续写
在前篇文章中,我简单的介绍了应当如何使用 CNN 来识别和分类语音,并简单的介绍了 matconvnet 的使用以及example的运行。在下面我会说明如何使用该框架训练和测试自己的数据。
预处理数据
在上文中,我已经介绍过先将语音样本生成二维声谱图,这样可以完美的使用 CNN 进行训练和测试数据。我们已经处理好需要使用的方言声谱图样本,即一共采集了70个县级市的方言,先使用单字进行分类,每个单字的时长均为1s,每个地方的方言样本为300个。在(1)中我们已经准备好各个尺寸的图片,如:32*32、224*224、227*227、256*256等。我们首先将方言样本送入几个经典的网络模型进行训练,最先试验的网络模型是可以训练和测试cifar数据的网络模型,在送入网络之前,我们必须要先将图片存成mat文件,即一个可以训练和测试的结构体,在下载的 matconvnet 源码中,也为我们提供了该函数,但是由于该函数相对来说稍微复杂一些,因此在 github 上找到一个简单一些的存mat文件的函数,代码段如下:
function imdb =cnn_plate_setup_data(datadir,size)
inputSize =[size,size,3];
subdir=dir(datadir);
imdb.images.data=[];
imdb.images.labels=[];
imdb.meta.classes = [];
imdb.images.set = [] ;
imdb.meta.sets = {'train', 'val', 'test'} ;
image_counter=0;
trainratio=0.8;
for i=3:length(subdir)
imgfiles=dir(fullfile(datadir,subdir(i).name));
imgpercategory_count=length(imgfiles)-2;
disp([i-2 imgpercategory_count]);
image_counter=image_counter+imgpercategory_count;
for j=3:length(imgfiles)
img=imread(fullfile(datadir,subdir(i).name,imgfiles(j).name));
img=imresize(img, inputSize(1:2));
img=single(img);
imdb.images.data(:,:,:,end+1)=single(img);
imdb.images.labels(end+1)= i-2;
if j-2<imgpercategory_count*trainratio
imdb.images.set(end+1)=1;
else
imdb.images.set(end+1)=3;
end
end
end
dataMean=mean(imdb.images.data,4);
imdb.images.data = single(bsxfun(@minus,imdb.images.data, dataMean)) ;
imdb.images.data_mean = dataMean;
end
一般simplenn结构的网络,均可以使用该函数生成可以送入网络的mat文件。将包含所有样本的尺寸为 32*32 的文件夹路径和图片大小作为参数输入,由于每张图片的大小均不大,因此程序的运行的时间并不长。运行该程序时会返回一个结构体,将此结构体保存成mat文件。
训练和测试数据
一般下载的源码中包含两种可以cifar数据集的网络结构,一个网络结构较为简单一些,一个复杂一些,在未做实验之前,我们并不知道哪个的结果更好,因此我们可以在两个网络上都运行。在运行之前我们可能需要修改网络结构中的一些参数,如最后全连接层的输出神经元的个数,改为70,如下图所示:

,其他参数,如学习率和权值初始化使用的方法等,暂时可以不需要改,因为我们并不知道什么样的参数是适合我们的数据的,因此我们选择使用默认的。其次,如果你的机器上安装了GPU,你还可以修改成在GPU模式下跑,这样可以极大的缩短你程序的运行时间。
实验结果
实验结束后,会输出一张图,如下图所示:
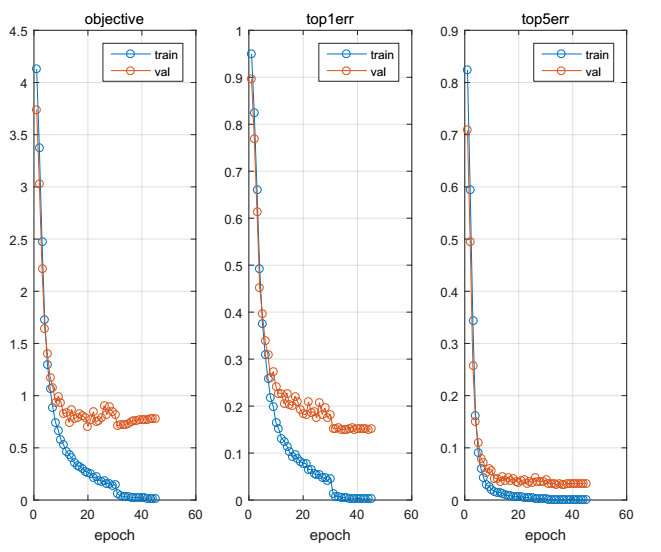
其中,top1err表示的就是分到其原属于的类的错误率,从图中可以看出,在该网络下,大概可以达到85%左右, top5err表示的是分到与其最接近的5个类别中的错误率,这个指标我们一般不做参考。