版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/Greepex/article/details/85790861
GAN基本概念
1,GAN:生成式对抗网络,在2014年提出的一种无监督深度学习模型。
2,GAN模型组成:
生成模型G(Generative Model)和判别模型D(Discriminative Model)
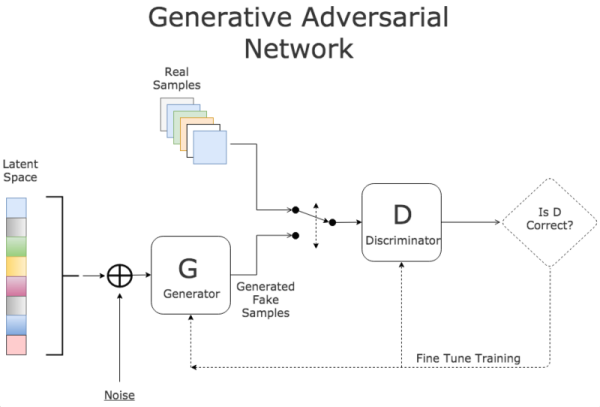
由该图可以知道很多的问题:
首先G模型和D模型一般都是神经网络;
可以理解为函数G(z)和D(x),其中z为噪声,x为判别对象;
损失函数分为G_loss和D_loss,分别是生成模型的损失函数和判别模型的损失函数;
G_loss:

而在tensorflow中的代码为:
G_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=D_logit_fake, labels=tf.ones_like(D_logit_fake)))
D_loss:
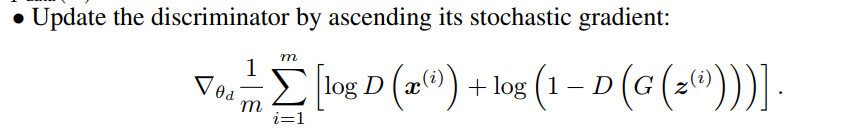
同时,在tensorflow中的代码为:
D_loss_real = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits = D_logit_real, labels=tf.ones_like(D_logit_real)))
D_loss_fake = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits = D_logit_fake, labels=tf.zeros_like(D_logit_fake)))
D_loss = D_loss_real + D_loss_fake
3,从简单GAN源码中学习GAN(手写数字):
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
import os
#读入数据
mnist = input_data.read_data_sets('./mnist', one_hot=True)#代码和数据集文件夹放在同一目录下
def sample_z(m,n):
# 均匀分布 np.randow.uniform(low, high,size)
# 正太分布 np.randow.normal(loc=0, scale=1, size) 即正太分布的N(0,1)
return np.random.uniform(-1.,1.,size=[m,n])
# 生成模型输入和参数初始化
Z = tf.placeholder(tf.float32, shape=[None, 100])
# xavier_init()是一种很有效的神经网络初始化方法:自编码器
# def xavier_init(fan_in, fan_out, constant = 1):
# low = -constant * np.sqrt(6.0 / (fan_in + fan_out))
# high = constant * np.sqrt(6.0 / (fan_in + fan_out))
# return tf.random_uniform((fan_in, fan_out),minval=low, maxval=high, dtype=tf.float32)
G_W1 = tf.get_variable("G_W1", shape=[100,128],initializer=tf.contrib.layers.xavier_initializer())
G_b1= tf.Variable(tf.zeros(shape=[128]))
G_W2 = tf.get_variable("G_W2", shape=[128,784],initializer=tf.contrib.layers.xavier_initializer())
G_b2= tf.Variable(tf.zeros(shape=[784]))
theta_G = [G_W1, G_W2, G_b1, G_b2]
# 生成模型
def Gene(Z):
G_h1 = tf.nn.relu(tf.matmul(Z, G_W1)+G_b1)
G_log_prob = tf.matmul(G_h1, G_W2)+G_b2
return tf.nn.sigmoid(G_log_prob)
# 判别模型输入和参数初始化
X = tf.placeholder(tf.float32, shape=[None, 784])
D_W1 = tf.get_variable("D_W1", shape=[784,128],initializer=tf.contrib.layers.xavier_initializer())
D_b1= tf.Variable(tf.zeros(shape=[128]))
D_W2 = tf.get_variable("D_W2", shape=[128,1],initializer=tf.contrib.layers.xavier_initializer())
D_b2= tf.Variable(tf.zeros(shape=[1]))
theta_D = [D_W1, D_W2, D_b1, D_b2]
# 判别模型
def Disc(x):
D_h1 = tf.nn.relu(tf.matmul(x, D_W1)+D_b1)
D_logit = tf.matmul(D_h1, D_W2)+D_b2
D_prob = tf.nn.sigmoid(D_logit)
return D_prob, D_logit
#画图函数
def plot(samples):
fig = plt.figure(figsize=(4, 4))
gs = gridspec.GridSpec(4, 4)
gs.update(wspace=0.05, hspace=0.05)
for i, sample in enumerate(samples):
ax = plt.subplot(gs[i])
plt.axis('off')
ax.set_xticklabels([])
ax.set_yticklabels([])
ax.set_aspect('equal')
plt.imshow(sample.reshape(28, 28), cmap='Greys_r')
return fig
# 数据运算
G_sample = Gene(Z)
D_real, D_logit_real = Disc(X)
D_fake, D_logit_fake = Disc(G_sample)
# 计算G和D的损失(loss)
#交叉熵(度量两个概率分布间的差异性信息)
D_loss_real = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits = D_logit_real, labels=tf.ones_like(D_logit_real)))
D_loss_fake = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits = D_logit_fake, labels=tf.zeros_like(D_logit_fake)))
D_loss = D_loss_real + D_loss_fake
G_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=D_logit_fake, labels=tf.ones_like(D_logit_fake)))
#AdamOptimizer()默认学习率为0.001
D_solver = tf.train.AdamOptimizer(0.0001).minimize(D_loss,var_list=theta_D)
G_solver = tf.train.AdamOptimizer(0.0001).minimize(G_loss, var_list=theta_G)
if not os.path.exists('out/'):
os.makedirs('out/')
i=0
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
mb_size = 128
Z_dim = 100
for it in range(1000000):
if it % 1000 == 0:
samples = sess.run(G_sample, feed_dict={Z: sample_z(16, Z_dim)})
fig = plot(samples)
plt.savefig('out/{}.png'.format(str(i).zfill(3)), bbox_inches='tight')
i += 1
plt.close(fig)
X_mb, _ = mnist.train.next_batch(mb_size)
_, D_loss_curr = sess.run([D_solver, D_loss], feed_dict={X: X_mb, Z: sample_z(mb_size, Z_dim)})
_, G_loss_curr = sess.run([G_solver, G_loss], feed_dict={Z: sample_z(mb_size, Z_dim)})
if it % 1000 == 0:
print('Iter: {}'.format(it),'D loss: {}'.format(D_loss_curr),'G_loss: {}'.format(G_loss_curr))
4,应用案例
- 计算机视觉:生成图像、风格迁移、生成模型等。
- 自然语言处理:对话系统、诗歌生成、机器翻译、中文分词、文本分类等。
- 常用GAN:DCGAN、CGAN、InfoGAN、WGAN、VAGAN。