版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u011240016/article/details/85148475
一些概念
深度学习中的所有数据张量的第一个轴都是样本轴,也称之为样本维度。另外,深度学习模型不会同时处理整个数据集,而是将数据拆分成小批量,比如前面的案例就是每次取128个数据作为一个批量。
batch = train_images[:128]
# next
batch = train_images[128:256]
# nth
batch = train_images[128 * n: 128 * (n+1)]
在数字标号记住两个点:
- 从0开始
- 左闭右开
这是老外喜欢的调性。
在这个场景里,第一个轴称之为批量轴 batch axis或者也称之为批量维度 batch dimension。
这些术语对于构建整个理解知识体系很重要。
现实世界的数据张量描述
这里给出的几个例子,可以作为参考:
- 向量数据:2D张量,形状:
(samples, features) - 时间序列数据:3D张量,形状:
(samples, timesteps, features) - 图像:4D张量,形状为:
(samples, height, width, channels)或者(samples, channels, height, width)
向量数据
每一条/行就是一个数据,第一个轴是样本轴,第二个轴是特征轴。一般的CSV数据都是这类。
时间序列或序列数据
这里给出的例子极好,以股票数据为例,每一分钟可以记录三个数据:
- 股票当前价格
- 前一分钟最高价
- 前一分钟最低价
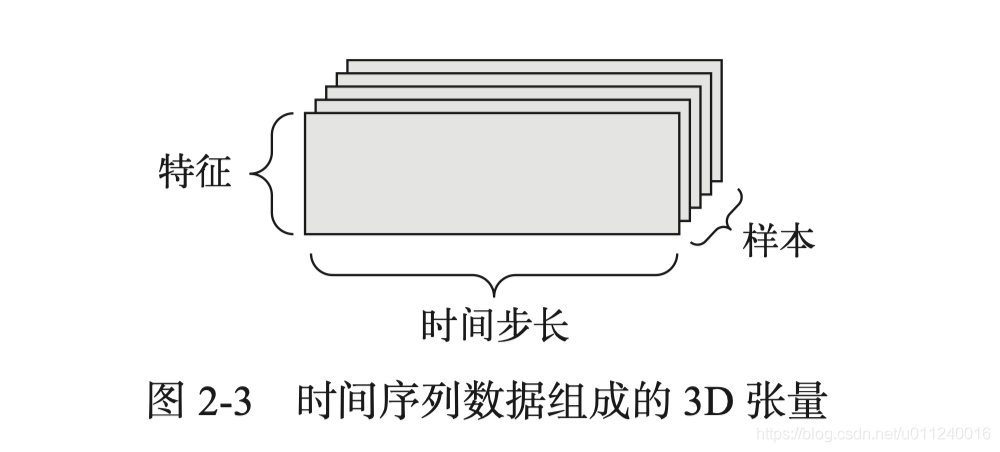
所以每一分钟的数据可以编码为一个3D向量,注意这不是3D张量。一天下来,交易日有390分钟,可以得到一个2D张量,形状为(390,3)。一年250天则可以保存在一个形状为(250, 390,3)的3D张量中。一天的股票数据即为一个样本。
第一个轴是样本轴,第二个轴是时间轴,第三个轴是特征轴,这是约定的惯例。
扫描二维码关注公众号,回复:
4769281 查看本文章

图像数据

这个很熟悉的,一张图就是一个样本,样本轴一定是第一个;只是在样本内轴的划分有两种:
- 通道在前
- 通道在后
其中Tensorflow用的是通道在后的设定,而Keras支持两种设定。
END.