Generative Adversarial Nets
导读
GAN通过一个对抗过程同时训练两个模型,一个模型是G生成模型,另一个是分类模型D,D用来判别生成样本是来自于真实的样本还是来自于虚构的样本,训练G的过程是为了让D犯错的概率最大,也就是D无法判断是生成的还是真是的样本
我们给的G和D空间有一个唯一解存在,G能完全恢复训练样本分布,D遇到任何样本输出都是1/2
对抗网络更像是训练框架,没有规定G和D一定是DNN的
We train D to maximize the probability of assigning the
correct label to both training examples and samples from G.
D训练目标是1标注真实样本,0标注虚假样本
We simultaneously train G to minimize log(1 − D(G(z)))
log(1 − D(G(z)))达到最小,也就是让G输出输入到D的输出结果达到1,也就是虚假样本能欺骗D
价值函数公式:x是来自真实样本,pz是随机噪声
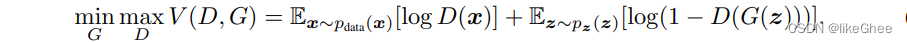
算法流程:
超参数k,先训练k步判别器,再训练一步生成器
首先对epoch循环
对k循环,从噪声z中采样构成噪声样本,从真实的样本中拿出样本x,基于梯度下降公式更新判别器的参数θd
进行完k步后,再取噪声样本输入生成器,根据梯度下降公式更新生成器的参数θg
证明部分:
定理1,最优的D的公式为:
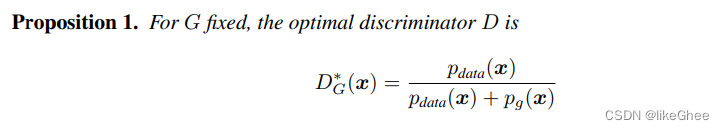
证明最优判断器公式

根据刚刚证明带入到最大价值函数C(G)中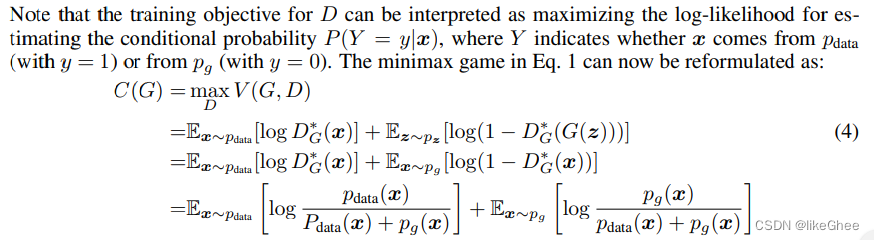
预测predictionG和预测predictionData相等时,根据D*公式,判别器输出为1/2,替换C(G)的 D* 变量,输出C(G) = -log 4
实验部分:
无监督MNIST,很多张手写数字照片,通过GAN希望学习到手写数字图像分布,随机生成高斯变量,生成器就能生成一张手写数字照片
论文地址
https://proceedings.neurips.cc/paper/2014/file/5ca3e9b122f61f8f06494c97b1afccf3-Paper.pdf
基于MNIST实现GAN
实现分成几个部分
导入MNIST训练集部分
generator部分,discrimination部分
构建优化器部分,我们需要两个优化器,分别对生成器和判别器进行优化
导入数据集
使用tv.datasets.MNIST,传入根目录和参数,再用dataloader构成批样本数据
import torch.utils.data
import torchvision
import torchvision as tv
batch_size_train = 64
batch_size_test = 64
"""MNIST"""
# 导入训练集
train_dataset = tv.datasets.MNIST('../data/',
train=True,
download=True,
transform=torchvision.transforms.Compose([
# PIL Image或者np数组转化为0~1之间的Tensor
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((0.1307,), (0.3081,))
]))
# print(train_dataset.data.shape) # torch.Size([60000, 28, 28])
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size_train, shuffle=True)
# 导入测试集
test_dataset = tv.datasets.MNIST('../data/',
train=False,
download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,), (0.3081,))
]))
# print(test_dataset.data.shape) # torch.Size([10000, 28, 28])
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size_test, shuffle=True)
if __name__ == '__main__':
x, y = next(iter(train_loader))
print(x.shape, y.shape) # torch.Size([64, 1, 28, 28]) torch.Size([64])
Generator
用DNN构建,forward传入噪声z
import torch
import torch.nn as nn
import torch.utils.data
import numpy as np
class Generator(nn.Module):
def __init__(self, image_size: list):
"""
image_size = [1, 28, 28]
"""
super().__init__()
self.image_size = image_size
in_dim = out_dim = int(np.prod(image_size))
self.model = nn.Sequential(
nn.Linear(in_dim, 64),
nn.ReLU(inplace=True),
nn.Linear(64, 128),
nn.ReLU(inplace=True),
nn.Linear(128, 256),
nn.ReLU(inplace=True),
nn.Linear(256, 512),
nn.ReLU(inplace=True),
nn.Linear(512, 1024),
nn.ReLU(inplace=True),
nn.Linear(1024, out_dim),
nn.Tanh()
)
def forward(self, z):
"""
z: noise, shape = [bs, 1 * 28 * 28]
return:
image.shape = [bs, c, h, w]
"""
output = self.model(z)
images = output.reshape([z.shape[0], *self.image_size])
return images
def test_main():
bs, c, h, w = 2, 1, 28, 28
image_size = [c, h, w]
inputx = torch.randn([bs, h * w])
res = Generator(image_size)(inputx)
print(res.shape)
if __name__ == '__main__':
test_main()
Discriminator
import torch
import torch.nn as nn
import numpy as np
class Discriminator(nn.Module):
def __init__(self, image_size: list):
"""
image_size: list = [c, h, w]
"""
super().__init__()
self.image_size = image_size
in_dim = int(np.prod(image_size))
self.model = nn.Sequential(
nn.Linear(in_dim, 1024),
nn.ReLU(inplace=True),
nn.Linear(1024, 512),
nn.ReLU(inplace=True),
nn.Linear(512, 256),
nn.ReLU(inplace=True),
nn.Linear(256, 128),
nn.ReLU(inplace=True),
nn.Linear(128, 64),
nn.ReLU(inplace=True),
nn.Linear(64, 1),
# 输出是个sigmoid概率 0~1
nn.Sigmoid()
)
def forward(self, images):
"""
images.shape = [bs, c , h , w]
return:
probability.shape = [bs, 1]
"""
probability = self.model(images.reshape(images.shape[0], -1))
return probability
def test_main():
bs, c, h, w = 2, 1, 28, 28
d = Discriminator([c, h, w])
inputx = torch.randn([bs, c, h, w])
prob = d(inputx)
print(prob.shape)
if __name__ == '__main__':
test_main()
优化器
我们使用Adam优化器
loss_fn选择二元交叉熵函数BCE
import torch
import generator
import discriminator
def g_optimizer(g_model: generator.Generator, lr=0.0001):
return torch.optim.Adam(g_model.parameters(), lr=lr)
def d_optimizer(d_model: discriminator.Discriminator, lr=0.0001):
return torch.optim.Adam(d_model.parameters(), lr=lr)
loss_fn = torch.nn.BCELoss()
训练部分
遍历epoch,遍历dataloader,定义loss_fn,开始训练
import torch
import torchvision
from tqdm import tqdm
import mnist
import generator
import discriminator
import optimizier
import os
import torchvision.transforms.functional
import unnorm
num_epoch = 10
# 对于生成模型的噪声维度一般用latent_dim表示
latent_dim = 64
image_size = [1, 28, 28]
# 每隔多少步保存一次照片
per_step_save_picture = 500
g_model = generator.Generator(latent_dim, image_size)
d_model = discriminator.Discriminator(image_size)
g_optim = optimizier.get_g_optimizer(g_model)
d_optim = optimizier.get_d_optimizer(d_model)
g_model_save_path = "save/g_model/model.pt"
d_model_save_path = "save/d_model/model.pt"
if os.path.exists(g_model_save_path) and os.path.exists(d_model_save_path):
g_model.load_state_dict(torch.load(g_model_save_path))
d_model.load_state_dict(torch.load(d_model_save_path))
print("#### 成功载入已有模型,进行追加训练...")
num_train_per_epoch = mnist.train_loader.sampler.num_samples // mnist.batch_size_train
for epoch in range(num_epoch):
print(f"当前epoch:{
epoch}")
print("保存模型中")
torch.save(g_model.state_dict(), os.path.join(g_model_save_path))
torch.save(d_model.state_dict(), os.path.join(d_model_save_path))
for i, mini_batch in tqdm(enumerate(mnist.train_loader), total=num_train_per_epoch):
ground_truth_images, _ = mini_batch
bs = ground_truth_images.shape[0]
# 随机生成z
z = torch.randn([bs, latent_dim])
# 送入生成器模型
pred_images = g_model(z)
# 对生成器进行优化
g_optim.zero_grad()
label_ones = torch.ones([bs, 1])
# 计算生成器模型loss
# 我们希望生成器输出的虚构照片输进d后尽可能为1
g_loss = optimizier.loss_fn(d_model(pred_images), label_ones)
g_loss.backward()
g_optim.step()
# 对判别器优化
d_optim.zero_grad()
# 计算判别器模型loss第一项,我们希望d对真实图片都预测成1
d_loss1 = optimizier.loss_fn(d_model(ground_truth_images), label_ones)
# 计算判别器模型loss第二项,我们希望d对所有虚构照片预测成0
label_zeros = torch.zeros([bs, 1])
# 不需要记录生成器部分梯度,设置detach()从计算图中分离出来
d_loss2 = optimizier.loss_fn(d_model(pred_images.detach()), label_zeros)
# d_loss为loss1、2二者之和
d_loss = (d_loss1 + d_loss2)
d_loss.backward()
d_optim.step()
# 保存照片
if i % per_step_save_picture == 0:
print(f"当前进度:{
i}")
print("保存照片中...")
print(g_loss, "g_loss")
print(d_loss, "d_loss")
for index, image in enumerate(pred_images):
# 反归一化
image = unnorm.unnormalize(image, (0.1307,), (0.3081,))
torchvision.utils.save_image(image, f"log/epoch_{
epoch}_{
i}_image_{
index}.png")
# 保存一张
break
代码地址
https://github.com/yyz159756/pytorch_learn/tree/main/GAN