基于LSTM的音乐生成学习全过程的总结
由于笔者日常酷爱唱歌,酷爱音乐,再加上现在是计算机专业硕士在读。也是这个假期确定下来要做人工智能音乐的方向,也就开始了我对AI音乐的学习。
从最基本的旋律生成开始,也就是基于LSTM的音乐生成。下面开始讲解学习全过程:
1.LSTM神经网络
LSTM单元的结构如图1所示(出自Christopher Olah的文章 Understanding LSTM Network)
图1:
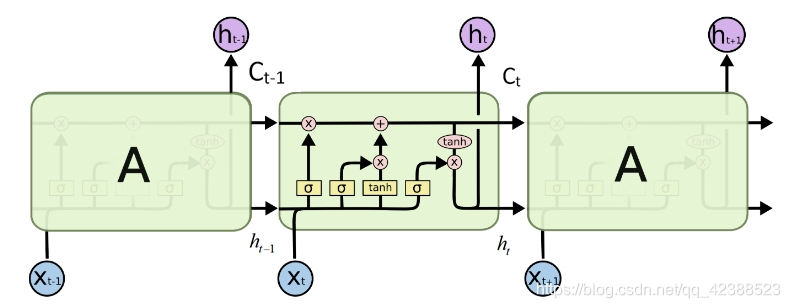
C是LSTM单元状态,代表长期记忆,随着时间步不断在隐藏层中传递;状态h代表短期记忆。单元状态在一条水平线上流通,只有少量线性交互,使得信息很容易保持。如图所示
图2:
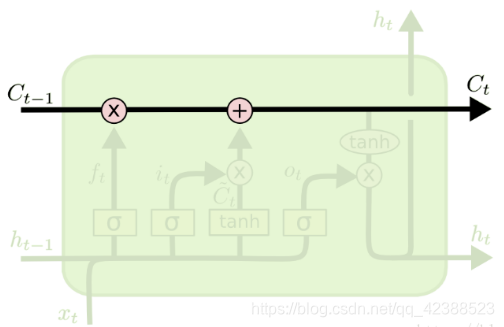
LSTM通过设计好的“门”,在单元状态上添加和去除信息,“门”来决定记住某些信息,或者忘记某些信息,隐藏层的状态从单元状态计算得到,然后继续传递。通常“门”包括遗忘门,输入门和输出门。
遗忘门,图3:
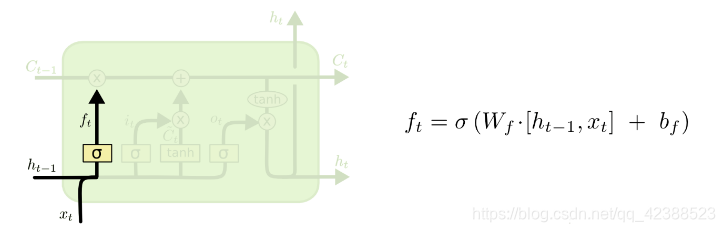
输入门,图4:
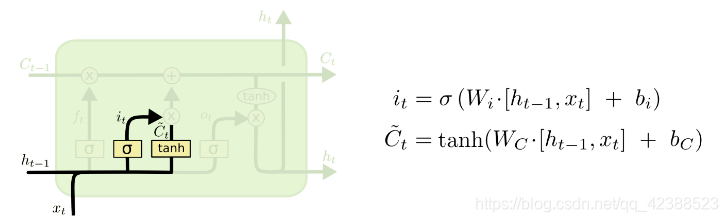
遗忘门和输入门计算好之后,更新单元状态C,图5:
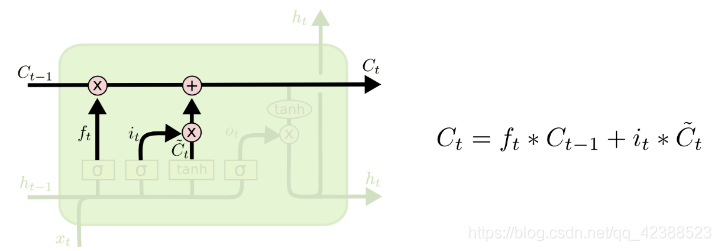
输出门,图6:
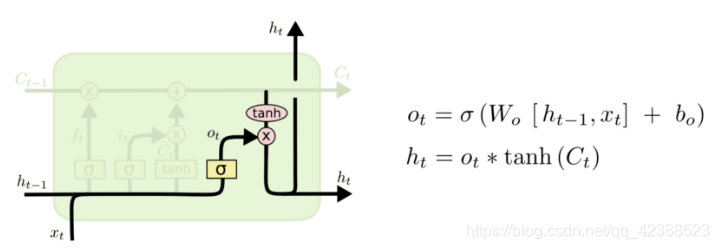
(注:由于各个门的介绍公式比较多,输入不太方便,我就选择了手写的方式)

这样通过几个控制门组成的LSTM单元,在整个梯度传递过程中是非常流畅的。因为在单元状态的传递过程中只有较少的线性求和运算,不再是大量的多层嵌套乘法,梯度在网络间的传递不会衰减。
此部分参考材料为:
程世东-深度学习私房菜-跟着案例学TensorFlow
2.MIDI简要介绍
音乐格式:
格式是音乐翻译过来的语言,为了让计算机能够看懂,我们采用的是midi格式(.mid)
MIDI是不同插电乐器,软件,设备的连接者和数码接口,关系着音符(Note)如何演奏
MIDI有音符序号,也就是音符的音高(pitch)
是一个整数集set={0,1,2,…,127}
音高和序号对应的表格如下:
 C4-60,A4-69,钢琴:A0-C8:21-108
C4-60,A4-69,钢琴:A0-C8:21-108
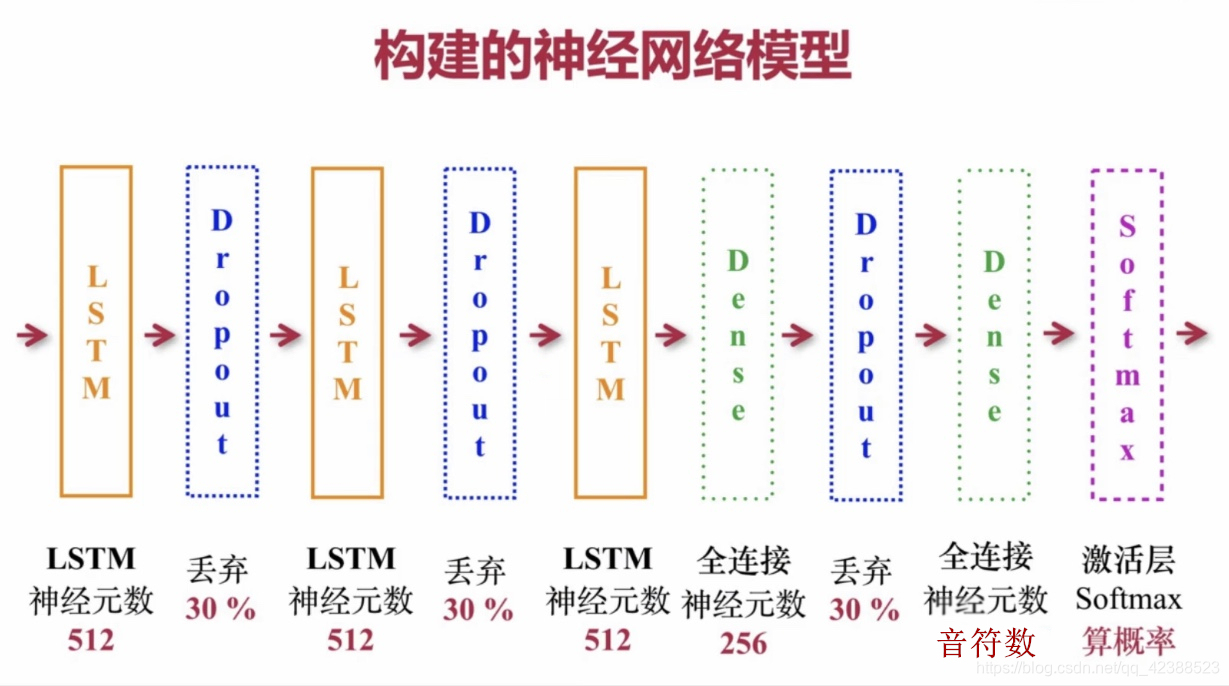
3.网络结构
1.网络结构如下:
激活层输出的结果,再用交叉熵的方式,将结果转化为百分比,取百分比最高的音符作为神经网络新生成的音符,下图中则取音符C

2.交叉熵公式如下:

该函数是凸函数,求导时能够得到全局最优值
学习过程如下:
交叉熵损失函数经常用于分类问题中,由于交叉熵涉及到计算每个类别的概率,所以交叉熵几乎每次都和sigmoid(或softmax)函数一起出现。
用神经网络最后一层输出的情况,整个模型预测、获得损失和学习的流程:
神经网络最后一层得到每个类别的得分scores;
该得分经过sigmoid(或softmax)函数获得概率输出;
模型预测的类别概率输出与真实类别的one hot形式进行交叉熵损失函数的计算。
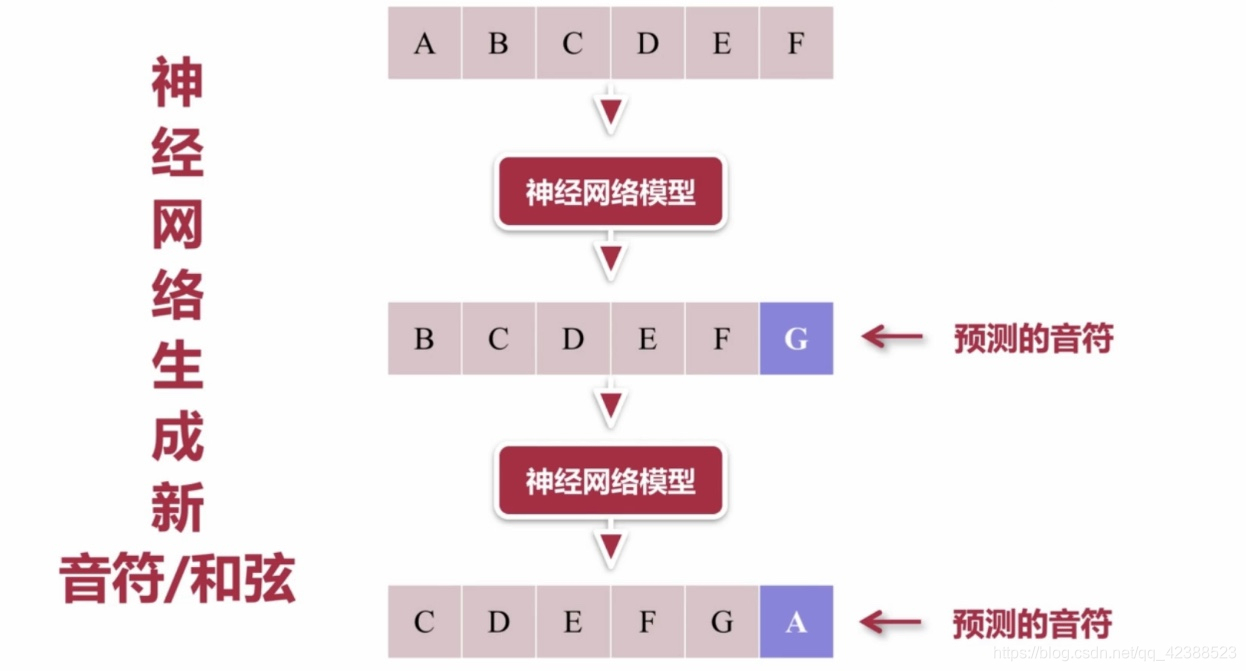
生成新音符/和弦的过程是:
音符序列—神经网络模型—预测1(序列左移一个,新预测的补在末尾)—神经网络模型—预测2
参考材料:
课程:基于Python玩转人工智能最火框架Tensorflow应用实践
交叉熵详解https://zhuanlan.zhihu.com/p/35709485
4.工具和代码详解
使用工具:
语言:Python
框架:Tensorflow2.0,Music21
IDE:VSCode,Jupyter notebook
打谱软件:MuseScore3.0
数据集:nottingham-dataset
全部代码及其注释如下:
network.py

#神经网络模型
#RNN-LSTM循环神经网络
import tensorflow as tf
#构建神经网络模型
def network_model(inputs,num_pitch,weights_file=None):#输入,音符的数量,训练后的参数文件
#测试时要指定weights_file
#建立模子
model=tf.keras.Sequential()
#第一层
model.add(tf.keras.layers.LSTM(
512,#LSTM层神经元的数目是512,也是LSTM层输出的维度
input_shape=(inputs.shape[1],inputs.shape[2]),#输入的形状,对于第一个LSTM必须设置
return_sequences=True#返回控制类型,此时是返回所有的输出序列
#True表示返回所有的输出序列
#False表示返回输出序列的最后一个输出
#在堆叠的LSTM层时必须设置,最后一层LSTM不用设置,默认值为False
))
#第二层和第三层
model.add(tf.keras.layers.Dropout(0.3))#丢弃30%神经元,防止过拟合
model.add(tf.keras.layers.LSTM(512,return_sequences=True))
model.add(tf.keras.layers.Dropout(0.3))#丢弃30%神经元,防止过拟合
model.add(tf.keras.layers.LSTM(512))#千万不要丢括号!!!!
#全连接层
model.add(tf.keras.layers.Dense(256))#256个神经元的全连接层
model.add(tf.keras.layers.Dropout(0.3))
model.add(tf.keras.layers.Dense(num_pitch))#输出的数目等于所有不重复的音调数
#激活层
model.add(tf.keras.layers.Activation('softmax'))#Softmax激活函数求概率
#配置神经网络模型
model.compile(loss='categorical_crossentropy',optimizer=tf.keras.optimizers.RMSprop(learning_rate=0.0004))
#选择的损失函数是交叉熵,用来计算误差。使用对于RNN来说比较优秀的优化器-RMSProp
#优化器如果使用字符串的话会用默认参数导致效果不好
if weights_file is not None:
model.load_weights(weights_file)#就把这些参数加载到模型中,weight_file本身是HDF5文件
return model
utils.py
import os
import subprocess
import pickle
import glob
from music21 import converter,instrument,note,chord,stream#converter负责转换,乐器,音符,和弦类
def get_notes():
"""
从music_midi目录中的所有MIDI文件里读取note,chord
Note样例:B4,chord样例[C3,E4,G5],多个note的集合,统称“note”
"""
notes=[]
for midi_file in glob.glob("music_midi/*.mid"):
#读取music_midi文件夹中所有的mid文件,file表示每一个文件
stream=converter.parse(midi_file)#midi文件的读取,解析,输出stream的流类型
#获取所有的乐器部分,开始测试的都是单轨的
parts=instrument.partitionByInstrument(stream)
if parts:#如果有乐器部分,取第一个乐器部分
notes_to_parse=parts.parts[0].recurse()#递归
else:
notes_to_parse=stream.flat.notes#纯音符组成
for element in notes_to_parse:#notes本身不是字符串类型
#如果是note类型,取它的音高(pitch)
if isinstance(element,note.Note):
#格式例如:E6
notes.append(str(element.pitch))
elif isinstance(element,chord.Chord):
#转换后格式:45.21.78(midi_number)
notes.append('.'.join(str(n) for n in element.normalOrder))#用.来分隔,把n按整数排序
# 如果 data 目录不存在,创建此目录
if not os.path.exists("data"):
os.mkdir("data")
#将数据写入data/notes
with open('data/notes','wb') as filepath:#从路径中打开文件,写入
pickle.dump(notes,filepath)#把notes写入到文件中
return notes#返回提取出来的notes列表
def create_music(prediction):#生成音乐函数,训练不用
""" 用神经网络预测的音乐数据来生成mid文件 """
offset=0#偏移,防止数据覆盖
output_notes=[]
#生成Note或chord对象
for data in prediction:
#如果是chord格式:45.21.78
if ('.' in data) or data.isdigit():#data中有.或者有数字
note_in_chord=data.split('.')#用.分隔和弦中的每个音
notes=[]#notes列表接收单音
for current_note in note_in_chord:
new_note=note.Note(int(current_note))#把当前音符化成整数,在对应midi_number转换成note
new_note.storedInstrument=instrument.Piano()#乐器用钢琴
notes.append(new_note)
new_chord=chord.Chord(notes)#再把notes中的音化成新的和弦
new_chord.offset=offset#初试定的偏移给和弦的偏移
output_notes.append(new_chord)#把转化好的和弦传到output_notes中
#是note格式:
else:
new_note=note.Note(data)#note直接可以把data变成新的note
new_note.offset=offset
new_note.storedInstrument=instrument.Piano()#乐器用钢琴
output_notes.append(new_note)#把new_note传到output_notes中
#每次迭代都将偏移增加,防止交叠覆盖
offset+=0.5
#创建音乐流(stream)
midi_stream=stream.Stream(output_notes)#把上面的循环输出结果传到流
#写入midi文件
midi_stream.write('midi',fp='output.mid')#最终输出的文件名是output.mid,格式是mid
train.py
#训练神经网络,将参数(weight)存入HDF5文件
import numpy as np
import tensorflow as tf
from network import *
from utils import *
def train():
notes=get_notes()
#得到所有不重复的音调数目
num_pitch=len(set(notes))
network_input,network_output=prepare_sequences(notes,num_pitch)
model=network_model(network_input,num_pitch)
#输入,音符的数量,训练后的参数文件(训练的时候不用写)
filepath="weights-{epoch:02d}-{loss:.4f}.hdf5"
#用checkpoint(检查点)文件在每一个Epoch结束时保存模型的参数
#不怕训练过程中丢失模型参数,当对loss损失满意的时候可以随时停止训练
checkpoint=tf.keras.callbacks.ModelCheckpoint(
filepath,#保存参数文件的路径
monitor='loss',#衡量的标准
verbose=0,#不用冗余模式
save_best_only=True,#最近出现的用monitor衡量的最好的参数不会被覆盖
mode='min'#关注的是loss的最小值
)
callbacks_list=[checkpoint]
#callback = tf.keras.callbacks.LearningRateScheduler(scheduler)
#用fit方法来训练模型
model.fit(network_input,network_output,epochs=90,batch_size=64,callbacks=callbacks_list)
#输入,标签(衡量预测结果的),轮数,一次迭代的样本数,回调
#model.save(filepath='./model',save_format='h5')
def prepare_sequences(notes,num_pitch):
#从midi中读取的notes和所有音符的数量
"""
为神经网络提供好要训练的序列
"""
sequence_length=100#序列长度
#得到所有不同音高的名字
pitch_names=sorted(set(item for item in notes))
#把notes中的所有音符做集合操作,去掉重复的音,然后按照字母顺序排列
#创建一个字典,用于映射 音高 和 整数
pitch_to_int=dict((pitch,num)for num,pitch in enumerate(pitch_names))
#枚举到pitch_name中
#创建神经网络的输入序列和输出序列
network_input=[]
network_output=[]
for i in range(0,len(notes)-sequence_length,1):#循环次数,步长为1
sequence_in=notes[i:i+sequence_length]
#每次输入100个序列,每隔长度1取下一组,例如:(0,100),(1,101),(50,150)
sequence_out=notes[i+sequence_length]
#真实值,从100开始往后
network_input.append([pitch_to_int[char] for char in sequence_in])#列表生成式
#把sequence_in中的每个字符转为整数(pitch_to_int[char])放到network_input
network_output.append(pitch_to_int[sequence_out])
#把sequence_out的一个字符转为整数
n_patterns=len(network_input)#输入序列长度
#将输入序列的形状转成神经网络模型可以接受的
network_input=np.reshape(network_input,(n_patterns,sequence_length,1))
#输入,要改成的形状
#将输入标准化,归一化
network_input=network_input/float(num_pitch)
#将期望输出转换成{0,1}布尔矩阵,配合categorical_crossentrogy误差算法的使用
network_output=tf.keras.utils.to_categorical(network_output)
#keras中的这个方法可以将一个向量传进去转成布尔矩阵,供交叉熵的计算
return network_input,network_output
if __name__ == '__main__':
train()
generate.py
import pickle
import numpy as np
import tensorflow as tf
from network import *
from utils import *
"""
用训练好的神经网络模型参数来作曲
"""
#以之前所得的最佳参数来生成音乐
def generate():
#加载用于训练神经网络的音乐数据
with open('data/notes','rb') as filepath:#以读的方式打开文件
notes=pickle.load(filepath)
#得到所有不重复的音符的名字和数目
pitch_names=sorted(set(item for item in notes))
num_pitch=len(set(notes))
network_input,normalized_input=prepare_sequences(notes,pitch_names,num_pitch)
#载入之前训练是最好的参数(最小loss),来生成神经网络模型
model=network_model(normalized_input,num_pitch,"weights-90-0.1344.hdf5")
#用神经网络来生成音乐数据
prediction=generate_notes(model,network_input,pitch_names,num_pitch)
#用预测的音乐数据生成midi文件
create_music(prediction)
def prepare_sequences(notes,pitch_names,num_pitch):
#从midi中读取的notes和所有音符的数量
"""
为神经网络提供好要训练的序列
"""
sequence_length=100#序列长度
#创建一个字典,用于映射 音高 和 整数
pitch_to_int=dict((pitch,num)for num,pitch in enumerate(pitch_names))
#枚举到pitch_name中
#创建神经网络的输入序列和输出序列
network_input=[]
network_output=[]
for i in range(0,len(notes)-sequence_length,1):#循环次数,步长为1
sequence_in=notes[i:i+sequence_length]
#每次输入100个序列,每隔长度1取下一组,例如:(0,100),(1,101),(50,150)
sequence_out=notes[i+sequence_length]
#真实值,从100开始往后
network_input.append([pitch_to_int[char] for char in sequence_in])#列表生成式
#把sequence_in中的每个字符转为整数(pitch_to_int[char])放到network_input
network_output.append([pitch_to_int[sequence_out]])
#把sequence_out的一个字符转为整数
n_patterns=len(network_input)#输入序列长度
#将输入序列的形状转成神经网络模型可以接受的
normalized_input=np.reshape(network_input,(n_patterns,sequence_length,1))
#输入,要改成的形状
#将输入标准化,归一化
normalized_input=normalized_input/float(num_pitch)
return (network_input,normalized_input)
def generate_notes(model,network_input,pitch_names,num_pitch):
"""
基于序列音符,用神经网络来生成新的音符
"""
#从输入里随机选择一个序列,作为“预测”/生成的音乐的起始点
start=np.random.randint(0,len(network_input)-1)#从0到神经网络输入-1中随机选择一个整数
#创建一个字典用于映射 整数 和 音调,和训练相反的操作
int_to_pitch=dict((num,pitch) for num,pitch in enumerate(pitch_names))
pattern=network_input[start]#随机选择的序列起点
#神经网络实际生成的音符
prediction_output=[]
#生成700个音符
for note_index in range(700):
prediction_input=np.reshape(pattern,(1,len(pattern),1))
#输入,归一化
prediction_input=prediction_input/float(num_pitch)
#读取参数文件,载入训练所得最佳参数文件的神经网络来预测新的音符
prediction=model.predict(prediction_input,verbose=0)#根据输入预测结果
#argmax取最大的那个维度(类似One-hot编码)
index=np.argmax(prediction)
result=int_to_pitch[index]
prediction_output.append(result)
#start往后移动
pattern.append(index)
pattern=pattern[1:len(pattern)]
return prediction_output
if __name__ == '__main__':
generate()
注:
Batch_size为批次(样本)数目,也就是一次迭代用多少样本,Batch_size越大,所需要的内存也就越大。
Forward(前馈)用于得到损失函数的值
BackPropagation(反向传播)用于更新神经网络参数
Iteration:迭代,每次迭代更新一次权重(参数)
Epoch:所有的训练样本完成一次迭代,叫做完成1各Epoch
所以加入有1000个样本,如果Batch_size=10,训练完成需要100次迭代,为一个Epoch
我们可以通过更改Epoch参数来确定我们训练的轮数,更改Batch_size可以确定一次迭代多少样本。
数目越大对电脑性能要求越高。
5.实验结果
实验一:训练单旋律
导入1003条单旋律
Epoch=40,Batch_size=64,learning_rate=0.0005
最终的Loss=0.1512
我保存了4个最优的模型
然后将最优模型导入生成了3段音乐

将.mid拖入到Musescore3软件中,可视化乐谱

生成片段为一段较欢快的D大调,有一定的可听性,旋律轻快而且清晰。
实验二:训练纯和弦:
导入1003条纯和弦
Epoch=40,Batch_size=64,learning_rate=0.0005
最终的Loss=0.1151
将模型拖入软件:

发现只训练和弦并不具备可听性,尽管有和弦变化。所以接下来的大量训练是训练旋律,和弦加在一起的音乐。分别训练了50轮和90轮进行比较。
实验三:训练旋律+和弦
①导入1034条旋律+和弦
Epoch=50,Batch_size=64,learning_rate=0.0004
最终的Loss=0.1866
Loss随Epoch的变化图如下:
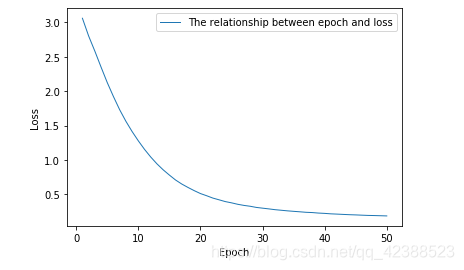
②导入1034条旋律+和弦
Epoch=90,Batch_size=64,learning_rate=0.0005
最终的Loss=0.1351
Loss随Epoch的变化图如下:
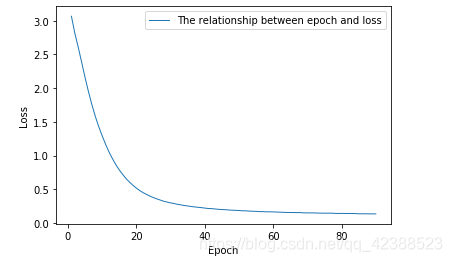
训练90轮之后,我保存了所有的模型:

训练的过程中Loss值是逐渐下降的,如果出现Loss没有下降的Epoch,此时该轮训练的模型不会保存。
将最优模型导入,生成了新的.mid文件,拖入Musescore3当中:

生成的是欢快的G大调,旋律与和弦在一起,也具有很不错的可听性。
6.总结
实验三中为什么将学习率改为0.0004?
其实我在训练实验一的时候开始遇到的问题就是Loss值从前几轮训练开始就一直不下降。从网上了解是学习率过高的问题,通过查找API,把默认的0.001改为了0.0005。后来0.0005在实验三中过高,改为0.0004后效果恢复
下图为:学习率对Loss的影响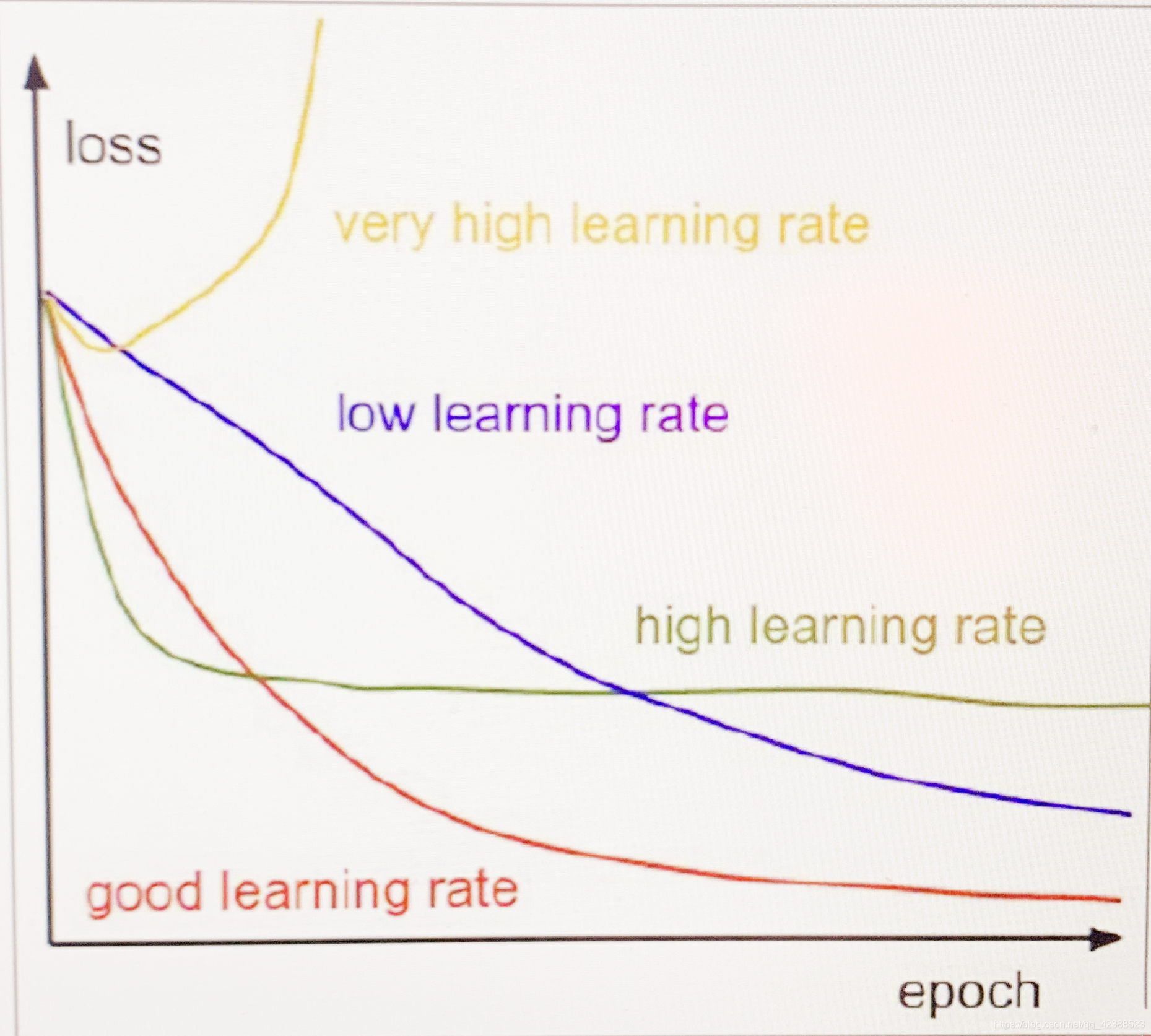
我没有用训练50轮的模型生成一段音乐,但是通过其他实验推测,50轮生成出的音乐也会具有可听性。从训练数据来看,训练90相比50轮Loss还是降到了更低,到70多轮的时候出现过Loss不下降的情况,可以推测训练90轮接近收敛。只是LSTM的训练成本相对较大,训练50轮1034条音乐要5个半小时,90轮花费了近10个半小时!而且现在的网络结构只有3层LSTM。
现在还是有很多可以改进的地方,比如我使用的数据集是钢琴谱,具有多轨道。但是生成出的结果是多轨道的音聚集在了单轨道,这是目前这个项目的局限性之一。还有就是此时的音乐生成是随机的,没有约束一定的规则。接下来也将以这两个点继续探索音乐生成领域,再看看网络模型是否可以再做进一步的调整。
