基于BP神经网络的数字识别基础系统
1.前言
随着《最强大脑》中的人机大战播放以及AlphaGo的围棋领域的攻克,深度学习开始进入了人们的视野,事实上神经网络作为深度学习的基础慢慢成为了人工智能以及模式识别的核心。其实神经网络的理论基础并不困难,甚至可以说是十分的简单。
这里,笔者通过一个数字识别基础系统来介绍神经网络中的BP神经网络,这里之所以说“基础”是因为这个系统只完成了核心部分:固定图片像素大小的单数字识别。而对于前期图像的处理以及感兴趣区域的分割并没有更多的介绍,若要完成一个完善的数字识别系统,那么前期的图像处理(包括去噪,二值化,图像分割)也需要进行实现。文章参考了人民邮电出版社出版的由张铮主编的《数字图像处理与机器视觉(第二版)》,很多地方书中都有详细的叙述,若对细节有什么不懂的地方可以查阅该书。
另外,笔者发现目前网上存在的很多类似的内容是基于C++等语言的,很少是基于java语言的(虽然由于语言的特性,这个情况是很正常的),于是笔者打算使用java来实现这个系统,这样,也方便了系统向移动端的移植。
由于笔者能力有限,难免出现错误或者并不完美的地方,也欢迎大家一起讨论学习。
2.BP神经网络简介
2.1 神经网络
在BP神经网络之前,笔者避不开的要介绍基础的神经网络。在这里笔者略去了神经网络的发展历史,直接介绍其实现以及理论基础。若对其发展历史有兴趣的读者可以直接去网上搜索一下,鉴于目前神经网络的火热程度,应该是一搜一大把(笑)。
首先我们拿人的神经作为切入的点,根据我们所了解的知识,人的大脑有无数个神经细胞相互联动工作,从而使得人们有了各种各样的识别能力以及思考的能力。神经网络架构的本质便是模仿人类的神经系统(当然,目前还无法做到像人的神经系统一样)。我们来看下面一张摘自http://image.so.com/v?ie=utf-8&src=hao_360so&q=神经系统&correct=神经系统&fromurl=http%3A%2F%2Fwww.taopic.com%2Ftuku%2F201304%2F343874.html&gsrc=1#ie=utf-8&src=hao_360so&q=%E7%A5%9E%E7%BB%8F%E7%B3%BB%E7%BB%9F&correct=%E7%A5%9E%E7%BB%8F%E7%B3%BB%E7%BB%9F&fromurl=http%3A%2F%2Fwww.taopic.com%2Ftuku%2F201304%2F343874.html&gsrc=1&lightboxindex=2&id=c727dd4e09abe72ed82c093ce677c835&multiple=0&itemindex=0&dataindex=2的图片。

我们发现,其实人的神经细胞之间互相连接,传递信息,这启发了我们做一个神经细胞的简单抽象,如下摘自http://image.so.com/v?q=神经网络&src=srp&correct=神经网络&fromurl=http%3A%2F%2Fbaike.cntronics.com%2Fabc%2F2039&gsrc=1#q=%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C&src=srp&correct=%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C&fromurl=http%3A%2F%2Fbaike.cntronics.com%2Fabc%2F2039&gsrc=1&lightboxindex=5&id=ce9cc854438b05a897e6bfa94eb9fa26&multiple=0&itemindex=0&dataindex=52图。

解释一下抽象图的含义:每个神经细胞与很多上级细胞相连,将上级细胞的输出作为自己的信号输入,然后通过一定的处理后输出信号给下一级细胞。当然这里所谓的一定的处理可以各有各的不同,目前普遍采用的是最为简单的线性处理
即如图的

那么现在的问题是如何确定系数w,从而使得输出与输入相对应呢?或者换一种更加具体的问法:如何能够做到给你一个数字“1”的图片(可能是各种形式,各种书写),你就能够知道它代表的字符是什么?如果不知道如何下手的话我们不妨再一次拿人的大脑来思考。即有了以下的思考过程:
- 刚出生的婴儿能够认识数字吗?——不能
- 婴儿如何认识数字的?——老师或家长交的
- 如何教?——不断拿出数字让婴儿识别并且告诉其正确与否,不断的反馈学习。
思考到这里,确定系数的方式便显得自然而然了:给出大量的样本以及其标签信息,然后不断的改变系数使得在样本空间内output(即输入的线性和)与标签输出在一定的误差范围内。这就是有监督的训练的过程。通过训练我们确定了w系数大小使得其在样本空间内能够给出一定误差内的正确结果。
如上,我们就知道了神经细胞相关的一些重要的信息。
现在回到我们人的大脑,正如我们开头所说的那样,人的大脑由无数个神经细胞相互连接,也就是说,一个功能较为强大的神经网络识别系统需要足够丰富的神经细胞。那么我们现在需要考虑神经系统的构建。
为了更加简单的管理以及更加清晰的逻辑,我们构建的方式就像封装一样,有细胞,层,系统。
- 神经细胞是构成的基本单位
- 层由多个神经细胞构成
- 系统由多个层连接而成

在上述并不十分详细(详细的还是要看看书)的描述中,我们已经了解了神经网络的组成方式。然而这里依然存在着两个十分重要的问题。
- 训练过程中,系数w如何改变的问题,即寻找一个比较好的改变方式,使得w能够更快的收敛到正确的系数。
- 使用这样的神经网络,只能拟合线性的求解方式,无法拟合非线性的求解方式。
现在我们拿单个神经细胞的训练来考虑着两个问题。现在我们有n对样本<xd,yd>,其中xd为样本向量,而yi为目标输出。wi为对应的加权系数,这里先不考虑偏置项bias。因为偏置项bias可以简单的看做输入为1,加权系数为bias从而整合到样本中。即

首先我们先来看看第二个问题:拟合非线性的求解方式。
这里我们常用的可以使用Sigmoid函数来将输出结果映射后再输出。Sigmoid函数的映射关系式以及函数图摘自http://image.so.com/v?q=sigmoid&src=srp&correct=sigmoid&fromurl=http%3A%2F%2Fwww.myexception.cn%2Fother%2F1699185.html&gsrc=1#q=sigmoid&src=srp&correct=sigmoid&fromurl=http%3A%2F%2Fwww.myexception.cn%2Fother%2F1699185.html&gsrc=1&lightboxindex=4&id=b27d9648f7f749d6e367ea1a9bbe54f9&multiple=0&itemindex=0&dataindex=4

式子中的z便是我们的Output,f(z)为处理后的输出。
这里有两个好处:一是在多层网络中可以使系统能够进行非线性的映射,二是能够将解压缩在0到1这个区间内。

提出的两个问题即
- 训练过程中,系数w如何改变的问题,即寻找一个比较好的改变方式,使得w能够更快的收敛到正确的系数。
- 使用这样的神经网络,只能拟合线性的求解方式,无法拟合非线性的求解方式(呃,笔者后面发现其实Sigmoid也算是线性拟合,具体请看笔者的《机器学习数学原理系列》)。
中的第二个问题已经得到了较好的解决,第一个问题笔者准备在这一篇进行讨论。
2.2 系数的确定
首先笔者必须提前申明的是,不同情况下的求最优的方式多种多样,各有各的特点,也有很多优秀的算法。这里笔者主要介绍两种比较经典并且通用的算法并且比较这两种方法的优劣从而方便读者进行选择。当然老规矩,如果有什么不妥或者错误的地方,欢迎读者批评指出。
这里笔者需要说明:算法若要完全看懂需要一定的高数内容,主要涉及到条件极值的求法等等。若有遗忘,建议重点看一下导数(这就很尴尬了)以及拉格朗日乘子法求条件极值。当然如果使用编译好的工具库的话,那会使用就行了,可以跳过本段,但是如果懂的话当然更好。
首先笔者分析一下我们的核心式子(也是在数学形式上明确一下问题):
笔者准备先从最简单的线性决策函数开始切入到BP神经网络的最优系数求解。即确定一组Wi使得以上式子满足样本在一定误差内的正确输出。
为了方便叙述,我们先标注几个数学符号
- 角标d:d用来标注样本序号。
- t:目标输出,即标签输出,其中td是第d个样本的标签输出,即output。
- O:实际输出,其中Od是第d个样本的实际输出。
首先我们定义好一个度量标准来衡量在当前系数下的训练误差:

注:这里之所以乘上1/2是为了求导时方便约去产生的2。另外,误差的定义方式选取平方和形式的原因可以参考线性回归模型的极大似然估计法:http://blog.csdn.net/z_x_1996/article/details/70176819。
到这里我们有了一个衡量的标准,问题便进一步数学化、明确化了。
即我们需要寻找到一组系数w,使得E取最小值。
另外笔者在这里要强调的是,我们在处理问题的时候一定对问题有明确的认识,换句话说,我们要时刻谨记着我们的已知条件和需要求解的变量。比如在这个式子中间,t是标签输出,是常量;o是在取定系数w过后系统的输出值,是一个关于w的函数,是个变量;d是样本空间中的一个样本,是常量。
问题到了这一步很多读者会说这还不简单,这就是一个多元函数求极值的问题,求偏导后令其偏导数为0得到方程组后解方程组就可以确定系数w了啊。
没错,这确实是很棒很精确的一种方法,但是实际操作起来会十分棘手,笔者接下来就来说明为什么不采用这个看上去简洁而且清晰的方法。
首先我们来根据这个思路看一下过程,首先我们要求出各个偏导

这里input的含义是样本d的第i个元素。
现在我们来想一想一张图片有多少个元素,即多少分辨率,别的不说,我们就来看100*100分辨率的图片,这样的图片有10000个像素也就是说有10000个元素,换句话说i最大能够取到10000,这也就意味着这个偏导等于0的方程组会有10000个方程。更令人头疼的是,线性的决策函数在很多情况下是不能满足要求的,以后我们用到的一般都是非线性的函数,那么其偏导数也不再是线性的。那么我们需要面对的便是一个10000元的包含10000个方程的非线性方程组求解。我们姑且不谈方程组的可解性如何,就算解出来,对于一个非线性的方程来说,多解是一个十分普遍的现象。假如wi有ni个值,那么我们需要确定的极值将会有n1到n10000的连乘个。在这么多个值中寻找最优值也是一个十分费时的事情。
既然求偏导的方法被我们否定了,那么我们需要采用什么样的方法才能确定使得E最小的wi呢?
接下来便进入重头戏了,目前常用的两种方法:1.梯度下降法。2.增量梯度下降法。
2.2.1梯度下降法
梯度下降法(Gradient Descent)是利用了高等数学中梯度(Gradient)的概念。我们都知道梯度是方向导数最大的方向,换句话说,梯度向量指出了上升最快的方向,那么梯度下降法的思路便是先随机给出一组w,然后计算梯度后沿着梯度相反的方向w改变一个小量,这样不断的进行下去,从而到达极值点。
下面笔者便给出梯度下降法的推导。
(用电脑打公式实在是太麻烦了,这里笔者采用手写拍成图的方式,希望大家谅解一下~)

那么我们把思路代码化,先写出来训练w的伪代码
(这里为了方便手打,用m表示图中的下降步调,用deltaW代替W的改变微元)
GradDesc(样本空间D,下降步调m){
将每个网络权值W[i]初始化为某个小的随机值;
while(非终止条件){
初始化每个deltaW[i]为0;
for(d=0;d<D.size();d++){
把样本作为系统的输入,计算Od;
//计算梯度增量
for(i=0;i<单个样本总元素数量;i++){
deltaW[i] = deltaW[i] + m*(td-Od)*input[d][i];
}
}
//更新权值
for(i=0;i<单个样本总元素数量;i++){
W[i] = W[i] + deltaW[i];
}
}
}
这里读者需要注意的有三点:
- 下降步调m的设置,一般经验值为0.3左右,当然m越大以为这更快的训练速度,但是也会承担在极值周围来回震荡的风险。
- 终止条件的设置。笔者一般喜欢将终止条件设置为当误差E小于某个值。也有很多设置成训练多少次的。这个视不同情况来定。笔者需要提醒读者的是:训练次数的增多并不意味着对未知样本分类准确性的提高(只能提高对训练样本的识别准确率),这种情况叫做过拟合,后面几篇博文中如果有机会笔者再来讲。
- 在更加普遍的情况下(非线性情况下),我们会遇到多个极值的问题,使用梯度下降方法有时容易陷在某个局部最小值而不是全局最小值,这将导致得不到最优的解,在后面博文中我们将通过改善算法来改善这个问题。
同时这里其实还有一个问题,(尽管大部分书上都没有讲,纯属笔者个人想法)而笔者个人认为这个问题是区别梯度下降算法和增量梯度下降算法的比较关键的地方:我们可以发现在这个算法中,我们为了求出deltaW的值,每次必须加载所有的样本从而来求那个segma和,当样本很多的时候(这是十分普遍的),一次性需要加载所有的样本将显得十分吃力,而增量梯度下降算法则在一定程度上用时间的代价换取空间的代价从而解决了这个问题。
2.2.2增量梯度下降法
增量梯度下降法又叫做随机梯度下降法,很多人对后一个叫法更加熟悉,其实两者是一个东西。增量梯度下降算法不再以所有的样本来算权重的改变值,而是对每个单独的样本的误差增量计算权值更新,得到近似的梯度下降搜索。这种改变有一定的好处也有一些不好的地方。
好处当然是每次不用加载所有的样本,正如上一篇我们提过的那样(需要提醒的是如果你是以误差作为终止条件的话还是需要一次性加载所有的样本)。同时,增量梯度下降有时可以避免陷入局部最小值。缺点大家应该都能够看出来,当不再每次都使用所有的样本进行权值更新时,需要更多的训练次数,因为每次优化都不是严格的,但是结果往往都在最优解附近。
对上一篇博文中的算法稍作修改就可以得到我们需要的增量梯度下降算法
IncGradDesc(样本空间D,下降步调m){
将每个网络权值W[i]初始化为某个小的随机值;
while(非终止条件){
初始化每个deltaW[i]为0;
for(d=0;d<D.size();d++){
把样本作为系统的输入,计算Od;
//计算梯度增量
for(i=0;i<单个样本总元素数量;i++){
deltaW[i] = m*(td-Od)*input[d][i];
}
//更新权值
for(i=0;i<单个样本总元素数量;i++){
W[i] = W[i] + deltaW[i];
}
}
}
}
这里一定要对比这个与梯度下降法的差别!
其实梯度下降系列除了上述两种还有一种折中的方法叫做批量梯度下降算法,就是在大样本集合中抽取小样本集合分别来对网络进行训练。这里笔者不再细讲,看懂了上述两种方法自然就知道批量梯度下降算法是怎么回事了。
2.3多层神经网络
上述的两种方法只是对于简单的单层的神经网络的训练方法,现在我们把训练方法推广到多层神经网络,并且加上Sigmoid单元来对每一个单元的输出规范化,非线性化。其实基本的思路和上面一致,只不过这里计算权值时会有多层的权值的更新。这里我们为了方便,讲解三层全连接的神经网络,即一个输入层,一个隐藏层,一个输出层。
2.3.1Sigmoid函数介绍
因为涉及到求导等多个操作,这里需要熟悉Sigmoid函数。
定义域为为整个实域,值域在(0,1)。
另外Sigmoid函数有一个很棒的性质,就是f(z)对z求导后结果为f(z)*(1-f(z))。这大大简化了梯度下降算法的导数计算。
2.3.2反向传播(Back Propagation,BP)算法
讲了这么多笔者终于进入到最核心的位置了,真是太开心了T-T。这个讨论完以后就进入实战(也就是标题上所说的系统)了,笔者收到了很多朋友的私信,希望笔者贴出源码,大家不要急,最后我会贴出来源码的,包括训练集以及测试集都会给大家,但是这里需要说明的是这些资源都是来至第一篇博客开头所说的那本书附带的资源,所以大家使用时注意一下版权问题,如果出问题后果自负。
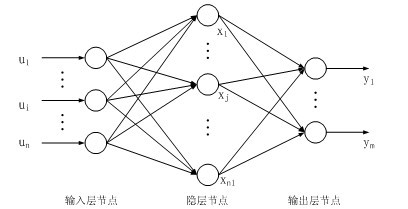
将多个Sigmoid单元互相连成如图所示的三层结构网络,反向传播算法可用来计算网络的权值。因为这里有多个输出,所以误差函数需要做一小点的更改,即将每个输出单元的误差加起来。

(考虑到手打公式实在麻烦,这里笔者采用手写拍照的方式,希望大家谅解一下^_^)

同样给出伪代码算法
BackPropagation(样本空间D,下降步调m){
将每个网络权值weightIH[h][i],weightHK[k][h]初始化为某个小的随机值;
while(非终止条件){
初始化每个deltaK[k],deltah[h]为0;
for(d=0;d<D.size();d++){
把样本作为系统的输入,计算output[k]和hidden[h];
//计算梯度增量,延网络反向传播
for(k=0;k<output.size;k++){
deltaK[k] = output[k]*(1-output[k])*(t[k]-output[k]);
}
for(h=0;h<hidden.size;h++){
delta[h] = 0;
for(k=0;k<output.size;k++){
deltaH[h] += hidden[h]*(1-hidden)*weightHK[k][h]*deltaK[k];
}
}
}
//更新权值
for(k=0;k<output.size;k++){
for(h=0;h<hidden.size;h++){
weightHK[k][h] += m*deltaK[k]*hidden[h];
}
}
for(h=0;h<hidden.size;h++){
for(i=0;i<input.size;i++){
weightIH[h][i] += m*deltaH[h]*input[i];
}
}
}
}
当然为了避开局部最小点,更新时也可以加上一个冲量项,这里笔者不再详细叙述了。
3.系统设计
上一篇笔者已经讨论完了BP神经网络需要用到的知识点,接下来就开始设计符合我们标题的系统了。
首先我们要确定训练集以及测试集:下载链接:http://download.csdn.net/detail/z_x_1996/9799552。


我们来分析训练集,首先训练的图片格式为bmp位图格式,位深度为8,分辨率为32*64,训练集分为0~9十个文件夹,每个文件夹里面有4张不同字体的相同数字(数字同文件夹名称),同时训练集里有一个target.txt文件,里面文件代表每一张图片的目标输出,一行就是一张图的目标输出,我们很容易看出输出有10个单元,每个数字对应一组输出。这里并没有采用二进制编码而是采用一对一编码,这样的好处在于可以很容易获得置信度,但是坏处也是显而易见的,那就是当样本类型很多时网络的输出会急剧增加。
我们再来看输入层,为了精简输入信息,我们将图片压缩,横竖均只取1/4的像素,均匀分布。这样输入单元有32*64/16=128个输入单元。
隐藏层有多种选择,首先确定隐藏层数,考虑到该数据组分类比较简单,故选择一层隐藏层,这层的单元数有多种选择,不同的选择会有不同的影响,这个影响我们后面再谈(如果忘了请记得提醒笔者),这里我们选择为8个。
至此我们便确定了网络结构,三层:
- 输入层:128单元
- 隐藏层:8单元
- 输出层:10单元
这样我们也可以把权重向量的size确定了:
- weightHK[][]:10x(8+1)
- weightIH[][]:8x(128+1)
(这里+1的原因是要加上一个常数偏置项)
首先笔者先给出系统工程的结构图:

3.1 神经网络包
我们先构建神经网络元素包 com.zhangxiao.element。
首先自然来到我们SNeuron.java文件,该文件为一个神经元。
package com.zhangxiao.element;
public class SNeuron {
private double[] weight;
private double[] input;
private int length;
public SNeuron(double[] input,double[] weight){
this.input = input;
this.length = input.length;
this.weight = weight;
}
//获得Sigmoid输出结果。
public double getResult(){
double sum = weight[0];
for(int i=0;i<length;i++){
sum += input[i]*weight[i+1];
}
return 1/(Math.exp(-sum)+1);
}
}
没有什么好说的,然后是构建一层 Layer.java,该文件为一层的类。
package com.zhangxiao.element;
public class Layer {
private SNeuron[] cells;
private int number;
private double[] input;
private double[] output;
private double[][] weight;
//初始化神经层
public Layer(int number,double[] input,double[][] weight){
this.number = number;
this.input = input;
this.weight = weight;
output = new double[number];
cells = new SNeuron[number];
for(int i=0;i<number;i++){
cells[i] = new SNeuron(this.input,this.weight[i]);
}
}
//获得神经层输出结果数组
public void goForward() {
for(int i=0;i<number;i++){
output[i] = cells[i].getResult();
}
}
public double[] getOutput() {
return output;
}
}
然后是构建一个神经系统(目前笔者写的代码只支持3层,即一个隐藏层),NervousSystem1H.java
package com.zhangxiao.element;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
public class NervousSystem1H {
private double[][] trainData;
private double[] input;
private double[] output;
private double[] connection;
public double[] getInputLayer() {
return input;
}
private double[][] target;
private Layer[] layers;
private int[] structure;
private double efficiency;
private double[] deltaK;
private double[] deltaH;
private double[][] weightIH;
private double[][] weightHK;
//初始化神经系统
public NervousSystem1H(double efficiency,int[] structure,double[][] trainData,double[][] target) throws IOException{
if(trainData[0].length!=structure[0]){
System.out.println("训练数据长度与输入层长度不一致!");
return;
}
this.trainData = trainData;
this.target = target;
this.efficiency = efficiency;
this.structure = structure;
//初始化数组
this.input = new double[structure[0]];
deltaK = new double[structure[2]];
deltaH = new double[structure[1]];
for(int k=0;k<deltaK.length;k++){
deltaK[k] = 0;
}
for(int h=0;h<deltaH.length;h++){
deltaH[h] = 0;
}
weightIH = new double[structure[1]][structure[0]+1];
weightHK = new double[structure[2]][structure[1]+1];
for(int h=0;h<structure[1];h++){
for(int i=0;i<structure[0]+1;i++){
while(Math.abs((weightIH[h][i] = Math.random()/10-0.05))==0){}
}
}
for(int k=0;k<structure[2];k++){
for(int h=0;h<structure[1]+1;h++){
while(Math.abs(weightHK[k][h] = Math.random()/10-0.05)==0){}
}
}
//连接各层
layers= new Layer[2];
layers[0] = new Layer(structure[1],this.input,weightIH);
connection = layers[0].getOutput();
layers[1] = new Layer(structure[2],connection,weightHK);
this.output = layers[1].getOutput();
}
//训练神经网络
public void train() throws IOException{
double error = 0;
int process = 0;
while((error = getError())>0.0001){
System.out.println(process++ +":"+error);
for(int d=0;d<trainData.length;d++){
//正向传播输出
goForward(trainData[d]);
double[] outputK = layers[1].getOutput();
double[] outputH = layers[0].getOutput();
for(int k=0;k<deltaK.length;k++){
deltaK[k] = outputK[k]*(1-outputK[k])*(target[d][k]-outputK[k]);
}
for(int h=0;h<deltaH.length;h++){
deltaH[h] = 0;
for(int k=0;k<deltaK.length;k++){
deltaH[h] += outputH[h]*(1-outputH[h])*deltaK[k]*weightHK[k][h+1];
}
}
//更新权值
for(int k=0;k<weightHK.length;k++){
weightHK[k][0] += efficiency*deltaK[k];
for(int h=1;h<weightHK[0].length;h++){
weightHK[k][h] += efficiency*deltaK[k]*outputH[h-1];
}
}
for(int h=0;h<weightIH.length;h++){
weightIH[h][0] += efficiency*deltaH[h];
for(int i=1;i<weightIH[0].length;i++){
weightIH[h][i] += efficiency*deltaH[h]*trainData[d][i-1];
}
}
}
}
System.out.println("最终误差为:"+getError());
}
//获取输出结果数组
public void goForward(double[] input){
setInput(input);
for(int i = 0;i<structure.length-1;i++){
layers[i].goForward();
}
}
//获取误差
public double getError(){
double error = 0;
for(int d=0;d<trainData.length;d++){
goForward(trainData[d]);
for(int i=0;i<target[0].length;i++){
error += 0.5*(target[d][i]-output[i])*(target[d][i]-output[i]);
}
}
return error/trainData.length/10;
}
//将训练好的权重保存到txt文件中方便查看以及二次调用
public boolean saveWeight(File file) throws IOException{
boolean flag = false;
BufferedWriter bw = new BufferedWriter(new FileWriter(file));
//写入weightIH
for(int h=0;h<weightIH.length;h++){
for(int i=0;i<weightIH[0].length;i++){
bw.append(Double.toString(weightIH[h][i])+" ");
}
bw.append("\r\n");
bw.flush();
}
//写入weightHK
for(int k=0;k<weightHK.length;k++){
for(int h=0;h<weightHK[0].length;h++){
bw.append(Double.toString(weightHK[k][h])+" ");
}
bw.append("\r\n");
bw.flush();
}
bw.close();
return flag;
}
//调用训练好的网络
public boolean loadWeight(File file) throws IOException{
boolean flag = false;
BufferedReader br = new BufferedReader(new FileReader(file));
//写入weightIH
String line;
String[] strs;
for(int h=0;h<weightIH.length;h++){
line=br.readLine();
strs = line.split(" ");
for(int i=0;i<weightIH[0].length;i++){
weightIH[h][i] = Double.parseDouble(strs[i]);
}
}
//写入weightHK
for(int k=0;k<weightHK.length;k++){
line=br.readLine();
strs = line.split(" ");
for(int h=0;h<weightHK[0].length;h++){
weightHK[k][h] = Double.parseDouble(strs[h]);
}
}
br.close();
return flag;
}
//网络每个输出单元的输出
public double[] predict_all(double[] input){
goForward(input);
return output;
}
//输出预测数字
public int preidict_result(double[] input){
int result = -1;
double max = -1;
goForward(input);
for(int i=0;i<output.length;i++){
if(output[i]>max){
max = output[i];
result = 9-i;
}
}
return result;
}
private void setInput(double[] input) {
for(int i=0;i<this.input.length;i++){
this.input[i] = input[i];
}
}
public double[][] getWeightIH() {
return weightIH;
}
public double[][] getWeightHK() {
return weightHK;
}
}
这里需要说明的是主要的计算量为goForward函数,这个是正向计算的函数。如果看懂了前面的原理这个文件其实也没什么好讲的,无非是把输出细节化,训练方法和前面所说一样。同样增加了getError函数来获取误差,因为笔者把Error来作为训练终止的要求。但是其实使用这个作为终止条件摒弃了增量梯度下降算法中不需要一次性加载所有数据的优点。计算Error必须使用所有的数据。
这样一个网络的架构就已经搭建好了,使用时我们只需要调用NervousSystem1H类中的方法就可以了。
3.2 主程序包
下面就是要创建针对项目的主程序包com.zhangxiao.window了。
Window.java中主要应该包括如下方法:
- 获取训练数据
- 图片数据转化为数组
- 获取训练标签
构建神经网络
package com.zhangxiao.window; import java.awt.image.BufferedImage; import java.io.BufferedReader; import java.io.File; import java.io.FileReader; import java.io.IOException; import javax.imageio.ImageIO; import com.zhangxiao.element.NervousSystem1H; public class Window { public static void main(String[] args) throws IOException { String path = "这里填自己的路径"; //获取训练素材 double[] testData = new double[128];//这里记得获取测试数据!!!!!!!!!!!!!!!!!! double[][] target = getTarget(path, 10, 40); double[][] trainData = getTrainData(path, 40); int[] structure = new int[]{128,8,10}; //构建神经网络 NervousSystem1H s = new NervousSystem1H(0.01,structure,trainData,target); //训练神经网络 System.out.println("训练中..."); s.train(); System.out.println("训练完毕!"); //保存weight数据 s.saveWeight(new File("data/weight/weight.txt")); //载入保存的weight数据 /*System.out.println("载入中..."); s.loadWeight(new File("data/weight/weight.txt")); System.out.println("载入完成!");*/ double[] result = s.predict_all(testData); for(int i=0;i<result.length;i++){ System.out.print(result[i]+" "); } } //获取训练样本 public static double[][] getTrainData(String direction,int number) throws IOException{ double[][] trainData = new double[number][128]; for(int d=0;d<number/4;d++){ for(int i=0;i<4;i++){ trainData[4*d+i] = image2Array(direction+"/"+d+"/"+d+""+i+".bmp"); } } return trainData; } //将图片转化为数组 public static double[] image2Array(String str) throws IOException{ double[] data = new double[16*8]; BufferedImage image = ImageIO.read(new File(str)); for(int i = 0;i<8;i++){ for(int j = 0;j<16;j++){ int color = image.getRGB(4*i, 4*j); int b = color&0xff; int g = (color>>8)&0xff; int r = (color>>8)&0xff; data[8*j+i]=((int)(r*0.3+g*0.59+b*0.11))/255; } } return data; } //获取目标结果数组 @SuppressWarnings("resource") public static double[][] getTarget(String str,int length,int number) throws IOException{ BufferedReader br = new BufferedReader(new FileReader(str)); double[][] data = new double[number][length]; String line; String[] strs; int d = 0; while((line=br.readLine())!=null){ strs = line.split(" "); for(int i=0;i<length;i++){ data[d][i] = Double.parseDouble(strs[i]); } d++; } if(d!=number){ System.out.println("数据组数不匹配!"); return null; } br.close(); return data; } }
4.后记
到这里这个坑基本上算是填完了,当然笔者还是需要说明的是由于代码写的比较匆忙,很多冗余、不够优化以及结构问题比比皆是。希望大家能够谅解,如果有很好的建议方便留言。到目前为止这个系列笔者前前后后花费了很多的精力以及时间,终于完成了这个两万多字的系列,可以说从中也学到了很多东西,很多以前并不是很清楚的东西也理清楚了。另外这里给出大家一个优化的方向:
- 加入冲量项,避开局部最小值。
- 改变隐藏层的单元数。
如果觉得看完还是有些疑惑的建议自己再复建一下算法,或者你可以试试将隐藏层数变为2层,再来思考整个系统,相信你会受益匪浅!