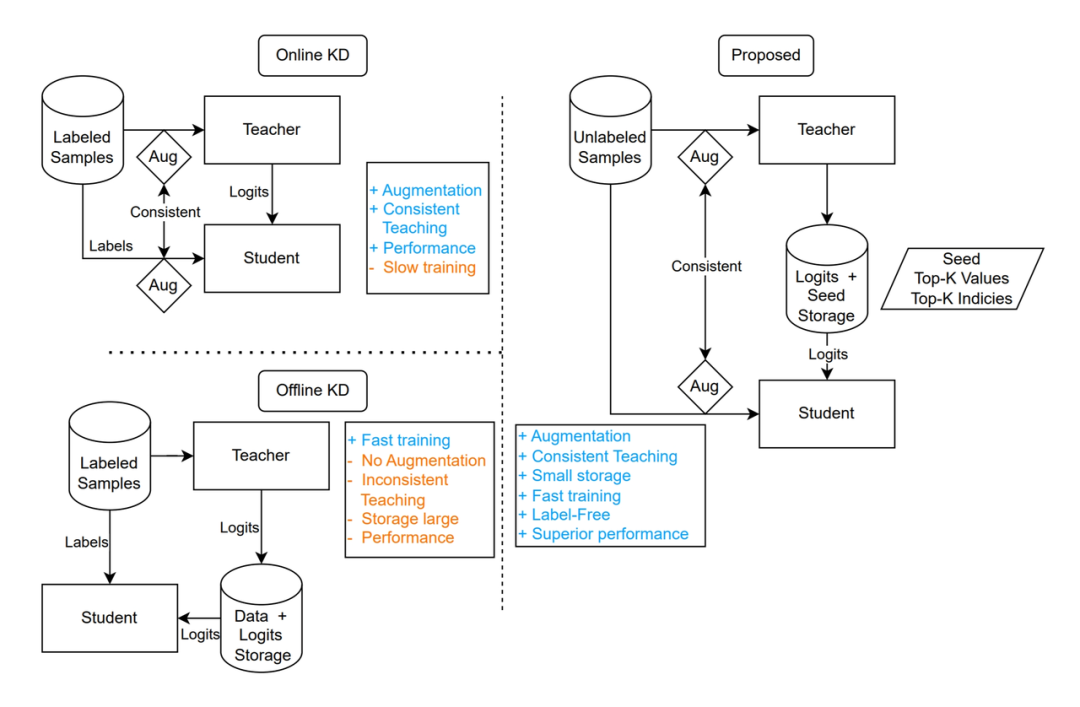
CED 训练框架:左图为传统在线和离线 KD,右图为小米对 KD 的改进
通过这些改进,KD 的效率得到了巨大提升,使得我们能够利用参数量比之前大得多的 teacher 模型(参数量超过了 1B)和 CT 来训练音频标记模型,这是小米能够在行业内把该任务的性能首次突破 50mAP 的关键。
此外,CED 框架和需要标签的传统 KD 方案不同,CED 框架在训练 student 模型时完全不需要人工标注。尽管为了和其他算法横向比较,我们没有利用这个特性增加更多数据,但该特性的价值是巨大的,给利用海量的无标签数据提供了可能。通过 CED 框架,可以做到 student 模型比 teacher 模型的 mAP 仅落后 0.1 mAP。该框架的方法并不局限于本任务,它还可以推广到图像、自然语言处理等各个领域,在这些领域上我们相信 CED 框架都可以起到很大的帮助。
03
乘技术东风,破感知壁垒
音频标记算法可以识别广泛的声音,比如婴儿啼哭声、动物叫声、汽车引擎声、爆炸声、烟雾警报、门铃声、水流声等,有助于让环境中的声音也能用文字等其他模态同等地表达,让声音被“看”见,比如搭载在小米手机中的小米闻声、小米音箱的环境音监测、小米健康的睡眠鼾声检测、CyberOne/CyberDog 的环境语义识别等,在丰富的设备场景中,给用户带去更加高效和准确的声音识别体验。
▍小米闻声
生活中除了与人交流以外,环境中各种声音也承载了大量的信息。小米闻声中的声音识别功能,可以监测 14 种重要的环境音,包含火警、婴儿啼哭、烧水壶声等等,并在手机通知栏进行推送。同时小米手环上也可以同步显示通知,随时随地不怕错过重要信息。
小米闻声可以让手机或平板电脑帮助听障用户“看到”其他人说话,另一方面也可以帮他们“看见”周围环境中的声音,例如警报声、敲门声等,赋予了听障用户同样的声音感知权利。

小米闻声的使用界面(左侧为对话模式,右侧为字幕模式)
▍智能家居设备
除了手机,环境音技术也已经上线更多智能家居设备。例如米家摄像头的宝宝哭声监测功能,就是在检测到宝宝哭声的时候,实时向用户的手机推送通知。同时,Xiaomi Sound 音箱也搭载声音识别功能,能够识别家用报警器、婴儿啼哭、火警、流水、猫叫、狗叫六种在家居环境下用户所关心的声音;小米健康 APP 的睡眠鼾声检测,可以帮助检测我们在睡眠时的鼾声梦话。
小米健康 APP 的鼾声梦话监测
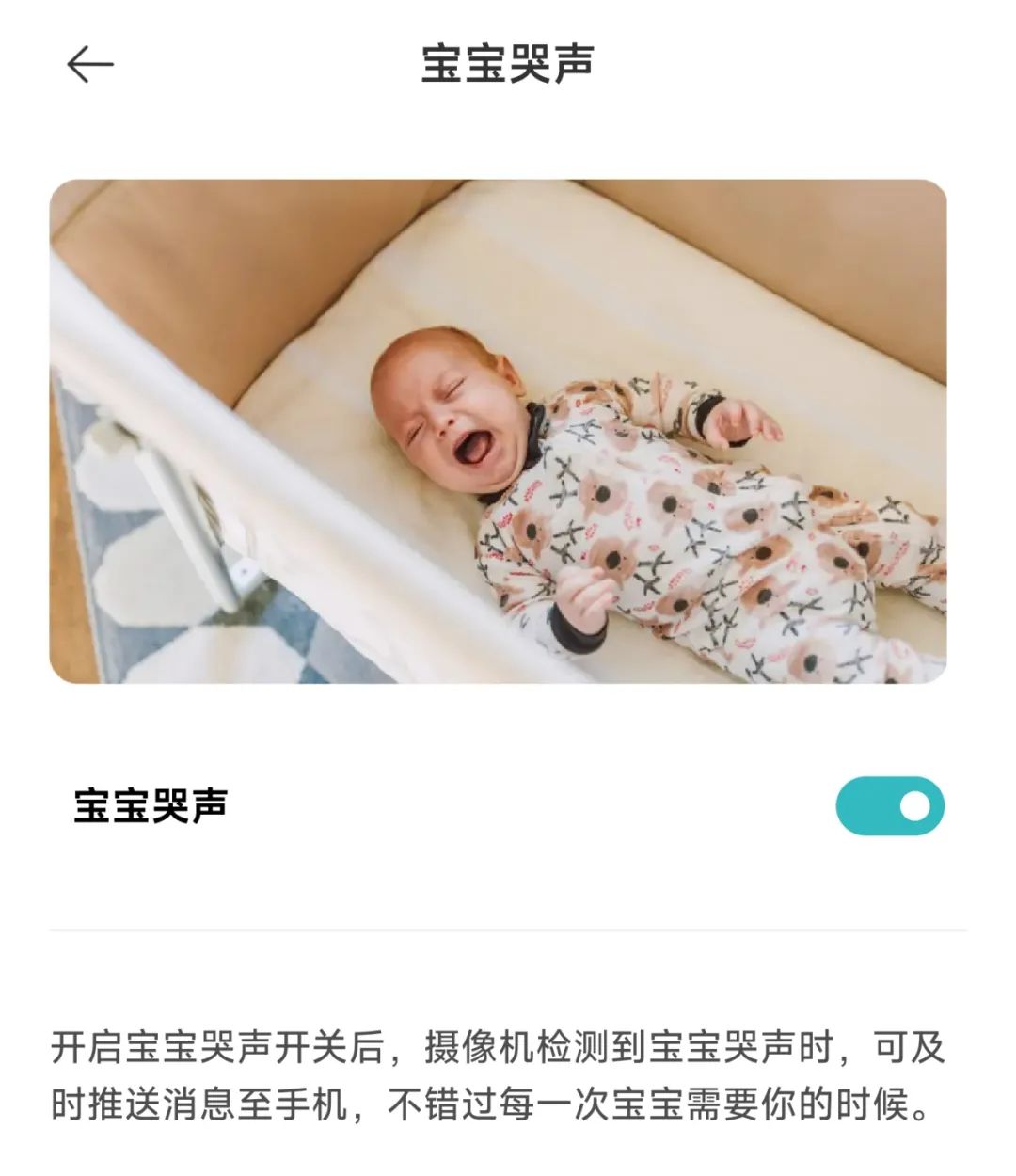 米家摄像头宝宝哭声监测功能
米家摄像头宝宝哭声监测功能
针对家庭场景,音箱环境音监测还做了特别的适配。例如水流声的识别,为了避免一开水龙头就触发通知可能会对用户造成的困扰,技术人员将流水声提醒的条件改为在一分钟之内多次监测到流水声,以避免提醒误发。
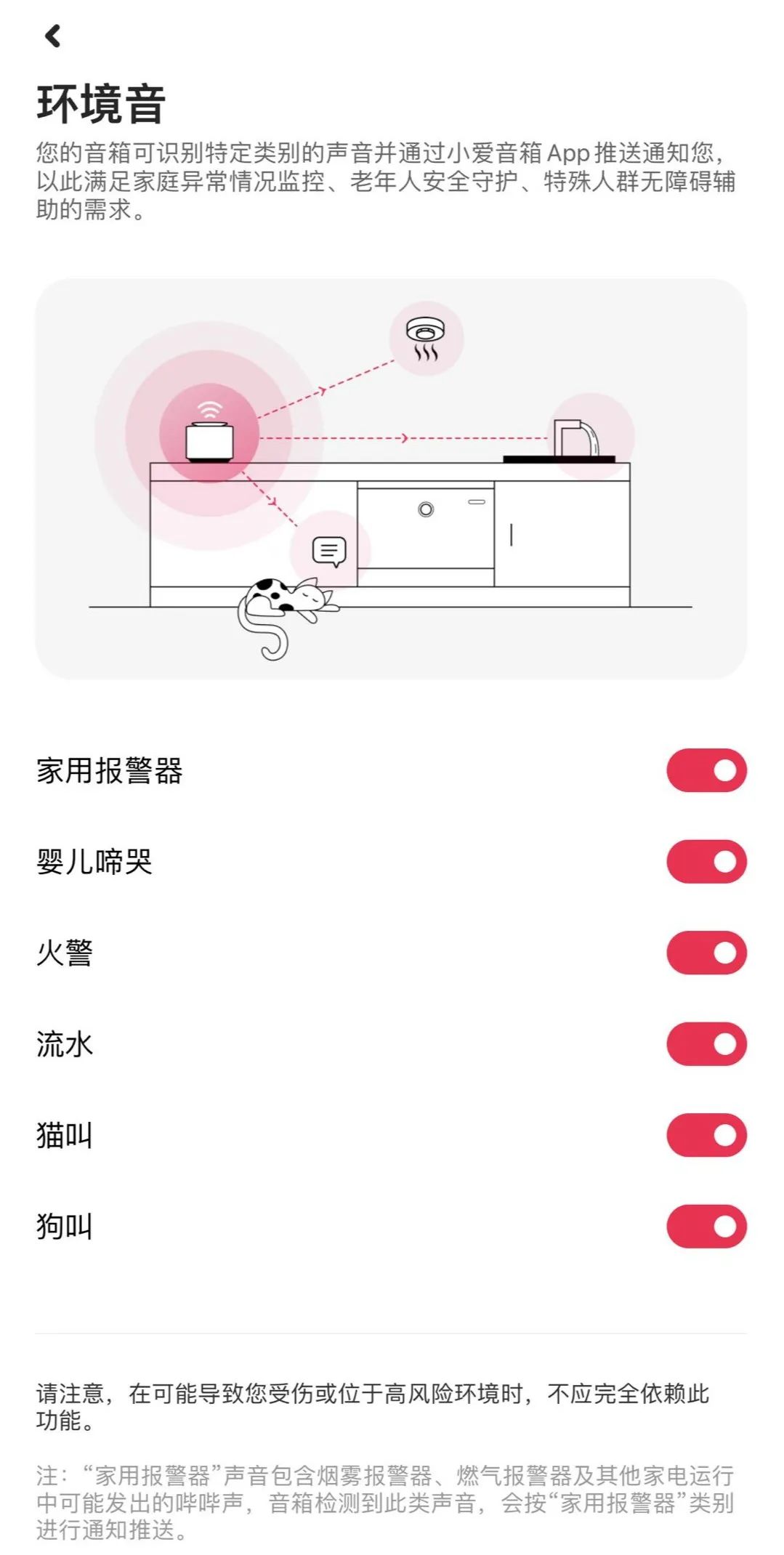
Xiaomi Sound 音箱搭载的环境事件监测
▍全尺寸人形机器人 CyberOne 和仿生四足机器人 CyberDog
从零到一,历时 10 个月全栈自研完成的小米第一代全尺寸人形机器人 CyberOne,可识别 85 种环境声音,通过听觉感知 6 类、45 种人类的情绪。小米 CyberDog 四足机器人(第二代)可识别 38 种环境声音。

04
让科技落地,普惠智能生活
小米一直致力于让 AI 技术渗透到更多场景中,助力科技给每个人带来美好生活。目前已经构建起全球领先的消费级 AloT 平台,截至 6 月 30 日,小米 AIoT 平台已连接的 IoT 设备(不含手机、平板和笔记本电脑)数达 6.55 亿,创下历史新高。

小米声学语音团队已将自研声学语音技术全面应用于小米手机、音箱、电视、耳机、手表、机器人等 79 个品类,共计 5312 款智能产品中。小爱同学月活跃用户数量为 1.15 亿,是世界上最忙的语音助手之一。声学语音团队承接了小米手机×AIoT 设备上日均 12.6 亿次请求,为 4.59 亿设备累计提供了 2158 亿次交互语音服务。
未来,小米将不断探索科技新高度,用强大的技术能力推动“让世界上每个人都能享受科技带来的美好生活”的使命,让用户乐享智慧生活,感受科技带来的便捷与趣味。
-
秉持着开放与共享的精神 ,我们开源了模型训练代码和预训练模型,供同行研究使用:
论文地址:https://arxiv.org/abs/2308.11957
训练代码:https://github.com/RicherMans/CED
预训练模型:https://zenodo.org/record/8275347

