最近在研究LSTM的网络结构,尤其是LSTM内部结构(隐藏权重和偏置),这篇博客作为一个概括,简单说用LSTM完成的任务,一个是藏头诗和古诗的自动生成,一个是IMDB影评数据的文本情感分析。
这篇博客先讲一下第一个任务:用LSTM网络实现藏头诗(也包括古诗)的自动生成,之后再更新用于情感分析。
自然语言处理是教会机器如何去处理或者读懂人类语言的系统,目前比较热门的方向,Long Short Term Memory (LSTM)是循环神经网络的改进,在自然语言处理方面有明显的优势,在当前卷积神经网络流行的时期依然担当者重要角色。本文采用两层的LSTM网络,训练数据集为34646首唐诗。文中详细介绍了诗歌数据的预处理过程,包括数据清洗、统计词频、生成字库、根据字库把每一首诗转化为一个向量。诗歌转化为词向量采用one-hot编码的方式,因此不需要借助其他工具辅助转化,但存在词向量维度较大的问题。在文中,我们给出了生成藏头诗效果,同时作为拓展,使用训练好的网络也可以生成古诗。根据参数控制,我们可以指定生成七言或五言诗,实验结果表明我们搭建的LSTM网络能够高效地生成藏头诗,古诗。
在未进入深度学习时代,NLP也是一个蓬勃发展的领域。然而,在所有的上述任务中,我们都需要根据语言学的知识去做大量的,复杂的特征工程。如果你去学习这个领域,那么整个四年你都会在从事这方面的研究,比如音素,语素等等。在过去的几年中,深度学习的发展取得了惊人的进步,在一定程度上我们可以消除对语言学的依赖性。由于进入的壁垒降低了,NLP 任务的应用也成为了深度学习研究的一个重大的领域之一【1】。
今年,基于LSTM的系统可以学习翻译语言、控制机器人、图像分析、文档摘要、语音识别图像识别、手写识别、控制聊天机器人、预测疾病、点击率和股票、合成音乐等等任务【2】 【3】。在2017年,LSTM的提出人(Juergen Schmidhuber)团队做了一个统计,如图(1),LSTM网络在世界最有价值的五大公司的应用,统计表明当前在这五大公司的应用广泛【4】【5】。
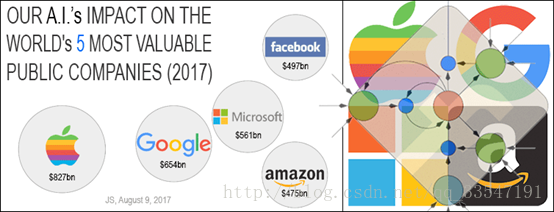
图1、LSTM网络在世界最有价值的五大公司的应用
继去年“机器学习生成恐怖图像”后,MIT研究人员在今年的万圣节推出了“AI写恐怖故事”的项目【6】,利用RNN和在线学习算法,结合Reddit上人类写的恐怖故事资料,生成恐怖故事,生成的句子包括“它的皮肤冰冷苍白,好像在我的肺里来回移动,试图留在我的灵魂里”。Shelley每小时就会在推特上写一个新的恐怖故事的开头,并以#yourturn(#该你了#)的话题标签邀请人类续写,然后Shelley会回复人类的续写,如此循环往复。
从上面的例子我们也可以看到循环神经网络在自然语言的应用潜力很大,但可以看到在自动生成小说时,还需要人类来丰富故事的内容,AI进行创作还是需要人类辅助。
基于LSTM的影评情感分析【7】采用的数据均是英文数据,而本文中特别地采用了中文数据,而且是古诗数据集,因此文中没有采用word-to-vector的方式,也没有采用结巴分词,这是受到古诗的特点制约的。也可以说是因为当前没有针对古诗的分词操作,因此从我们最后的生成结果可以看到生成的诗歌在形式上和古诗很相似,当时在意境上还有很大的欠缺。这一章主要介绍当前LSTM的应用背景,下面介绍本文采用的LSTM结构 。
一、LSTM网络结构
人类并不是每时每刻都从头开始思考。正如你阅读这篇文章的时候,你是在理解前面词语的基础上来理解每个词。你不会丢弃所有已知的信息而从头开始思考。你的思想具有持续性。这正是循环神经网络在自然语言处理的优势,自然语句正好也是循环神经网络的链式结构,完美契合。
在介绍LSTM网络之前,需要先介绍一般的循环神经网络(RNN),结构如图(2)。
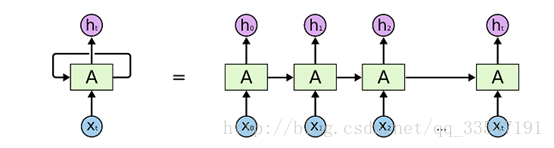

图2、普通的循环神经网络结构
在程序中运行时,循环神经网络采用的是参数共享的方式,也就是实际上一层循环神经网络只有一个cell(图中的A区域),在深入学习研究之后,发现cell内部存在的权重也是在训练的,但这部分权重不需要程序员去定义,而且也不能直接查看,而在模型加载时会加载这部分权值,这是循环神经网络和卷积神经网络很大的一个区别。
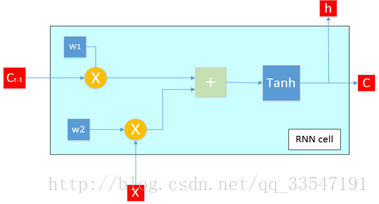
图3、RNN cell结构
从图(3)我们给出了当循环神经网络输入数据维度为一维,内部单元数只有一个时的cell内部结构。该图详细阐述了RNN内部的参数传递。图四是当输入数据维度变为2,cell内部单元数增加为2时的结构,从结构图中可以看到单元之间数据是独立的而每个单元的上一个状态是之间cell内部每个单元的状态集合。也就是单元之前看似独立又相互联系。

图4、增加单元后循环神经网络结构
而我们使用的LSTM网络和循环神经网络也是采用的链式结构,只是在cell内部设计更为复杂,LSTM在结构上增加了三个门,包括输入门,遗忘门,输出门,这是流行的解释,个人觉得也可以理解为四个门,因为结构中权重主要四个部分,激活函数也为4个。LSTM内部参数较多,但是参数之间的联系紧密。
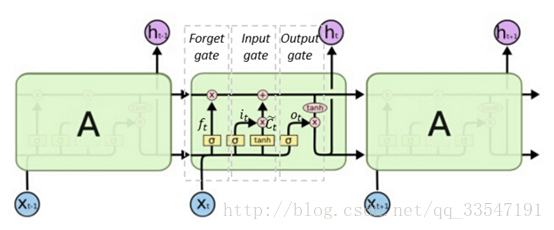
图5、LSTM主要结构
RNN 的关键点之一就是他们可以用来连接先前的信息到当前的任务上,例如使用过去的视频段来推测对当前段的理解。如果 RNN 可以做到这个,他们就变得非常有用。有时候,我们仅仅需要知道先前的信息来执行当前的任务。例如,我们有一个语言模型用来基于先前的词来预测下一个词。如果我们试着预测“the clouds are in the sky” 最后的词,我们并不需要任何其他的上下文 —— 因此下一个词很显然就应该是 sky。在这样的场景中,相关的信息和预测的词位置之间的间隔是非常小的,RNN 可以学会使用先前的信息。
但是同样会有一些更加复杂的场景。假设我们试着去预测“I grew up inFrance... I speak fluent French”最后的词。当前的信息建议下一个词可能是一种语言的名字,但是如果我们需要弄清楚是什么语言,我们是需要先前提到的离当前位置很远的 France 的上下文的。这说明相关信息和当前预测位置之间的间隔就肯定变得相当的大。不幸的是,在这个间隔不断增大时,RNN 会丧失学习到连接如此远的信息的能力。
LSTM是一种 RNN 特殊的类型,可以学习长期依赖信息。LSTM 由Hochreiter & Schmidhuber【8】提出,并在近期被Alex Graves【9】进行了改良和推广。在很多问题,LSTM 都取得相当巨大的成功,并得到了广泛的使用。LSTM 通过刻意的设计来避免长期依赖问题。记住长期的信息在实践中是 LSTM 的默认行为,而非需要付出很大代价才能获得的能力!所有 RNN 都具有一种重复神经网络模块的链式的形式。在标准的 RNN 中,这个重复的模块只有一个非常简单的结构,例如一个 tanh 层。
LSTM 的关键就是细胞状态,水平线在图上方贯穿运行。细胞状态类似于传送带。直接在整个链上运行,只有一些少量的线性交互。信息在上面流传保持不变会很容易。LSTM 有通过精心设计的称作为“门”的结构来去除或者增加信息到细胞状态的能力。门是一种让信息选择式通过的方法【10】。他们包含一个 sigmoid 神经网络层和一个 pointwise 乘法操作。Sigmoid 层输出 0 到 1 之间的数值,描述每个部分有多少量可以通过。0 代表“不许任何量通过”,1 就指“允许任意量通过”!LSTM 拥有三个门,来保护和控制细胞状态。
遗忘门:
在我们 LSTM 中的第一步是决定我们会从细胞状态中丢弃什么信息。这个决定通过一个称为忘记门层完成。该门会读取 h_{t-1} 和 x_t,输出一个在0 到 1 之间的数值给每个在细胞状态 C_{t-1} 中的数字。1 表示“完全保留”,0 表示“完全舍弃”。让我们回到语言模型的例子中来基于已经看到的预测下一个词。在这个问题中,细胞状态可能包含当前主语的性别,因此正确的代词可以被选择出来。当我们看到新的主语,我们希望忘记旧的主语。
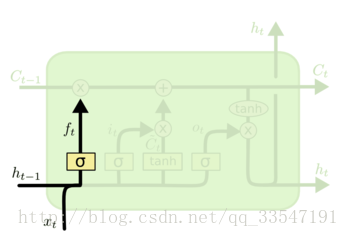
图6、LSTM内部遗忘门
输入门:
下一步是确定什么样的新信息被存放在细胞状态中。这里包含两个部分。第一,sigmoid 层称“输入门层” 决定什么值我们将要更新。然后,一个 tanh 层创建一个新的候选值向量,\tilde{C}_t,会被加入到状态中。下一步,我们会讲这两个信息来产生对状态的更新。
在我们语言模型的例子中,我们希望增加新的主语的性别到细胞状态中,来替代旧的需要忘记的主语。

图7、LSTM内部输入门
输出门:
最终,我们需要确定输出什么值。这个输出将会基于我们的细胞状态,但是也是一个过滤后的版本。首先,我们运行一个 sigmoid 层来确定细胞状态的哪个部分将输出出去。接着,我们把细胞状态通过tanh 进行处理(得到一个在 -1 到 1 之间的值)并将它和 sigmoid 门的输出相乘,最终我们仅仅会输出我们确定输出的那部分。在语言模型的例子中,因为他就看到了一个 代词,可能需要输出与一个动词 相关的信息。例如,可能输出是否代词是单数还是负数,这样如果是动词的话,我们也知道动词需要进行的词形变化。
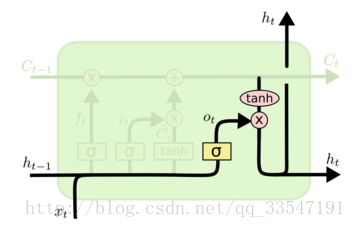
图8、LSTM内部输出门
介绍完LSTM的结构,对于LSTM的原理有一个比较清晰的认识时候,接下来介绍如何使用LSTM网络。
二、数据预处理
本文藏头诗自动生成采用的是全唐诗,一共包含34646首唐诗。数据格式为诗歌名加上诗歌内容,如图(9)。所有诗歌存放在一个txt文档中,每一行存储一首诗。

图9、数据集简介
数据预处理的过程,实际上是文本处理的过程,先对诗歌进行拆分,提取诗歌内容。步骤包括数据清洗、统计词频、生成字库、根据字库把每一首诗转化为一个向量。
1.进行原始数据清洗(这里只进行去除诗歌题目)

图10、诗歌数据清洗
2.统计词频。(诗歌中就是统计字频,下面只是小样本测试)

3.根据词频排序,生成字库

4根据字库把每一首诗转化为一个向量。(这个向量以字库中的汉字数作为维度,每个维度中通过0和1来表示这个汉字在这首诗中是否出现。)
该程序是使用词库法进行的数据处理。
One-hot编码:
本实验在转化为词向量的过程中采用的one-hot编码,在数据处理和特征工程中,经常会遇到类型数据,如性别分为[男,女],手机运营商分为[移动,联通,电信]等,我们通常将其转为数值带入模型,如[0,1], [-1,0,1]等,但模型往往默认为连续型数值进行处理,这样其实是违背我们最初设计的,也会影响模型效果。
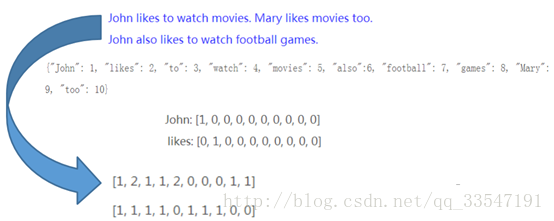
图11、one-hot编码实例
把唐诗转化为向量形式,接下里就可以输入LSTM网络进行训练了。
三、训练与模型生成
首先我们要训练好模型。这里采用的是2层的LSTM框架,每层有128个隐藏层节点,batch_size设为64。训练数据来源于全唐诗。训练参数:rnn_size=128,num_layers=2,batch_size = 64(每次取64首诗进行训练),Learning_rate=0.01。
图12、两层LSTM结构图
运行环境采用Linux系统,python2.7,tensorflow1.2.0。运行环境截图如图13()。
图13、运行环境
四、藏头诗生成效果
以美丽华中大为头生成的藏头诗:
五言诗:
美酒贱人少,上月同辞帷。
丽柳晴光禁,黄云敞照桥。
华丘相见去,罗晰得馀看。
中水复成泰,朱林测不通。
大颜之上安,二妃岂知情。
七言诗:
美妻不说秋来断,锁槛低头太阿扶。
丽藻昏昏不病身,疏花飘去使中春。
华桂三叫云火空,山僧荆棘得无痕。
中原风野客争摧,当死相思盛酒卮。
大牢头上马行人,延面香窗风外愁。
武汉别名江城,这哥别名源于李白的《与史郎中钦听黄鹤楼上吹笛》,一为迁客去长沙,西望长安不见家。黄鹤楼中吹玉笛,江城五月落梅花。镌刻于如今重建的黄鹤楼。下面以江城美景为头:
五言诗:
江焰红花里,风经雨起烟。
城西深夜后,叶满不胜经。
美洁漏将受,出门临碧池。
景间陪待罢,佳景尽依依。
七言诗:
江边树绿半堪山,八月西洲伴春色。
城郭花开雪满地,满江杨柳归何处。
美女尘中心自偶,远平一是子为珍。
景阳幽色最临声,此意浮风坐绕禅。
拓展部分(古诗生成)
古诗生成和藏头诗比较接近,差别在于藏头诗是指定一个字,然后使用训练好的LSTM网络预测每一句诗歌的内容。而生成古诗不指定诗歌内容(可以限定是5言或七言),诗歌第一个字有程序随机生成,然后接下来全部由LSTM网络生成,生成的诗歌长度也是不一定的。
五言诗:
花偏君亦长,一别少看花。
项小黔州路,天边山已深。
渡长淮河上,月夜南山分。
情世不可识,歌枝一少愁。
七言诗:
彼处闻寒溜泉频,竹峰蛛网木浓阴。
先生成性思成远,白发幽人事肯醒。
惟有月圆心便寝,起经徒到意无身。
跂襟藉笋丛青菊,声价同亲奈欲何。
五、总结与展望
本文设计了基于LSTM网络的藏头诗自动生成框架,文中详细介绍LSTM网络的结构以及原理,对数据预处理过程分为数据清洗、统计词频、生成字库、根据字库把每一首诗转化为一个向量。对于采用的one-hot编码原理,优缺点文中做了细致的分析。从最后的生成结果看,生成的藏头诗和古诗基本符合唐诗的形式,在诗歌意境方面还有很大的提升空间。
深入分析其原因,主要是One-hot方法很简单,但是它的问题也很明显:1)它没有考虑单词之间相对位置的关系;2)维度等于字库的总数,这种方法造成维度灾难。词向量可能非常非常长!因此可以采用分词法,比如说中文处理比较流行的结巴分词。然后对词进行编码。这样诗歌已经会有明显提高。同时也可以用LSTM网络生成小说等。这是未来可以完成的工作。