续写
在(2)中介绍了使用 matconvnet 中提供的examples中的可以训练cifar数据库的网络训练自己的方言样本数据。接下来介绍使用另外两种网络 vgg 和 alexnet 这两种网络模型也都较为经典。
vgg
vgg网络模型较为复杂一些,它可以分为vgg-f 、vgg-s、vgg-m 等。在这里我使用的是vgg-f,因为相对而言vgg-f的网络结构简单一些,也比较适用我们的数据。vgg-f 的网络模型在 imagenet 文件夹下,将程序中的模型名称改为vgg-f之后,可以在GPU下使用该网络训练自己的数据。vgg-f一般是用于做人脸分类和识别的,从名称上即可看出。实验的结果还是可以的,准确率可以达到90%左右,实验结果图如下:
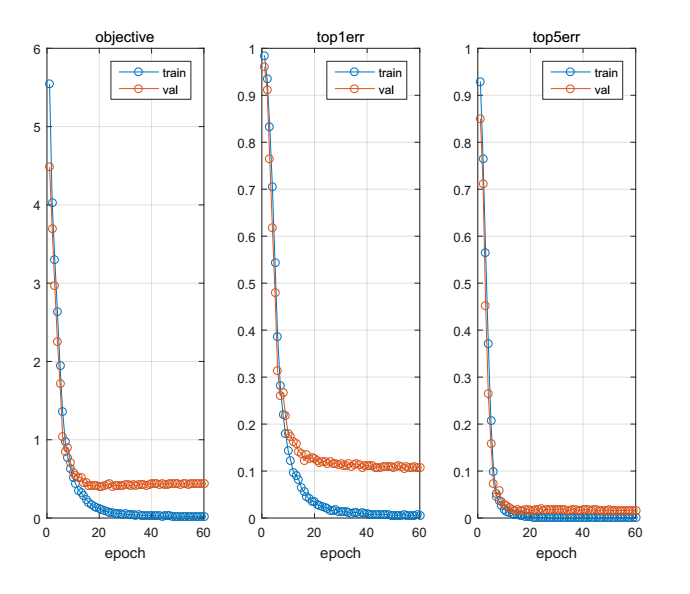
实验数据说明:vgg-f 需要的实验图片大小为224*224,在程序运行之前,我们需要将样本数据保存到 mat 文件下,但是可能由于某些内存限制,我们的21000张样本不能一次保存完成。因此我这次只保存了14000张,即每个类的样本为200张。
alexnet
alexnet的网络结构稍微复杂一些,但是alexnet作为经典网络模型,其实验结果确实较为好一些。实验需要改动代码的地方与之前提到的其他网络均相同,因此在这里就不说了。下面展示一下实验结果并说明一下实验数据。
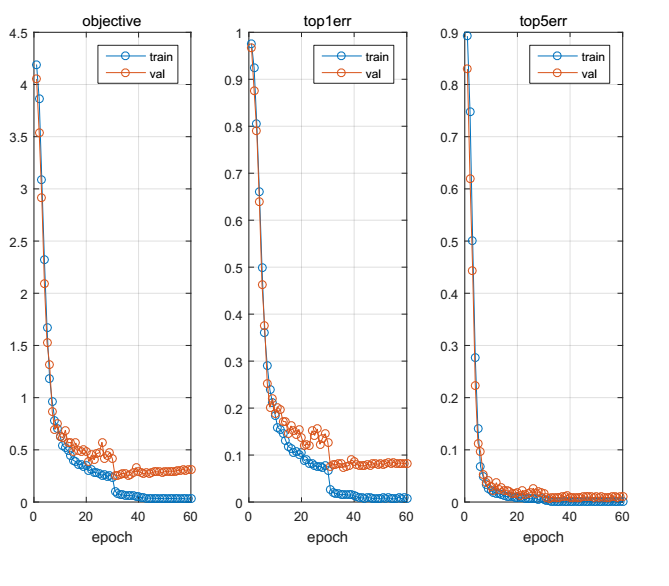
实验1
刚开始每个类的样本数量为200张,总共14000张样本,实验结果如下:
实验2
每个类的样本数量为300张,总共21000张样本,实验结果如下:
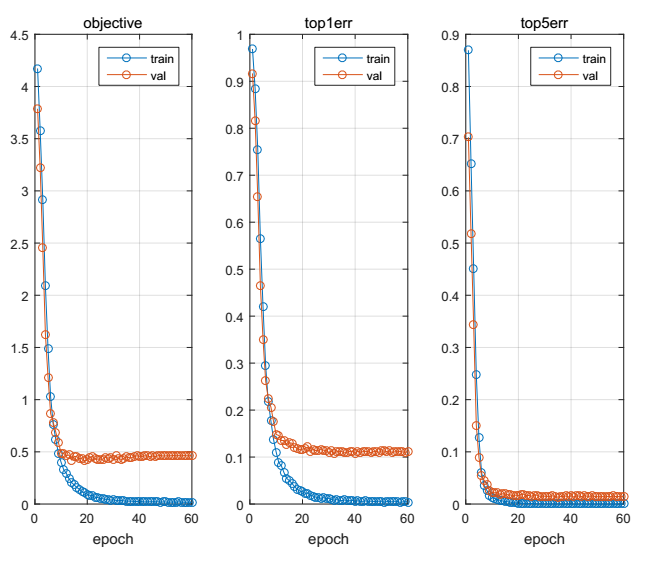
实验结果说明:上述每个类的300张与之前采用的数据不一样,该数据样本是词语样本,之前所训练的数据样本均是单字。