基于BP神经网络的数字识别基础系统(三)
(接上篇)
上一篇的链接:http://blog.csdn.net/z_x_1996/article/details/60779141
上篇博文中笔者简单的介绍了一下梯度下降算法,这里接着为大家介绍增量梯度下降算法。
2.2.2增量梯度下降法
增量梯度下降法又叫做随机梯度下降法,很多人对后一个叫法更加熟悉,其实两者是一个东西。增量梯度下降算法不再以所有的样本来算权重的改变值,而是对每个单独的样本的误差增量计算权值更新,得到近似的梯度下降搜索。这种改变有一定的好处也有一些不好的地方。
好处当然是每次不用加载所有的样本,正如上一篇我们提过的那样(需要提醒的是如果你是以误差作为终止条件的话还是需要一次性加载所有的样本)。同时,增量梯度下降有时可以避免陷入局部最小值。缺点大家应该都能够看出来,当不再每次都使用所有的样本进行权值更新时,需要更多的训练次数,因为每次优化都不是严格的,但是结果往往都在最优解附近。
对上一篇博文中的算法稍作修改就可以得到我们需要的增量梯度下降算法
IncGradDesc(样本空间D,下降步调m){
将每个网络权值W[i]初始化为某个小的随机值;
while(非终止条件){
初始化每个deltaW[i]为0;
for(d=0;d<D.size();d++){
把样本作为系统的输入,计算Od;
//计算梯度增量
for(i=0;i<单个样本总元素数量;i++){
deltaW[i] = m*(td-Od)*input[d][i];
}
//更新权值
for(i=0;i<单个样本总元素数量;i++){
W[i] = W[i] + deltaW[i];
}
}
}
}
这里一定要对比这个与梯度下降法的差别!
其实梯度下降系列除了上述两种还有一种折中的方法叫做批量梯度下降算法,就是在大样本集合中抽取小样本集合分别来对网络进行训练。这里笔者不再细讲,看懂了上述两种方法自然就知道批量梯度下降算法是怎么回事了。
2.3多层神经网络
上述的两种方法只是对于简单的单层的神经网络的训练方法,现在我们把训练方法推广到多层神经网络,并且加上Sigmoid单元来对每一个单元的输出规范化,非线性化。其实基本的思路和上面一致,只不过这里计算权值时会有多层的权值的更新。这里我们为了方便,讲解三层全连接的神经网络,即一个输入层,一个隐藏层,一个输出层。
2.3.1Sigmoid函数介绍
因为涉及到求导等多个操作,这里需要熟悉Sigmoid函数。

定义域为为整个实域,值域在(0,1)。
另外Sigmoid函数有一个很棒的性质,就是f(z)对z求导后结果为f(z)*(1-f(z))。这大大简化了梯度下降算法的导数计算。
2.3.2反向传播(Back Propagation,BP)算法
讲了这么多笔者终于进入到最核心的位置了,真是太开心了T-T。这个讨论完以后就进入实战(也就是标题上所说的系统)了,笔者收到了很多朋友的私信,希望笔者贴出源码,大家不要急,最后我会贴出来源码的,包括训练集以及测试集都会给大家,但是这里需要说明的是这些资源都是来至第一篇博客开头所说的那本书附带的资源,所以大家使用时注意一下版权问题,如果出问题后果自负。
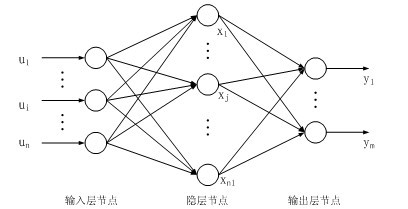
将多个Sigmoid单元互相连成如图所示的三层结构网络,反向传播算法可用来计算网络的权值。因为这里有多个输出,所以误差函数需要做一小点的更改,即将每个输出单元的误差加起来。

下面介绍训练方法。
(考虑到手打公式实在麻烦,这里笔者采用手写拍照的方式,希望大家谅解一下^_^)

同样给出伪代码算法
BackPropagation(样本空间D,下降步调m){
将每个网络权值weightIH[h][i],weightHK[k][h]初始化为某个小的随机值;
while(非终止条件){
初始化每个deltaK[k],deltah[h]为0;
for(d=0;d<D.size();d++){
把样本作为系统的输入,计算output[k]和hidden[h];
//计算梯度增量,延网络反向传播
for(k=0;k<output.size;k++){
deltaK[k] = output[k]*(1-output[k])*(t[k]-output[k]);
}
for(h=0;h<hidden.size;h++){
delta[h] = 0;
for(k=0;k<output.size;k++){
deltaH[h] += hidden[h]*(1-hidden)*weightHK[k][h]*deltaK[k];
}
}
}
//更新权值
for(k=0;k<output.size;k++){
for(h=0;h<hidden.size;h++){
weightHK[k][h] += m*deltaK[k]*hidden[h];
}
}
for(h=0;h<hidden.size;h++){
for(i=0;i<input.size;i++){
weightIH[h][i] += m*deltaH[h]*input[i];
}
}
}
}
当然为了避开局部最小点,更新时也可以加上一个冲量项,这里笔者不再详细叙述了。
到此为止,我们所有的准备工作就已经完成了,下一篇开始便是应用到实战中了。
下一篇博客链接:http://blog.csdn.net/z_x_1996/article/details/68633264