相关文件
关注小编,私信小编领取哟!
当然别忘了一件三连哟~~
公众号:Python日志
可以关注小编公众号,会不定时的发布一下Python小技巧,还有很多资源可以免费领取哟!!
源码领取:加Python学习交流群:773162165 可以领取哟
开发工具
Python版本:3.7.8
相关模块:
pytorch模块;
pyqt5模块;
numpy模块;
pyttsx3模块;
以及一些python自带的模块。
环境搭建
安装Python并添加到环境变量,pip安装需要的相关模块即可。
想用GPU完成模型训练的读者请自行搜索相关的网络教程配置CUDA环境,相关文件中会提供小编训练好的模型,因此你也可以直接下载使用。
效果展示
视频效果
Python基于神经网络自动生成“藏头诗”项目!
图片效果
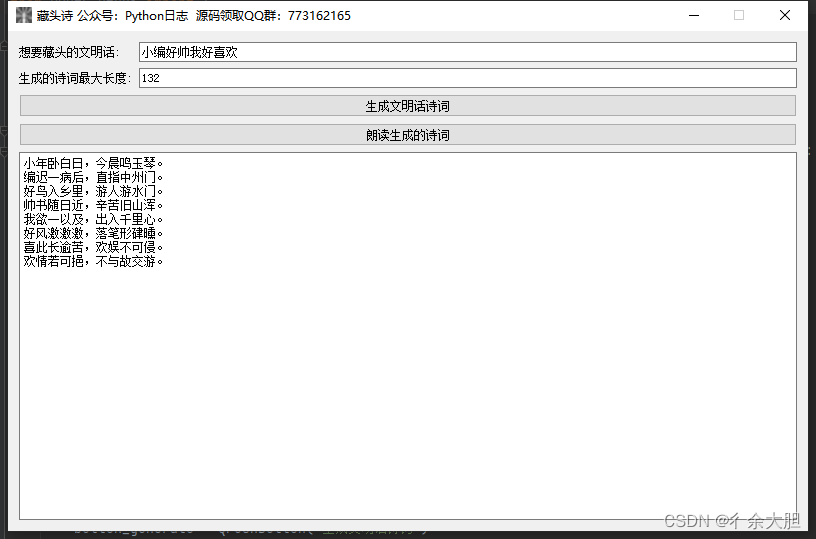
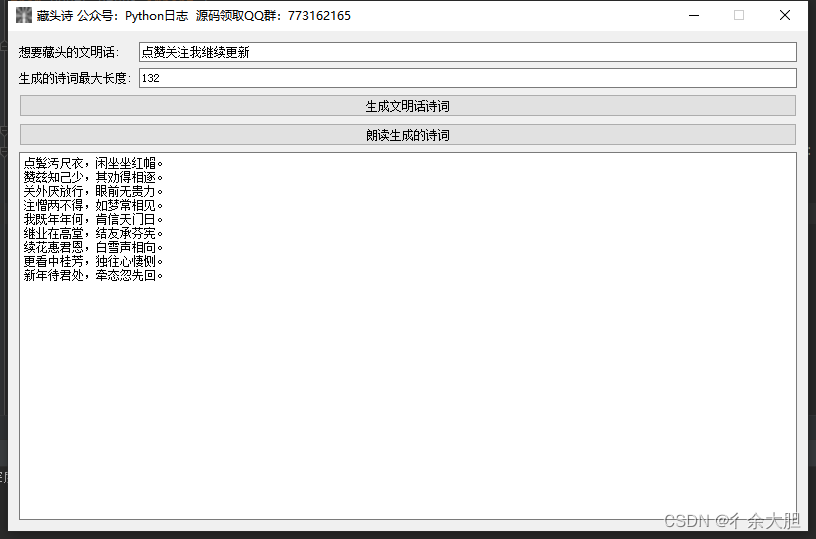
原理简介
这里我们用网上别人整理好的57580首唐诗作为训练数据集,先加载一下数据:
'''创建dataloader'''
def CreateDataloader(tang_resource_path, batch_size=16, num_workers=2):
poems = np.load(tang_resource_path, allow_pickle=True)
dataset = poems['data']
index2word = poems['index2word'].item()
word2index = poems['word2index'].item()
dataset = torch.from_numpy(dataset)
dataloader = torch.utils.data.DataLoader(
dataset, batch_size=batch_size, shuffle=True, num_workers=num_workers,
)
return dataloader, index2word, word2index
然后用pytorch定义一个简单的生成模型:
'''诗歌生成模型'''
class Poem(nn.Module):
def __init__(self, vocabulary_dim, embedding_dim=256, hidden_dim=512, num_layers=3):
super(Poem, self).__init__()
self.vocabulary_dim = vocabulary_dim
self.embedding_dim = embedding_dim
self.hidden_dim = hidden_dim
self.num_layers = num_layers
# 定义一些层
self.embedding = nn.Embedding(vocabulary_dim, embedding_dim)
self.lstm = nn.LSTM(embedding_dim, hidden_dim, num_layers=num_layers)
self.linear = nn.Linear(hidden_dim, vocabulary_dim)
'''forward'''
def forward(self, inputs, hidden=None):
seq_len, batch_size = inputs.size()
if hidden is None:
hidden = inputs.data.new(self.num_layers, batch_size, self.hidden_dim).fill_(0).float(), inputs.data.new(self.num_layers, batch_size, self.hidden_dim).fill_(0).float()
h_0, c_0 = hidden
embeds = self.embedding(inputs)
outputs, hidden = self.lstm(embeds, (h_0, c_0))
outputs = self.linear(outputs.view(seq_len * batch_size, -1))
return outputs, hidden
然后写个脚本训练一下:
'''藏头诗生成器'''
class Trainer():
def __init__(self, cmd_args):
self.cmd_args = cmd_args
'''run'''
def run(self):
# 初始化
use_cuda = torch.cuda.is_available()
rootdir = os.path.split(os.path.abspath(__file__))[0]
touchdir(self.cmd_args.ckptdir)
logger_handle = Logger(os.path.join(self.cmd_args.ckptdir, self.cmd_args.logfilepath))
# 创建数据集
tang_resource_path = os.path.join(rootdir, 'resources/tang.npz')
dataloader, index2word, word2index = CreateDataloader(tang_resource_path, self.cmd_args.batchsize, self.cmd_args.numworkers)
# 创建模型
model = Poem(len(word2index))
if use_cuda: model = model.cuda()
# 创建优化器
optimizer = torch.optim.Adam(model.parameters(), lr=self.cmd_args.lr)
# 创建损失函数
criterion = nn.CrossEntropyLoss()
# 开始训练
for epoch in range(1, self.cmd_args.epochs+1):
for batch_idx, data in enumerate(dataloader):
optimizer.zero_grad()
data = data.long().transpose(1, 0).contiguous()
if use_cuda: data = data.cuda()
inputs, targets = data[:-1, :], data[1:, :]
outputs = model(inputs)[0]
loss = criterion(outputs, targets.view(-1))
if (batch_idx + 1) % 10 == 0:
logger_handle.info(f'[Epoch]: {
epoch}/{
self.cmd_args.epochs}, [Batch]: {
batch_idx+1}/{
len(dataloader)}, [Loss]: {
loss.item()}')
loss.backward()
optimizer.step()
if epoch % self.cmd_args.saveinterval == 0 or epoch == self.cmd_args.epochs:
torch.save(model.state_dict(), os.path.join(self.cmd_args.ckptdir, f'epoch_{
epoch}.pth'))
好啦,大概的就是这样子实现的啦,源码领取看相关文件哟