1、什么是梯度消失、梯度爆炸
以BP反向传播为例,链式求导法则,前面的隐藏层的权值和偏值依赖后面的层,当激活函数的时,层数越多时,求导结果越小,导致前面几层的权值和偏重与初始值没有较大区别,参数更新缓慢,这就是所谓的梯度消失情况。
同理,梯度爆炸:链式求导导致结果特别大,参数更新非常快。由此可见,梯度消失和梯度爆炸主要是因为网络太深,权值更新不稳定造成的,本质原因是因为反向传播中的连乘效应导致的。
改进方法:
(1)选择合适的激活函数,如:用Relu函数代替Sigmoid函数
(2)对于RNN网络中存在的梯度消失问题,可以选择LSTM结构代替;
具体数学过程解释梯度消失和梯度爆炸,参考博客:https://ziyubiti.github.io/2016/11/06/gradvanish/
2、LSTM(Long Short Term Memory)结构
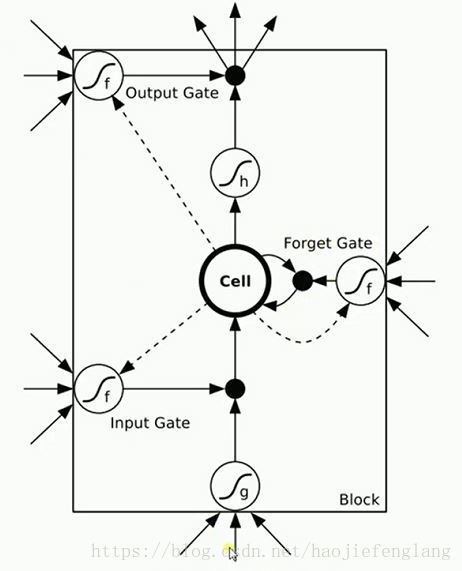
三个门限:
(1)input gate对输入信号进行选择
(2)forget gate选择忘记哪些信号;
(3)output gate选择信号输出;
这三个门限的三个输入时一样的,激活函数一般选择tanh();
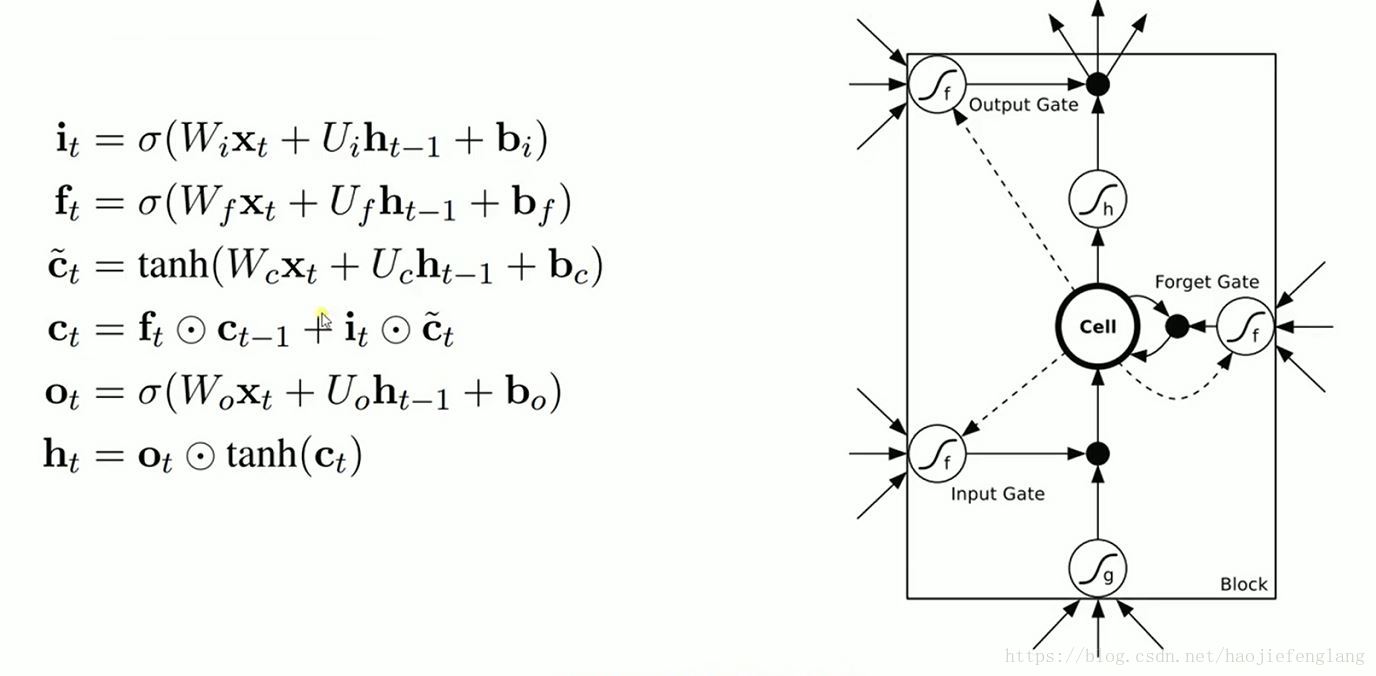
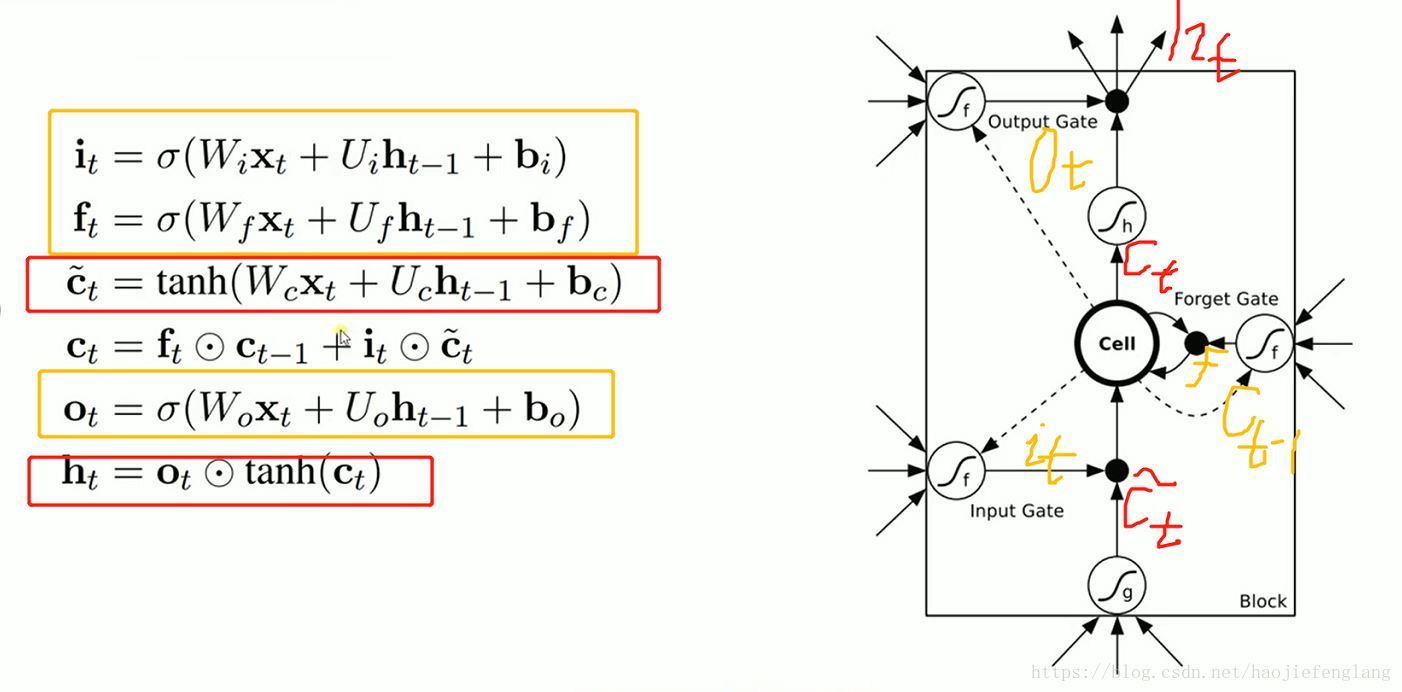
其中,各个结果代表标注在下图中:
具体实现代码如下:
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist=input_data.read_data_sets('MNIST_data/',one_hot=True)
#输入图片:28*28
n_inputs=28 #一行28个数据,输入神经元的个数
max_time=28 #共28行
lstm_size=100 #隐藏层100个基础单元
n_classes=10 #输出神经元的个数
batch_size=50
n_batch=mnist.train.num_examples//batch_size
x=tf.placeholder(tf.float32,[None,784])
y=tf.placeholder(tf.float32,[None,10])
weights=tf.Variable(tf.truncated_normal([lstm_size,n_classes],stddev=0.1))
biases=tf.Variable(tf.constant(0.1,shape=[n_classes]))
def RNN(X,weights,biases):
#inputs=[batch_size,max_time,n_inputs]
inputs=tf.reshape(X,[-1,max_time,n_inputs])
#定义LSTM基本cell
lstm_cell=tf.contrib.rnn.BasicLSTMCell(lstm_size)
outputs,final_state=tf.nn.dynamic_rnn(lstm_cell,inputs,dtype=tf.float32)
results=tf.nn.softmax(tf.matmul(final_state[1],weights)+biases)
return results
#final_state[0]是cell state
#final_state[1]是hidden_state,最后时间序列一次输出的信号,28个序列,产生1个结果
#outputs记录每一次时间序列的输出结果,28个序列,产生28个结果,所以output第27个序列的输出结果和final_state[1]是一样的
#计算RNN的结果
prediction=RNN(x,weights,biases)
#计算损失函数
cross_entropy=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y,logits=prediction))
optimizer=tf.train.AdamOptimizer(1e-4)
train_step=optimizer.minimize(cross_entropy)
#结果存放在一个bool类型列表中
correct_prediction=tf.equal(tf.argmax(y,1),tf.argmax(prediction,1))
#测试准确率
accuracy=tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for epoch in range(6):
for batch in range(n_batch):
batch_xs,batch_ys=mnist.train.next_batch(batch_size)
sess.run(train_step,feed_dict={x:batch_xs,y:batch_ys})
acc=sess.run(accuracy,feed_dict={x:mnist.test.images,y:mnist.test.labels})
print("Iter "+str(epoch)+" Test Accuracy= "+str(acc))
运行结果:
Extracting MNIST_data/train-images-idx3-ubyte.gz
Extracting MNIST_data/train-labels-idx1-ubyte.gz
Extracting MNIST_data/t10k-images-idx3-ubyte.gz
Extracting MNIST_data/t10k-labels-idx1-ubyte.gz
Iter 0 Test Accuracy= 0.7476
Iter 1 Test Accuracy= 0.8575
Iter 2 Test Accuracy= 0.8893
Iter 3 Test Accuracy= 0.9181
Iter 4 Test Accuracy= 0.927
Iter 5 Test Accuracy= 0.9359