版权声明:未经同意,不得转载。 https://blog.csdn.net/qq_36235275/article/details/82155013
Bolt1:
package com.jiangnan.storm.kafka;
import java.util.HashMap;
import java.util.Map;
import java.util.Map.Entry;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.IRichBolt;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
//统计通话次数。
public class WordCounterBolt implements IRichBolt{
private static final long serialVersionUID = 1L;
private OutputCollector collector;
private Map<String, Integer> countMap;
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
countMap = new HashMap<String, Integer>();
}
@Override
public void execute(Tuple input) {
String word = input.getString(0);
if(countMap.containsKey(word)) {
countMap.put(word, countMap.get(word)+1);
}else {
countMap.put(word, 1);
}
//确认元组数据已经处理完毕
collector.ack(input);
System.out.println(countMap);
}
@Override
public void cleanup() {
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
// TODO Auto-generated method stub
return null;
}
}
Bolt2:
package com.jiangnan.storm.kafka;
import java.util.Map;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.IRichBolt;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
//创建数据切分,产生一个一个的单词
public class WordCountSplitBolt implements IRichBolt{
private OutputCollector collector;
/**
* 为bolt提供要执行的环境,初始化bolt
*/
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
//处理输入元组
@Override
public void execute(Tuple input) {
System.out.println(input.getFields());
//input的字段为[topic, partition, offset, key, value],对应的value为第4个
String line = input.getString(4);
String[] words = line.split(" ");
for(String word:words) {
word = word.trim();
if(!word.isEmpty()) {
word = word.toLowerCase();
collector.emit(new Values(word));
}
}
}
//清理工作
@Override
public void cleanup() {
// TODO Auto-generated method stub
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
// TODO Auto-generated method stub
return null;
}
}
Spout(main):
package com.jiangnan.storm.kafka;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.kafka.spout.KafkaSpout;
import org.apache.storm.kafka.spout.KafkaSpoutConfig;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.tuple.Fields;
public class WordCountApp {
public static void main(String[] args) throws Exception {
Config conf = new Config();
conf.setNumWorkers(2);
conf.setDebug(true);
//创建拓扑对象
TopologyBuilder builder = new TopologyBuilder();
String topic = "stormKafka";
builder.setSpout("kafka_spout", new KafkaSpout<>(KafkaSpoutConfig.builder("master:9092", topic).build()));
builder.setBolt("wordcount-split-bolt", new WordCountSplitBolt())
.shuffleGrouping("kafka_spout");
builder.setBolt("wordcount-counter-bolt", new WordCounterBolt())
.fieldsGrouping("wordcount-split-bolt", new Fields("word"));
//LocalCluster cluster = new LocalCluster();
//cluster.submitTopology("www", conf, builder.createTopology());
StormSubmitter.submitTopology("wwwwww", conf, builder.createTopology());
}
}
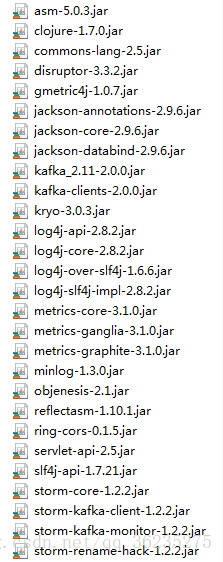
所需jar包: