Storm集成Kafka中KafkaSpout配置参数释义
KafkaSpout构造:
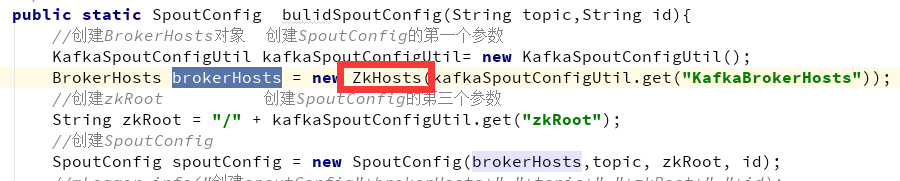
涉及到两个类:
SpoutConifg、KafkaConfig、ZkHosts
一、 SpoutConfig:
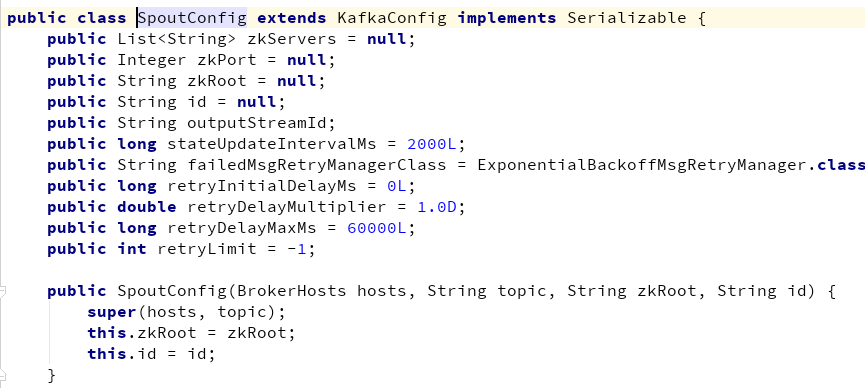
zkServers: KafkaSpout保存offset的zookeeper所在地址. 立出来这个属性是为了防止offset保存位置不在kafka集群中. 如果kafka和storm在一个集群,该属性可以忽略
zkPort: KafkaSpout保存offset的zookeeper端口. 如果kafka和storm在一个集群,该属性可以忽略。
zkRoot: offset在zookeeper中保存的路径.路径计算方式为:${zkRoot}/${id}/${partitionId}
id:kafkaSpout保存offset的不同客户端区分标志.
建议每个拓扑使用固定的,不同的参数,以保证拓扑重新提交之后,可以从上次位置继续读取数据.如果两个拓扑公用同一个id,那么可能会被重复读取
如果在拓扑中使用了动态生成的uuid来作为id,那么每次提交的拓扑,都会从队列最开始位置读取数据.
stateUpdateIntervalMs: offset刷新到zookeeper中的时间间隔. 单位:毫秒
failedMsgRetryManagerClass:消息失败的重试策略. 调用OutputCollector.fail().只有在使用ExponentialBackoffMsgRetryManager时才会生效.
retryInitialDelayMs: 连续重试之间的初始延迟.retryDelayMultiplier:连续重试之间延迟倍数.retryDelayMaxMs: 连续重试之间的最大延迟.retryLimit:如果retryLimit小于零,失败的消息将无限重试。
二、 KafkaConfig
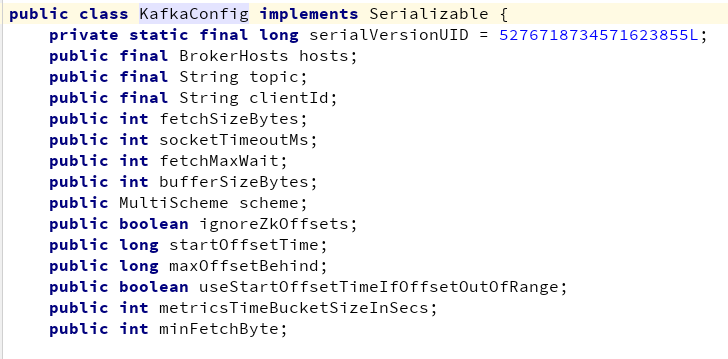
hosts: Kafka地址和分区关系对应信息
topic: 要从kafka中读取的topic队列名称
clientId:Kafka的客户端id参数,该参数一般不需要设置. 默认值为kafka.api.OffsetRequest.DefaultClientId()
fetchSizeBytes: Kafka Consumer每次请求获取的数据量大小.每次获取的数据消费完毕之后,才会再获取数据. 默认1MB
socketTimeoutMs: Kafka SimpleConsumer 客户端和服务端连接的超时时间. 单位:毫秒
fetchMaxWait: Kafka Consumer每次获取数据的超时时间.单位:毫秒
bufferSizeBytes: Kafka Consumer通过网络IO获取数据的socket buffet大小.默认1MB
scheme:该参数有两个作用:
1:申明输出的数据字段 declareoutputFileds
2:对从kafka中读到的数据进行反序列化,即将byte字节数组转为tuple对象。
对kafka存入数据的key和message都比较关心的,可以使用KeyValueSchemeAsMultiScheme,如果不关心,可以使用SchemeAsMultiScheme.默认接口实现一般都只会输出一个字段或者两个字段,很多时候,我们需要直接从kafka中读取到数据之后,就将每个字段解析了,然后进行简单处理再emit这个时候,建议自己实现MultiScheme接口。
ignoreZkOffsets:在拓扑提交之后,KafkaSpout会从zookeeper中读取以前的offset值,以便沿着上次位置继续读取数据。KafkaSpout会检查拓扑ID和zookeeper中保存的拓扑id是否相同。
如果不同,并且ignoreZkOffsets=true,那么就会从startOffsetTime参数位置读取数据.否则,沿着zookeeper中保存的offset位置继续读取数据。也就是说,当ignoreZkOffsets=true的时候,kafkaspout只能保证在拓扑不杀掉的情况下,当worker进程异常退出的时候,会沿着上次读取位置继续读取数据,当拓扑重新提交的时候,就会从队列最早位置开始读取数据。这样就会存在重复读取数据的问题,所以正式场景,该参数还是应该设置为false。以保证任何场景数据的只被读取一次。
startOffsetTime:拓扑第一次提交,zookeeper中没有保存对应offset的情况下,默认从kafka中读取的offset位置。默认从队列最早位置开始读取数据,即从队列最开始位置读取数据。
默认为kafka.api.OffsetRequest.EarliestTime()开始读,也就是从Kafka中最早的消息开始处理。
也可以设成kafka.api.OffsetRequest.LatestOffset,也就是最早的消息开始读。也可以自己指定具体的值。
maxOffsetBehind:如果当前的(offset值-failed offsets中最小值) < maxOffsetBehind 那么就会清理failed列表中所有大于maxOffsetBehind的offset值。
这是为了防止failed过多,重发太多导致内存溢出。不过默认为了保证数据不丢失,所以maxOffsetBehind设置的最大。
这个字段对于KafkaSpout的多个处理流程都有影响。当KafkaSpout对某个partition的处理进度落后startOffsetTime对应的offset多于此值时, KafkaSpout会丢弃中间的消息,从而强制赶上目标进度.比如,如果startOffsetTime设成了lastestTime,
那么如果进度落后超过maxOffsetBehind,KafkaSpout会直接从latestTime对应的offset开始处理。如果设成了froceFromStart,
则在提交新任务时,始终会从EarliestTime开始读。
useStartOffsetTimeIfOffsetOutOfRange:当KafkaSpout初始化之后,使用从zookeeper中读取的上次记录的offset.从kafka中获取数据失败,返回offsetOutofRange错误之后,是否使用startOffset从队列最早位置重新获取数据。 offsetOutofrange一般发生在topic被重建,分片被删除的场景。
metricsTimeBucketSizeInSecs: metric监控信息采集间隔。
三、 ZkHosts

brokerZkStr: kafka集群zookeeper地址. brokerZkPath: kafka集群中broker元数据所在地址.默认为/brokers refreshFreqSecs: kafka broker分区信息刷新时间间隔. 单位:秒. 当kafka有broker节点重启或者分区信息发生变化而导致数据读取失败的时候,都会重新触发一次分区信息刷新.
本文参考:
http://blog.csdn.net/ransom0512/article/details/50497261
http://storm.apache.org/releases/2.0.0-SNAPSHOT/storm-kafka.html