Hive仓库表数据最终是存储在HDFS上,由于Hadoop的特性,对大文件的处理非常高效。而且大文件可以减少文件元数据信息,减轻NameNode的存储压力。但是在数据仓库中,越是上层的表汇总程度就越高,数据量也就越小,而且这些表通常会有日期分区,随着时间的推移,HDFS的文件数目就会逐步增加。
小文件合并与数据压缩
一、小文件带来的问题
HDFS的文件包好数据块和元信息,其中元信息包括位置、大小、分块等信息,都保存在NameNode的内存中。每个对象大约占用150个字节,因此一千万文件及分块就会占用约3G的内存空间,一旦接近这个量级,NameNode的性能就会开始下降。HDFS读写小文件时也会更加耗时,因为每次都需要从NameNode获取元信息,并且对应的DataNode建立连接。对于MapReduce程序来说,小文件会增加Mapper的数量,每个Map任务只会处理很少的数据,浪费大量的调度时间。
二、Hive小文件产生的原因
一方面hive数据仓库中汇总表的数据量通常比源数据少的多,而且为了提升运算速度,我们会增加Reduce的数量,Hive本身也会做类似的优化----Reducer数量等于源数据的量除以hive.exec.reducers.bytes.per.reduce所配置的量(默认1G)。Reduce数量的增加也即意味着结果文件的增加,从而产生小文件的问题。
解决小文件的问题可以从两个方向入手:
- 输入合并。即在map前合并小文件。
- 输出合并。即在输出结果的时候合并小文件。
三、配置Map输入合并
-- 每个Map最大输入大小,决定合并后的文件数
set mapred.max.split.size=256000000;
-- 一个节点上split的至少的大小 ,决定了多个data node上的文件是否需要合并
set mapred.min.split.size.per.node=100000000;
-- 一个交换机下split的至少的大小,决定了多个交换机上的文件是否需要合并
set mapred.min.split.size.per.rack=100000000;
-- 执行Map前进行小文件合并
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
四、配置hive结果合并
通过设置hive的配置项在执行结束后对结果文件进行合并:
set hive.merge.mapfiles = true #在Map-only的任务结束时合并小文件
set hive.merge.mapredfiles = true #在Map-Reduce的任务结束时合并小文件
set hive.merge.size.per.task = 256*1000*1000 #合并文件的大小
set hive.merge.smallfiles.avgsize=16000000 #当输出文件的平均大小小于该值时,启动一个独立的map-reduce任务进行文件merge
hive在对结果文件进行合并时会执行一个额外的map-only脚本,mapper的数量是文件总大小除以size.per.task参数所得的值,触发合并的条件是:根据查询类型不同,相应的mapfiles/mapredfiles参数需要打开;结果文件的平均大小需要大于avgsize参数的值。
-- map-red job,5个reducer,产生5个60K的文件。
create table dw_stage.zj_small as
select paid, count (*)
from dw_db.dw_soj_imp_dtl
where log_dt = '2014-04-14'
group by paid;
-- 执行额外的map-only job,一个mapper,产生一个300K的文件。
set hive.merge.mapredfiles= true;
create table dw_stage.zj_small as
select paid, count (*)
from dw_db.dw_soj_imp_dtl
where log_dt = '2014-04-14'
group by paid;
-- map-only job,45个mapper,产生45个25M左右的文件。
create table dw_stage.zj_small as
select *
from dw_db.dw_soj_imp_dtl
where log_dt = '2014-04-14'
and paid like '%baidu%' ;
-- 执行额外的map-only job,4个mapper,产生4个250M左右的文件。
set hive.merge.smallfiles.avgsize=100000000;
create table dw_stage.zj_small as
select *
from dw_db.dw_soj_imp_dtl
where log_dt = '2014-04-14'
and paid like '%baidu%' ;
五、压缩文件的处理
对于输出结果为压缩文件形式存储的情况,要解决小文件问题,如果在map输入前合并,对输出的文件存储格式并没有限制。但是如果使用输出合并,则必须配合SequenceFile来存储,否则无法进行合并,以下是实例:
set mapred.output.compression.type=BLOCK;
set hive.exec.compress.output= true;
set mapred.output.compression.codec=org.apache.hadoop.io.compress.LzoCodec;
set hive.merge.smallfiles.avgsize=100000000;
drop table if exists dw_stage.zj_small;
create table dw_stage.zj_small
STORED AS SEQUENCEFILE
as select *
from dw_db.dw_soj_imp_dtl
where log_dt = '2014-04-14'
and paid like '%baidu%' ;
六、使用HAR归档文件
Hadoop的归档文件格式也是解决小文件问题的方式之一。而且hive提供了原生支持:
set hive.archive.enabled= true;
set hive.archive.har.parentdir.settable= true;
set har.partfile.size=1099511627776;
ALTER TABLE srcpart ARCHIVE PARTITION(ds= '2008-04-08', hr= '12' );
ALTER TABLE srcpart UNARCHIVE PARTITION(ds= '2008-04-08', hr= '12' );
如果使用的不是分区表,则可以创建成外部表,并使用har://协议来指定路径。
七、文件格式和压缩
- 数据仓库在建设使用的过程中,主要消耗的资源包含:CPU、MEMORY、DISK三部分。
- 数据仓库在计算过程中主要消耗CPU和Memory资源,当然也会消耗一些DISK资源用来存储计算过程中的临时结果。但是主要优化的方向,还是降低CPU和MEMORY的消耗,这方面主要依赖于模型设计的合理性,所以在模型设计阶段增加模型设计review的步骤,保证模型设计的合理性。
- 数据仓库在数据的存储阶段主要消耗MEMORY和DISK资源。memory资源主要是在NameNode存储文件信息的时候消耗掉;DISK在存储数据的时候消耗掉。在这个阶段需要严格控制HIVE表的的定义,来降低资源的消耗。
- 本次主要探讨是数据仓库在数据存储阶段对资源消耗的优化,下面将通过2个方面展开,分别是:数据仓库如何配置,可以实现数据压缩,降低数据的存储量,达到减少对DISK的消耗;数仓表如何设计,可以降低文件信息存储量,达到减少对MEMORY的消耗。
- hive在存储数据时支持通过不同的文件类型来组织,并且为了节省相应的存储资源,也提供了多种类型的压缩算法,供用户选择。只要是配置正确的文件类型和压缩类型,hive都可以按预期读取并解析数据,不影响上层HQL语句的使用。例如:SequenceFile本身的结构已经设计了对内容进行压缩,所以对于SequenceFile文件的压缩,并不是先生成SequenceFile文件,再对文件进行压缩;而是生成SequenceFile文件时,就对其中的内容字段进行压缩。最终压缩后,对外仍然体现为一个SequenceFile。RCFile、ORCFile、Parquet、Avro对于压缩的处理方式与SequenceFile相同。
hive支持的文件类型有:TextFile、SequenceFile、RCFile、ORCFile、Parquet、Avro。
hive支持的压缩算法有:
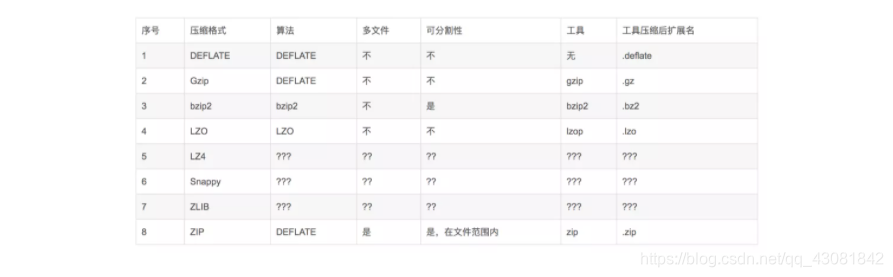
TextFile
TextFile是hive数据表的默认格式,存储方式:行存储;可以采用多种压缩方式,但是部分压缩算法压缩数据后生成的文件是不支持split;压缩后的数据在反序列化过程中,必须逐个字段判断是不是分隔符和行结束符,因此反序列化开销会比SequenceFile高几十倍。
- TextFile文件,非压缩
--创建一个表,格式为文本文件:
CREATE EXTERNAL TABLE student_text (id STRING, name STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
STORED AS TEXTFILE;
--导入数据到此表中,将启动MR任务
INSERT OVERWRITE TABLE student_text SELECT * FROM student;
可以看到生成的数据文件的格式为非压缩的文本文件:
hdfs dfs -cat /user/hive/warehouse/student_text/000000_0
1001810081,cheyo
1001810082,pku
1001810083,rocky
1001810084,stephen
2002820081,sql
2002820082,hello
2002820083,hijj
3001810081,hhhhhhh
3001810082,abbbbbb
- TextFile文件,Deflate压缩
--创建一个表,格式为文件文件:
CREATE TABLE student_text_def (id STRING, name STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
STORED AS TEXTFILE;
--设置压缩类型为Gzip压缩
SET hive.exec.compress.output=true;
SET mapred.output.compress=true;
SET mapred.output.compression.codec=org.apache.hadoop.io.compress.DefaultCodec;
--导入数据:
INSERT OVERWRITE TABLE student_text_def SELECT * FROM student;
--查看数据
SELECT * FROM student_text_def;
查看数据文件,可以看到数据文件为多个.deflate文件
hdfs dfs -ls /user/hive/warehouse/student_text_def/
-rw-r--r-- 2020-09-16 12:48 /user/hive/warehouse/student_text_def/000000_0.deflate
-rw-r--r-- 2020-09-16 12:48 /user/hive/warehouse/student_text_def/000001_0.deflate
-rw-r--r-- 2020-09-16 12:48 /user/hive/warehouse/student_text_def/000002_0.deflate
- TextFile文件,Gzip压缩
--创建一个表,格式为文件文件:
CREATE TABLE student_text_gzip (id STRING, name STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
STORED AS TEXTFILE;
--设置压缩类型为Gzip压缩
SET hive.exec.compress.output=true;
SET mapred.output.compress=true;
SET mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
set io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec;
--导入数据:
INSERT OVERWRITE TABLE student_text_gzip SELECT * FROM student;
--查看数据
SELECT * FROM student_text_gzip;
查看数据文件,可以看到数据文件为多个.gz文件。解压.gz文件,可以看到明文文本:
hdfs dfs -ls /user/hive/warehouse/student_text_gzip/
-rw-r--r-- 2020-09-15 10:03 /user/hive/warehouse/student_text_gzip/000000_0.gz
-rw-r--r-- 2020-09-15 10:03 /user/hive/warehouse/student_text_gzip/000001_0.gz
-rw-r--r-- 2020-09-15 10:03 /user/hive/warehouse/student_text_gzip/000002_0.gz
- TextFile文件,Bzip2压缩
--创建一个表,格式为文件文件:
CREATE TABLE student_text_bzip2 (id STRING, name STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
STORED AS TEXTFILE;
--设置压缩类型为Bzip2压缩:
SET hive.exec.compress.output=true;
SET mapred.output.compress=true;
SET mapred.output.compression.codec=org.apache.hadoop.io.compress.BZip2Codec;
--导入数据
INSERT OVERWRITE TABLE student_text_bzip2 SELECT * FROM student;
--查看数据:
SELECT * FROM student_text_bzip2;
查看数据文件,可看到数据文件为多个.bz2文件。解开.bz2文件,可以看到明文文本:
hdfs dfs -ls /user/hive/warehouse/student_text_bzip2
-rw-r--r-- 2020-09-15 10:09 /user/hive/warehouse/student_text_bzip2/000000_0.bz2
-rw-r--r-- 2020-09-15 10:09 /user/hive/warehouse/student_text_bzip2/000001_0.bz2
-rw-r--r-- 2020-09-15 10:09 /user/hive/warehouse/student_text_bzip2/000002_0.bz2
- TextFile文件,Lzo压缩
--创建表
CREATE TABLE student_text_lzo (id STRING, name STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
STORED AS TEXTFILE;
--设置为LZO压缩
SET hive.exec.compress.output=true;
SET mapred.output.compress=true;
SET mapred.output.compression.codec=com.hadoop.compression.lzo.LzopCodec;
--导入数据
INSERT OVERWRITE TABLE student_text_lzo SELECT * FROM student;
--查询数据
SELECT * FROM student_text_lzo;
查看数据文件,可以看到数据文件为多个.lzo压缩。解开.lzo文件,可以看到明文文件。(需要安装lzop库)
- TextFile文件,Lz4压缩
--创建表
CREATE TABLE student_text_lz4 (id STRING, name STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
STORED AS TEXTFILE;
--设置为LZ4压缩
SET hive.exec.compress.output=true;
SET mapred.output.compress=true;
SET mapred.output.compression.codec=org.apache.hadoop.io.compress.Lz4Codec;
--导入数据
INSERT OVERWRITE TABLE student_text_lz4 SELECT * FROM student;
查看数据文件,可看到数据文件为多个.lz4压缩。使用cat查看.lz4文件,可以看到是压缩后的文本。
hdfs dfs -ls /user/hive/warehouse/student_text_lz4
-rw-r--r-- 2020-09-16 12:06 /user/hive/warehouse/student_text_lz4/000000_0.lz4
-rw-r--r-- 2020-09-16 12:06 /user/hive/warehouse/student_text_lz4/000001_0.lz4
-rw-r--r-- 2020-09-16 12:06 /user/hive/warehouse/student_text_lz4/000002_0.lz4
- TextFile文件,Snappy压缩
--创建表
CREATE TABLE student_text_snappy (id STRING, name STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
STORED AS TEXTFILE;
--设置压缩
SET hive.exec.compress.output=true;
SET mapred.compress.map.output=true;
SET mapred.output.compress=true;
SET mapred.output.compression=org.apache.hadoop.io.compress.SnappyCodec;
SET mapred.output.compression.codec=org.apache.hadoop.io.compress.SnappyCodec;
SET io.compression.codecs=org.apache.hadoop.io.compress.SnappyCodec;
--导入数据
INSERT OVERWRITE TABLE student_text_snappy SELECT * FROM student;
--查询数据
SELECT * FROM student_text_snappy;
查看数据文件,可看到数据文件多个.snappy压缩文件。使用cat查看.snappy文件,可以看到是压缩后的文本:
hdfs dfs -ls /user/hive/warehouse/student_text_snappy
Found 3 items
-rw-r--r-- 2020-09-15 16:42 /user/hive/warehouse/student_text_snappy/000000_0.snappy
-rw-r--r-- 2020-09-15 16:42
SequenceFile文件
SequenceFile是Hadoop API提供的一种二进制文件,它将数据以<key,value>的形式序列化到文件中。这种二进制文件内部使用hadoop的标准Writable接口实现序列化和反序列化。它与Hadoop API中的MapFile是互相兼容的。hive中的SequenceFile继承自hadoop API的SequenceFile,不过它的key为空,使用value存放实际的值,这样是为了避免MR在运行map阶段的排序过程。
- SequenceFile是一种二进制文件,以<key,value>的形式序列化到文件中。存储方式:行存储;
- 支持三种压缩类型:None、Record、Block。默认采用Record,但是Record压缩率低;一般建议使用Block压缩;
- 优势是文件和Hadoop API的MapFile是相互兼容的。
SequenceFile,Deflate压缩
--创建一个表,格式为文件文件:
CREATE TABLE student_seq_def (id STRING, name STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
STORED AS SEQUENCEFILE;
--设置压缩算法为Deflate压缩
SET hive.exec.compress.output=true;
SET mapred.output.compress=true;
SET mapred.output.compression.codec=org.apache.hadoop.io.compress.DeflateCodec;
--设置压缩类型为block
SET mapred.output.compression.type=BLOCK
--导入数据:
INSERT OVERWRITE TABLE student_seq_def SELECT * FROM student;
--查看数据
SELECT * FROM student_seq_def;
查看数据文件,是一个密文的文件。
hdfs dfs -ls /user/hive/warehouse/student_seq_def/
-rw-r--r-- /user/hive/warehouse/student_seq_def/000000_0
- SequenceFile,Gzip压缩
--创建一个表,格式为文件文件:
CREATE TABLE student_seq_gzip (id STRING, name STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
STORED AS SEQUENCEFILE;
--设置压缩类型为Gzip压缩
SET hive.exec.compress.output=true;
SET mapred.output.compress=true;
SET mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
--设置压缩类型为block
SET mapred.output.compression.type=BLOCK
--导入数据:
INSERT OVERWRITE TABLE student_seq_gzip SELECT * FROM student;
--查看数据
SELECT * FROM student_seq_gzip;
查看数据文件,是一个密文的文件,无法通过gzip解压:
hdfs dfs -ls /user/hive/warehouse/student_seq_gzip/
-rw-r--r-- /user/hive/warehouse/student_seq_gzip/000000_0
RcFile
存储方式:数据按行分块,每块按列存储。结合了行存储和列存储的有点:
- 首先RCFile保证同一行的数据位于同一节点,因此元组重构开销很低;
- 其次像列存储一样,RCFile能够利用列维度的数据压缩,并且能跳过不必要的列读取。
RCFile的一个行组包括三部分:
- 第一部分是行组头部的同步标识,主要用于分割HDFS块中的两个连续行组
- 第二部分是行组的元数据头部,用户存储行组单元的信息,包括行组中的记录数、每个列的字节数 列中每个域的字节数;
- 第三部分是
表格数据段,即实际的列存储数据。在该部分中,同一列的所有域顺序存储。
数据追加:RCFile不支持任意方式的数据写操作,仅提供一种追加接口,这是因为底层的HDFS当前仅仅支持数据追加写文件尾部。
行组大小:行组变大有助于提高数据压缩的效率,但是可能会损害数据的读取性能,因为这样增加了 Lazy 解压性能的消耗。而且行组变大会占用更多的内存,这会影响并发执行的其他MR作业。考虑到存储空间和查询效率两个方面,Facebook 选择 4MB 作为默认的行组大小,当然也允许用户自行选择参数进行配置。
- RcFile,Gzip压缩
CREATE TABLE student_rcfile_gzip (id STRING, name STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
STORED AS RCFILE;
--设置压缩类型为Gzip压缩
SET hive.exec.compress.output=true;
SET mapred.output.compress=true;
SET mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
SET io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec;
--导入数据:
INSERT OVERWRITE TABLE student_rcfile_gzip SELECT id,name FROM student;
--查看数据
SELECT * FROM student_rcfile_gzip;
ORCFile
ORCFile有自己的参数设置压缩格式,一般不使用上述Hive参数设置压缩参数。
- 存储方式:数据按行分块,每块按照列存储;
- 压缩快 快速列存取
- 效率比RCFile高,是RCFile的改良版本。
ORCFile,Zlib压缩
--创建表
CREATE TABLE student_orcfile_zlib (id STRING, name STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
STORED AS ORCFILE TBLPROPERTIES ("orc.compress"="ZLIB");
--导入数据
INSERT OVERWRITE TABLE student_orcfile_zlib SELECT id,name FROM student;
--查询数据
SELECT * FROM student_orcfile_zlib;
- ORCFile,Snappy压缩
--创建表
CREATE TABLE student_orcfile_snappy2 (id STRING, name STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
STORED AS ORCFILE TBLPROPERTIES ("orc.compress"="SNAPPY");
--导入数据
INSERT OVERWRITE TABLE student_orcfile_snappy2 SELECT id,name FROM student;
--查询数据
SELECT * FROM student_orcfile_snappy2;
- 不推荐
一般不推荐使用下述方式。采用下述方式压缩后,结果与上面同类型压缩(Snappy)不同。
--创建表
CREATE TABLE student_orcfile_snappy (id STRING, name STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
STORED AS ORCFILE;
--设置压缩
SET hive.exec.compress.output=true;
SET mapred.compress.map.output=true;
SET mapred.output.compress=true;
SET mapred.output.compression=org.apache.hadoop.io.compress.SnappyCodec;
SET mapred.output.compression.codec=org.apache.hadoop.io.compress.SnappyCodec;
SET io.compression.codecs=org.apache.hadoop.io.compress.SnappyCodec;
--导入数据
INSERT OVERWRITE TABLE student_orcfile_snappy SELECT id,name FROM student;
--查询数据
SELECT * FROM student_orcfile_snappy;
Parquet
- Parquet,Snappy压缩
--创建表
CREATE TABLE student_parquet_snappy (id STRING, name STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
STORED AS PARQUET;
--设置压缩
SET hive.exec.compress.output=true;
SET mapred.compress.map.output=true;
SET mapred.output.compress=true;
SET mapred.output.compression=org.apache.hadoop.io.compress.SnappyCodec;
SET mapred.output.compression.codec=org.apache.hadoop.io.compress.SnappyCodec;
SET io.compression.codecs=org.apache.hadoop.io.compress.SnappyCodec;
--导入数据
INSERT OVERWRITE TABLE student_parquet_snappy SELECT id,name FROM student;
--查询数据
SELECT * FROM student_parquet_snappy;
Avro
- Avro,Snappy压缩
--创建表
CREATE TABLE student_avro_snappy (id STRING, name STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
STORED AS AVRO;
--设置压缩
SET hive.exec.compress.output=true;
SET mapred.compress.map.output=true;
SET mapred.output.compress=true;
SET mapred.output.compression=org.apache.hadoop.io.compress.SnappyCodec;
SET mapred.output.compression.codec=org.apache.hadoop.io.compress.SnappyCodec;
SET io.compression.codecs=org.apache.hadoop.io.compress.SnappyCodec;
--导入数据
INSERT OVERWRITE TABLE student_avro_snappy SELECT id,name FROM student;
--查询数据
SELECT * FROM student_avro_snappy;
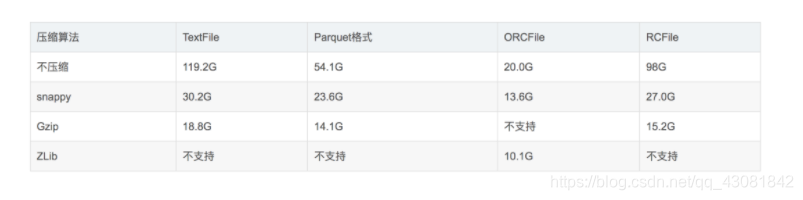
不同压缩算法比较
八、数仓表分区优化
数据仓库创建数仓表时,ETL开发人员基于使用习惯和处理的方便性,经常创建多层分区,来存储数据。但是过多的分区会消耗NameNode大量的资源,并且也会引入小文件的问题。所以对于创建数仓表的分区,要求如下:
- 对于统计数据表、数据量不大的基础表、业务上无累计快照和周期性快照要求的数据表,尽可能的不创建分区,而采用数据合并回写的方式解决;
- 对于一些数据量大的表,如果需要创建分区,提高插叙过程中数据的加载速度,尽可能的只做天级分区。而对于卖点的原始数据,这种特大的数据量的,可以采用小时分区。对于月分区,坚决去掉。
- 对于一些周期快照和累计快照的表,我们尽可能只创建日分区。