一、简介
二、安装
三、一个简单生产者与消费者DEMO
四、Storm集成Kafka
一、简介
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop的一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消费。
它也属于MQ的一种,与RocketMQ、ActiveMQ不同的是Kafka没有消息重试等功能。主要强调海量数据的处理,吞吐量与堆积能力。所以他比较适合与storm、hadoop做集成。
Broker
Kafka集群包含一个或多个服务器,这种服务器被称为broker
Topic
每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)
Partition
Partition是物理上的概念,每个Topic包含一个或多个Partition(
ActiveMQ包含多个queue).
Producer
负责发布消息到Kafka broker(
RocketMQ中Producer有组的概念,作用是做分布式事务时使用,Kafka不支持事务,故没有组的概念)
Consumer
消息消费者,向Kafka broker读取消息的客户端。
Consumer Group
每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)。
一、简介
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop的一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消费。
它也属于MQ的一种,与RocketMQ、ActiveMQ不同的是Kafka没有消息重试等功能。主要强调海量数据的处理,吞吐量与堆积能力。所以他比较适合与storm、hadoop做集成。
Broker
Kafka集群包含一个或多个服务器,这种服务器被称为broker
Topic
每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)
Partition
Partition是物理上的概念,每个Topic包含一个或多个Partition(
ActiveMQ包含多个queue).
Producer
负责发布消息到Kafka broker(
RocketMQ中Producer有组的概念,作用是做分布式事务时使用,Kafka不支持事务,故没有组的概念)
Consumer
消息消费者,向Kafka broker读取消息的客户端。
Consumer Group
每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)。
二、安装(kafka集群依赖于ZK,做协调管理)
选择kafka_2.11-0.9.0.1.tgz下载到目录(我本机下载目录是/usr/local/kafka/)
2、进入目录后,解压 tar zxvf kafka_2.11-0.9.0.1.tgz
3、修改server.properties vim server.properties(我这里的目录是/usr/local/kafka/kafka_2.12-1.1.0)
3.1)broker.id=0#如果是Kafka集群,这个broker.id是不一样的,比如第一个是0,第二个是1等等,节点与节点之间并无直接联系,而是通过ZK来进行协调的
3.2)port=9092
3.3)host.name=192.168.100.245
3.4)advertised.host.name=192.168.100.245
3.5)log.dirs=/usr/local/kafka/kafka_2.11-0.9.0.1/kafka-logs#自定义文件夹
3.6)num.partitions=2
3.7)zookeeper.connect=192.168.100.142:2181,192.168.100.142:2181,192.168.100.143:2181
配置完毕之后,我们启动kafka(需要只用命令启动ZK集群zkServer.sh star)

然后再启动kafka
/usr/local/kafka/kafka_2.11-0.9.0.1/bin/kafka-server-start.sh /usr/local/kafka/kafka_2.11-0.9.0.1/config/server.properties &
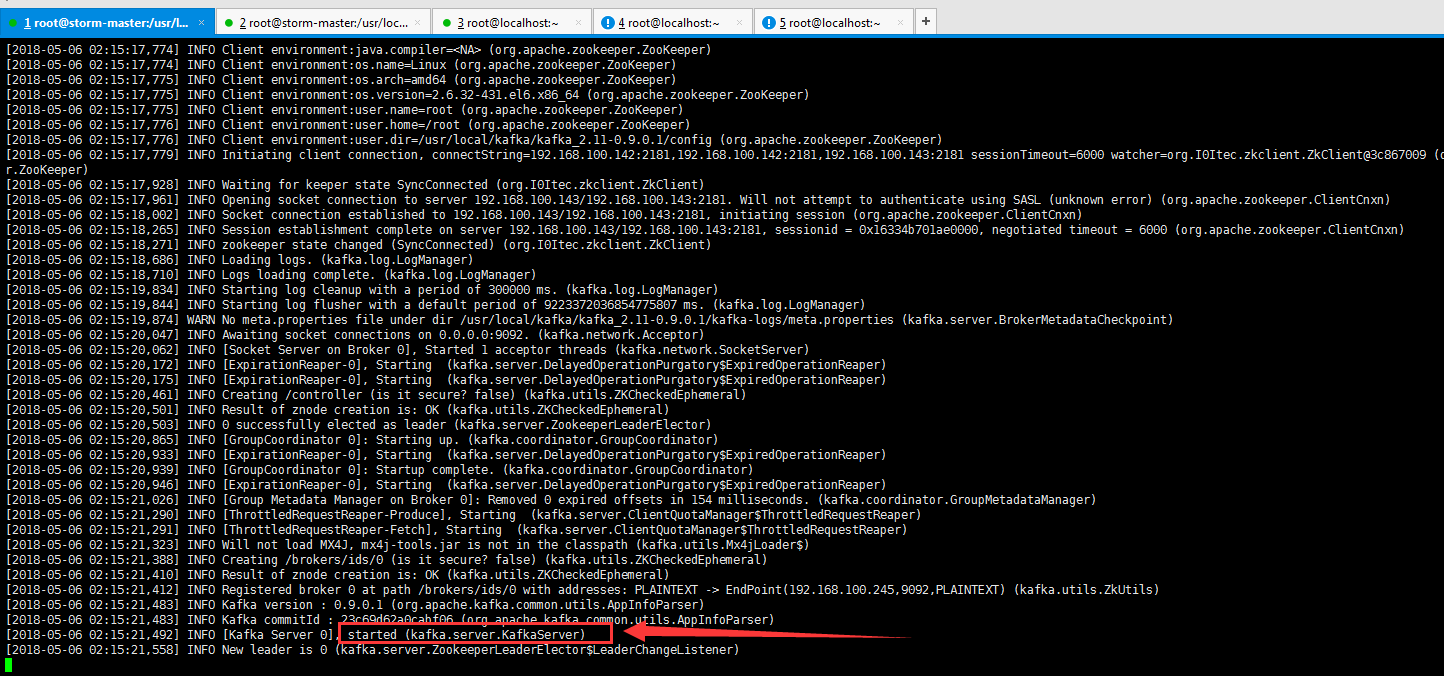
成功启动。
由于Kafka必须先新建topic,然后才能像topic发消息
以下命令可以操作kafka建立topic
cd /usr/local/kafka/kafka_2.11-0.9.0.1/bin
(1)创建topic主题命令:
./kafka-topics.sh --create --zookeeper 192.168.100.142:2181 --topic test --replication-factor 1 --partitions 1
(创建名为test的topic, 1个分区分别存放数据,数据备份总共1份)

(2)查看topic列表命令:
./kafka-topics.sh --zookeeper 192.168.100.142:2181 --list

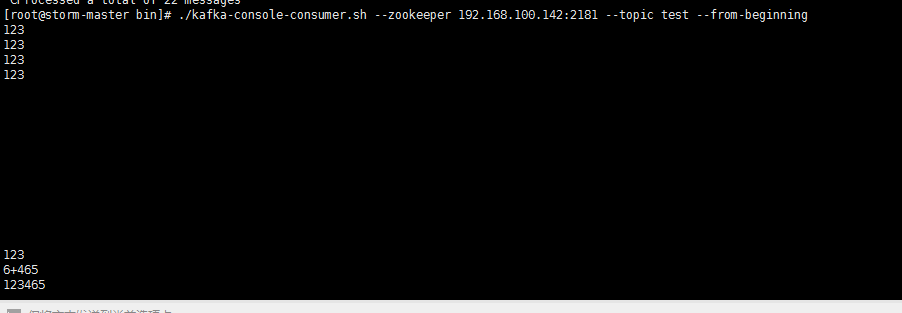
(3)kafka命令发送数据:
./kafka-console-producer.sh --broker-list 192.168.100.245:9092 --topic test
然后我们就可以编写数据发送出去了

(4)kafka命令接受数据:
./kafka-console-consumer.sh --zookeeper 192.168.100.142:2181 --topic test --from-beginning
然后我们就可以看到消费的信息了
三、一个简单生产者与消费者DEMO
下面用java连接kafka做个demo,demo中包含生产者KafkaProducer.java和消费者KafkaConsumer.java
1、这里需要一个生产者KafkaProducer,用于生产消息
import java.util.Properties;
import java.util.concurrent.TimeUnit;
import kafka.javaapi.producer.Producer;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig;
import kafka.serializer.StringEncoder;
public class KafkaProducer {
public static final String topic = "test";
public static void main(String[] args) throws Exception {
Properties properties = new Properties();
properties.put("zookeeper.connect", "192.168.100.142:2181,192.168.100.142:2181,192.168.100.143:2181"); //声明zk
properties.put("serializer.class", StringEncoder.class.getName());
properties.put("metadata.broker.list", "192.168.100.245:9092"); // 声明kafka broker
properties.put("request.required.acks", "1");
Producer producer = new Producer<Integer, String>(new ProducerConfig(properties));
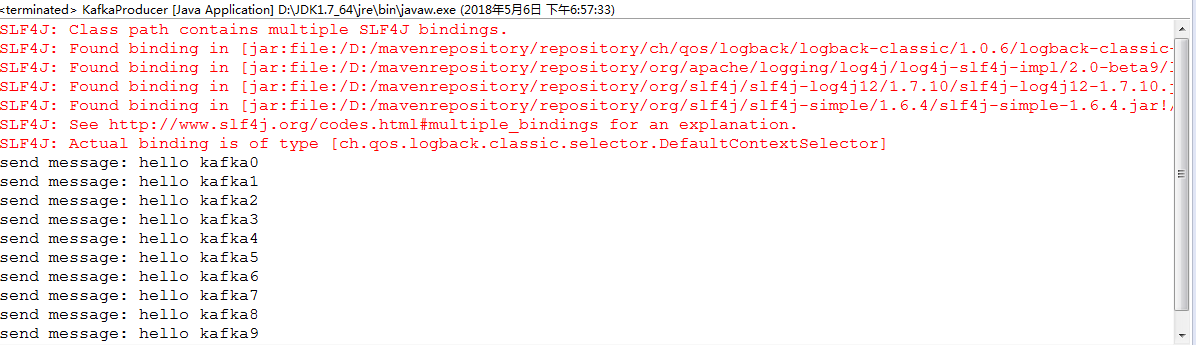
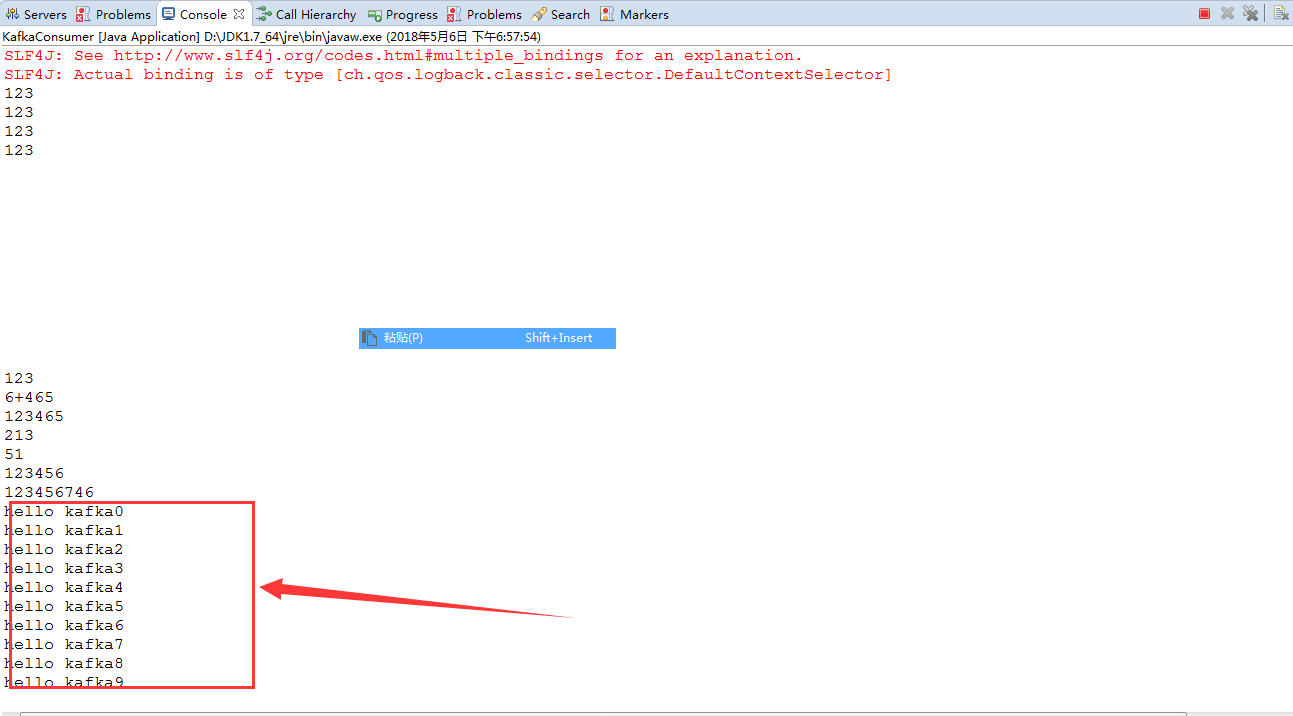
for(int i=0; i < 10; i++){
producer.send(new KeyedMessage<Integer, String>(topic, "hello kafka" + i));
System.out.println("send message: " + "hello kafka" + i);
TimeUnit.SECONDS.sleep(1);
}
producer.close();
}
} 
2、需要一个消费者消费消息KafkaConsumer
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties;
import kafka.consumer.ConsumerConfig;
import kafka.consumer.ConsumerIterator;
import kafka.consumer.KafkaStream;
import kafka.javaapi.consumer.ConsumerConnector;
import kafka.serializer.StringDecoder;
import kafka.utils.VerifiableProperties;
public class KafkaConsumer {
public static final String topic = "test";
public static void main(String[] args) {
Properties props = new Properties();
props.put("zookeeper.connect", "192.168.100.142:2181,192.168.100.142:2181,192.168.100.143:218");
//group 代表一个消费组
props.put("group.id", "group1");
//zk连接超时
props.put("zookeeper.session.timeout.ms", "4000");
props.put("zookeeper.sync.time.ms", "200");
props.put("auto.commit.interval.ms", "1000");
props.put("auto.offset.reset", "smallest");
//序列化类
props.put("serializer.class", "kafka.serializer.StringEncoder");
ConsumerConfig config = new ConsumerConfig(props);
ConsumerConnector consumer = kafka.consumer.Consumer.createJavaConsumerConnector(config);
Map<String, Integer> topicCountMap = new HashMap<String, Integer>();
topicCountMap.put(topic, new Integer(1));
StringDecoder keyDecoder = new StringDecoder(new VerifiableProperties());
StringDecoder valueDecoder = new StringDecoder(new VerifiableProperties());
Map<String, List<KafkaStream<String, String>>> consumerMap =
consumer.createMessageStreams(topicCountMap,keyDecoder,valueDecoder);
KafkaStream<String, String> stream = consumerMap.get(topic).get(0);
ConsumerIterator<String, String> it = stream.iterator();
while (it.hasNext())
System.out.println(it.next().message());
}
}
由于我这里是maven项目,相关包配置如下
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>storm06</groupId>
<artifactId>storm06</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>storm07</name>
<url>http://maven.apache.org</url>
<repositories>
<!-- Repository where we can found the storm dependencies -->
<repository>
<id>clojars.org</id>
<url>http://clojars.org/repo</url>
</repository>
</repositories>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>0.9.2-incubating</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.10</artifactId>
<version>0.9.0.1</version>
<exclusions>
<exclusion>
<groupId>com.sun.jdmk</groupId>
<artifactId>jmxtools</artifactId>
</exclusion>
<exclusion>
<groupId>com.sun.jmx</groupId>
<artifactId>jmxri</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<version>2.0-beta9</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-1.2-api</artifactId>
<version>2.0-beta9</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>log4j-over-slf4j</artifactId>
<version>1.7.10</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.10</version>
</dependency>
<!-- storm & kafka sqout -->
<dependency>
<groupId>net.wurstmeister.storm</groupId>
<artifactId>storm-kafka-0.8-plus</artifactId>
<version>0.4.0</version>
</dependency>
<dependency>
<groupId>commons-collections</groupId>
<artifactId>commons-collections</artifactId>
<version>3.2.1</version>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>15.0</version>
</dependency>
</dependencies>
<build>
<finalName>storm06</finalName>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-war-plugin</artifactId>
<version>2.4</version>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.1</version>
<configuration>
<source>1.7</source>
<target>1.7</target>
</configuration>
</plugin>
<!-- 单元测试 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<configuration>
<skip>true</skip>
<includes>
<include>**/*Test*.java</include>
</includes>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-source-plugin</artifactId>
<version>2.1.2</version>
<executions>
<!-- 绑定到特定的生命周期之后,运行maven-source-pluin 运行目标为jar-no-fork -->
<execution>
<phase>package</phase>
<goals>
<goal>jar-no-fork</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
四、Storm集成Kafka
由于Storm的数据来自Kafka,所以我必须有一个生产者(WordsProducer.java),来生产数据,这些数据最后将流入Storm里面,然后进行处理。
这里包含
生产者(
WordsProducer.java、Topology(KafkaTopology.java)、2个bolts(SentenceBolt.java、PrinterBolt.java)
这里取名为:WordsProducer,需要创建一个名为words_topic的Topic

import java.util.Properties;
import kafka.javaapi.producer.Producer;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig;
public class WordsProducer {
public static void main(String[] args) {
// Build the configuration required for connecting to Kafka
Properties props = new Properties();
// List of Kafka brokers. Complete list of brokers is not
// required as the producer will auto discover the rest of
// the brokers. Change this to suit your deployment.
props.put("metadata.broker.list", "192.168.100.245:9092");
// Serializer used for sending data to kafka. Since we are sending string,
// we are using StringEncoder.
props.put("serializer.class", "kafka.serializer.StringEncoder");
// We want acks from Kafka that messages are properly received.
props.put("request.required.acks", "1");
// Create the producer instance
ProducerConfig config = new ProducerConfig(props);
Producer<String, String> producer = new Producer<String, String>(config);
// Now we break each word from the paragraph
for (String word : METAMORPHOSIS_OPENING_PARA.split("\\s")) {
// Create message to be sent to "words_topic" topic with the word
KeyedMessage<String, String> data =
new KeyedMessage<String, String>("words_topic", word);
// Send the message
producer.send(data);
}
System.out.println("Produced data");
// close the producer
producer.close();
}
// First paragraph from Franz Kafka's Metamorphosis
private static String METAMORPHOSIS_OPENING_PARA =
"One morning, when Gregor Samsa woke from troubled dreams, "
+ "he found himself transformed in his bed into a horrible "
+ "vermin. He lay on his armour-like back, and if he lifted "
+ "his head a little he could see his brown belly, slightly "
+ "domed and divided by arches into stiff sections.";
}
2、在KafkaTopology里边,我将做一些配置,Strom集成kafka配置底层有第三方jar包提供
maven配置如下
<dependency>
<groupId>net.wurstmeister.storm</groupId>
<artifactId>storm-kafka-0.8-plus</artifactId>
<version>0.4.0</version>
</dependency>import storm.kafka.KafkaSpout;
import storm.kafka.SpoutConfig;
import storm.kafka.StringScheme;
import storm.kafka.ZkHosts;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.generated.AlreadyAliveException;
import backtype.storm.generated.InvalidTopologyException;
import backtype.storm.spout.SchemeAsMultiScheme;
import backtype.storm.topology.TopologyBuilder;
public class KafkaTopology {
public static void main(String[] args) throws
AlreadyAliveException, InvalidTopologyException {
// zookeeper hosts for the Kafka cluster
ZkHosts zkHosts = new ZkHosts("192.168.100.142:2181");
//注意这里的Spout的来源是kafka(kafka数据流入storm)
SpoutConfig kafkaConfig = new SpoutConfig(zkHosts,
"words_topic", "", "id7");
// Specify that the kafka messages are String
kafkaConfig.scheme = new SchemeAsMultiScheme(new StringScheme());
// We want to consume all the first messages in the topic everytime
// we run the topology to help in debugging. In production, this
// property should be false
kafkaConfig.forceFromStart = true;
// Now we create the topology
TopologyBuilder builder = new TopologyBuilder();
// set the kafka spout class
builder.setSpout("KafkaSpout", new KafkaSpout(kafkaConfig), 1);
// configure the bolts
builder.setBolt("SentenceBolt", new SentenceBolt(), 1).globalGrouping("KafkaSpout");
builder.setBolt("PrinterBolt", new PrinterBolt(), 1).globalGrouping("SentenceBolt");
// create an instance of LocalCluster class for executing topology in local mode.
LocalCluster cluster = new LocalCluster();
Config conf = new Config();
// Submit topology for execution
cluster.submitTopology("KafkaToplogy", conf, builder.createTopology());
try {
// Wait for some time before exiting
System.out.println("Waiting to consume from kafka");
Thread.sleep(10000);
} catch (Exception exception) {
System.out.println("Thread interrupted exception : " + exception);
}
// kill the KafkaTopology
cluster.killTopology("KafkaToplogy");
// shut down the storm test cluster
cluster.shutdown();
}
}
SentenceBolt.java
import java.util.ArrayList;
import java.util.List;
import org.apache.commons.lang.StringUtils;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import com.google.common.collect.ImmutableList;
public class SentenceBolt extends BaseBasicBolt {
// list used for aggregating the words
private List<String> words = new ArrayList<String>();
public void execute(Tuple input, BasicOutputCollector collector) {
// Get the word from the tuple
String word = input.getString(0);
if(StringUtils.isBlank(word)){
// ignore blank lines
return;
}
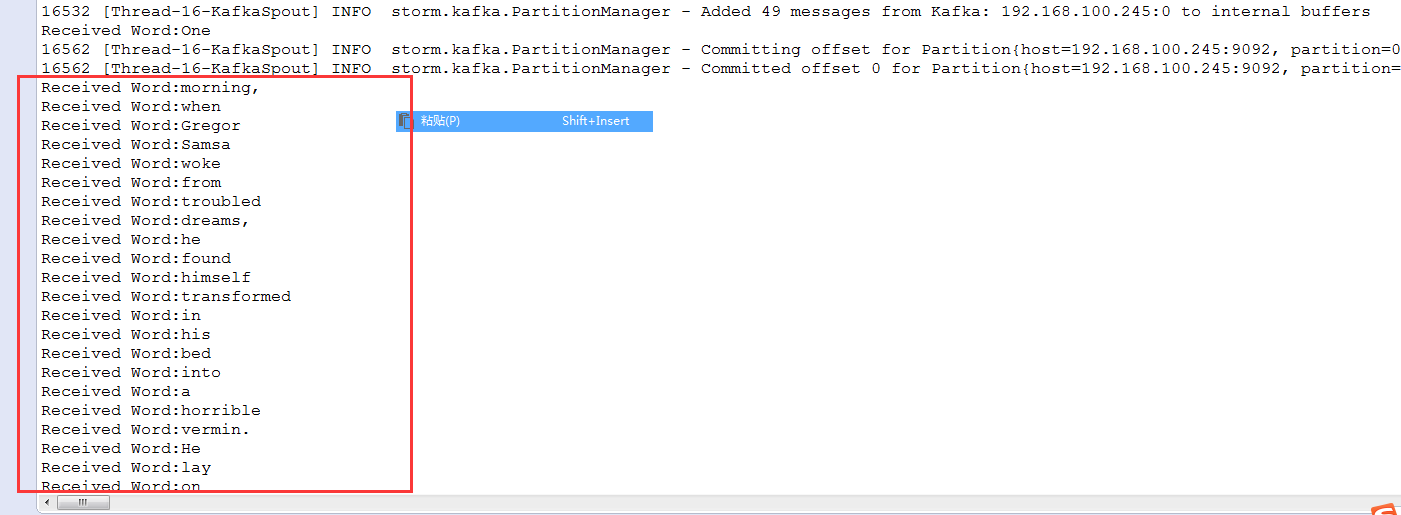
System.out.println("Received Word:" + word);
// add word to current list of words
words.add(word);
if (word.endsWith(".")) {
// word ends with '.' which means this is the end of
// the sentence publishes a sentence tuple
collector.emit(ImmutableList.of(
(Object) StringUtils.join(words, ' ')));
// and reset the words list.
words.clear();
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// here we declare we will be emitting tuples with
// a single field called "sentence"
declarer.declare(new Fields("sentence"));
}
}
PrinterBolt.java
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Tuple;
public class PrinterBolt extends BaseBasicBolt {
public void execute(Tuple input, BasicOutputCollector collector) {
// get the sentence from the tuple and print it
String sentence = input.getString(0);
System.out.println("Received Sentence:" + sentence);
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// we don't emit anything
}
}
启动生产者生产数据

Storm接受流入的kafka数据,进行消费并且做了处理。最后打印
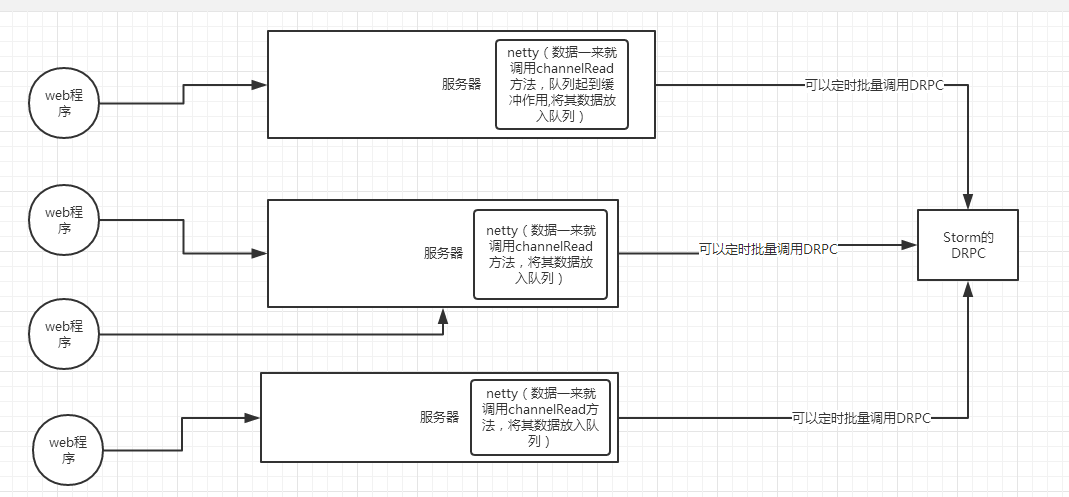
PS:
Strom不仅可以和kafka做集成,也可以和netty做集成.如下图所示