目录
1.由来
这几天学了遗传算法,不甚理解,所以就进行了实例应用。
该应用是进行图像分割的应用,用的约束条件是最大类间方差法。先来讲讲最大类间方差法,下图是我做的ppt中的截图:

类间方差是按图像的灰度特性,将图像分成背景和目标2部分。背景和目标之间的类间方差越大,说明构成图像的2部分的差别越大,当部分目标错分为背景或部分背景错分为目标都会导致2部分差别变小。因此,使类间方差最大的分割意味着错分概率最小。
染色体表示:
由于灰度级范围是在0-255之间,故采用8位二进制编码表示每个灰度级。
初始化种群:
从图像中随机选择20个像素对应的灰度作为初始种群。
适应度评价:
采用类间方差公式作为评价标准,即以该个体的灰度级作为阈值k,然后对每个个体求E、E0、E1、P0、P1,然后求出该个体对应的类间方差。以此类间方差作为评价因子
选择:
选择采用轮盘赌选择方式,按20个个体的评价因子分别占20个个体的总评价因子的比例作为被选中的概率。用随机函数来选择个体,为了保证子代种群数目不变,最终从20个个体选择20次。新的20个个体中有旧的20个体中的一部分,概率大的个体会补足到被淘汰个体的空位上。
交叉操作:
交叉概率设置为60%,交叉操作按双点交换,交换为从低位的第三位到第五位
变异操作:
变异概率设为千分之五,采用随机基本位变异
停止准则:
停止准则采用最大迭代次数作为终止条件。
下图是我所使用的系统:

2.代码
# -*- coding: utf-8 -*-
import numpy as np
import cv2
import random
#将不足8位的染色体扩展为8位
#k的值大概为:k=['0b1011','0b110110','0b100111']
def expand(k):
for i in range(len(k)):
k[i]=k[i][0:2]+'0'*(10-len(k[i]))+k[i][2:]
return k
#n[grayscale]横坐标(grayscale可视为横坐标)为像素的灰度级,从0-255,纵坐标为在整个图像中各个灰度级的像素个数
#MN=n0+n1+n2+n3+...+n255;n0代表灰度级为0的像素个数,MN总的像素个数
#n[grayscale]=n[i];n[grayscale]:n0,n1,n2,n3,n4,n5,n6,n7,...,n255;n0代表灰度级为0的像素个数;grayscale是灰度级
#p[i]=n[i]/(n0+n1+n2+n3+...+n255);返回的p[i]为p[0]到p[255]
#average=0*p0+1*p1+2*p2+3*p3+...+255*p255;average=E
def Hist(image):
n=[0]*256
p=[0.0]*256
h=image.shape[0]
w=image.shape[1]
MN=h*w
average=0.0
for i in range(h):
for j in range(w):
grayscale=int(image[i][j])
n[grayscale]=n[grayscale]+1
for i in range(256):
p[i]=n[i]/(MN+0.00001)
average=average+p[i]*i
return (p,average)
#适应度算子 Ostu全局算法
#每个元素都为八位二进制灰度级,有20个元素,len(seed)=20,例seed[0]='0b11000110'
#p[i];p0,p1,p2,p3,p4,p5,...,p255
#average=E
#P1是小于灰度值k[i]的像素占总的像素的比例,即灰度介于0-k[i]之间的像素个数总和/总像素个数,即灰度值小于k[i]的像素的pi总和
#hist[i]是i可想象成横坐标,纵坐标是hist[i]中存储的内容,内容为整幅图像中灰度值为i的像素占总像素的比例
#Var里存储有20个元素
def fitness(seed,p,average):
E=0.0
E=average
evaluate=[0]*len(seed) #evaluate里存储有20个元素
for i in range(len(seed)):
P0=0.0
E0=0.0
E1=0.0
P1=0.0
for j in range(int(seed[i],2)):
P0=P0+p[j]
E0=E0+p[j]*j
P1=1-P0
E1=E-E0
evaluate[i]=P0*pow((E0/(P0+0.00001)-E),2)+P1*pow((E1/(P1+0.00001)-E),2)
return evaluate
#seed[i]里面存储的是灰度值,共20个
#Var[i]里面存储的是评价因子,越大的越优
#选择算子 轮盘赌选择算法
def wheel_selection(seed,evaluate):
p_roulette=[0.0]*len(evaluate) #var的长度为20,len(Var)=20
s=0.0
next=['']*len(seed) #n的长度为20,len(k)=20
for i in range(len(evaluate)):
p_roulette[i]=evaluate[i]/(sum(evaluate))
for i in range(1,len(evaluate)):
p_roulette[i]=p_roulette[i]+p_roulette[i-1]
for i in range(len(seed)):
s=random.random()
for j in range(len(p_roulette)):
if s<=p_roulette[j]:
next[i]=seed[j]
return next
#变异算子
def Variation(Next):
for i in range(len(Next)):
if random.random()<0.005: #按照0.5%概率进行变异操作
s=random.randint(2,9)
if Next[i][s] == '0' :
Next[i]=Next[i][0:s]+'1'+Next[i][s+1:]
elif Next[i][s]=='1':
Next[i]=Next[i][0:s]+'0'+Next[i][s+1:]
return Next
#交叉算子
#Next是存储的已经筛选出来的个体,len(Next)=20,其中可能有些个体是重复的
def Cross(Next):
for i in range(len(Next)-1):
if random.random()<0.6:
temp=Next[i][5:8]
Next[i]=Next[i][:5]+Next[i+1][5:8]+Next[i][8:10]
Next[i+1]=Next[i+1][:5]+temp+Next[i+1][8:10]
return Next
#展示原图及处理后的图
def show(k,im):
image_before=im
#a=u'原图'
b=u'处理后的图'
a_gbk=a.encode('gbk')
b_gbk=b.encode('gbk')
#cv2.imshow(a_gbk,image_before)
for i in range(len(im)):
for j in range(len(im[i])):
if im[i][j]>k:
im[i][j]=255
else:
im[i][j]=0
cv2.imshow(b_gbk,im)
cv2.waitKey(0)
#im为读取图像的数据
#seed表示每一代将要进行选择,复制,变异和交叉的个体
#last_fit和now_fit分别表示父子两代群体的最大适应度
#k为在规定代数结束后,最大适应度个体的染色体表示,即为最佳阈值
a=r'C:\Users\GPJ\Desktop\166.jpg'
im=cv2.imread(a,0)
items=range(0, min(im.shape))
random.shuffle(items)
x=items[0:20]
y=items[20:40]
seed=[]
evaluate=0.0
times=0
k=0
p,average=Hist(im)
for i in range(20):
seed.append(bin(im[x[i]][y[i]]))
seed=expand(seed)
#------------------------begin----------------------
print 'im:',im
print 'seed:',seed
#------------------------end------------------------
while times<1000:
evaluate=fitness(seed,p,average)
Next=wheel_selection(seed,evaluate)
Next=Cross(Next)
Next=expand(Variation(Next))
seed=Next
times=times+1
print(max(evaluate))
#当类间方差最大时,可以认为此时前景和背景差异最大,此时的灰度是最佳阈值。
for j in range(len(evaluate)):
if evaluate[j]==max(evaluate):
k=int(Next[j],2)
print (k)
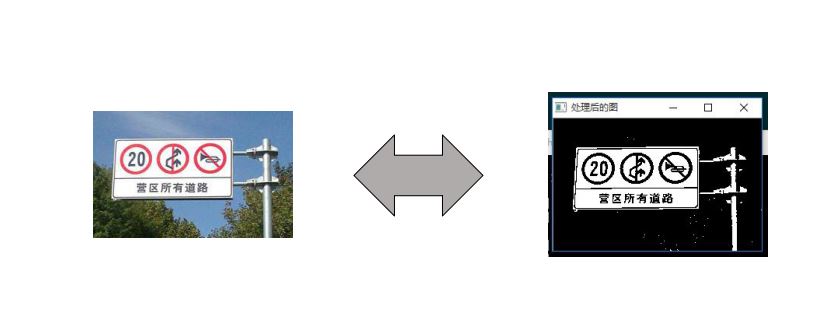
show(k,im)如下为结果展示:
3.总结
其实这个算法算出来的阈值k是不收敛的,结果有问题,也就是说我的这个练习是不成功的。最后的问题可能出在适应度函数上,这个淘汰筛选过程可能有问题。以后有时间再处理一下。还有果壳上看到的用遗传算法拟合火狐浏览器图标的例子很有趣,有时间再把这个自己实现一下。