版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/ww1473345713/article/details/83422462
词频分析–字典树的应用
字典树又称单词查找树,Trie树,前缀树,是一种树形结构,是一种哈希树的变种。
典型应用是用于统计,排序和保存大量的字符串所以经常被搜索引擎系统用于文本词频统计。
它的优点是:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比哈希树高。
下面我们来用python应用字典树实现词频分析
首先我们定义一个节点,
节点包括三部分内容,1是字符,2是该字符出现的频次,3是这个字符的子节点,因为英文字母一共26个(不区分大小写)
因此,每一个节点最多有26个子节点。
# 节点结构
class node:
def __init__(self):
self.value = 0
self.child = [0 for i in range(26)]
self.freq = 0
然后我们定义如下规则来构建一棵树
-
根节点不包含字符,除根节点外的每一个子节点都包含一个字符和该字符出现的频次,
-
从根节点到某一节点,路径上经过的字符连接起来,就是该节点对应的字符串。
-
每个单词的公共前缀作为一个字符节点保存。
比如对于hello这个单词,我们构建6个节点(一个根节点,五个子节点),从h->e->l->l->o,后一个节点依次是前一个节点的子节点,h节点是根节点的子节点。
根据这三条规则,假设我们有如下10个单词
a am am inn in i to tea ted ten
那么我们可以构建出入下图所示的字典树
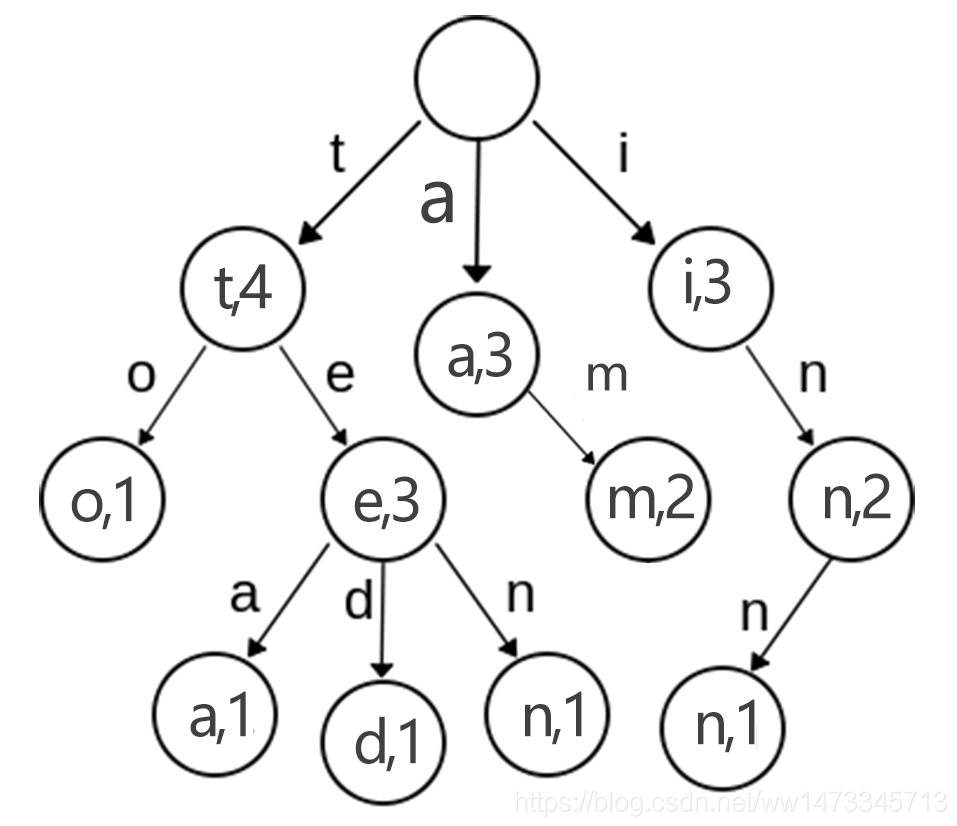
显然,各个单词出现的频次如下:
(a,1),(am,2),(inn,1),(in,1),(i,1),(to,1),(tea,1),(ted,1),(ten,1)
好了,现在看看代码是如何实现的
# 定义节点,value表示当前字符,child表示下一个节点,下一个节点有a-z 26种可能性,
# 因此建立一个26个元素的列表,freq表示出现的频次
class node:
def __init__(self):
self.value = 0
# self.child= []
self.child = [0 for i in range(26)]
self.freq = 0
# 定义字典树
class tree:
# 初始化树
def __init__(self):
self.root = node()
# 插入单词
def insert_word(self,word):
chars = list(word)
p = self.root
for v in chars:
v = v.lower()
if (p.child[ord(v) - ord('a')] == 0):
s = node()
s.value = v
s.freq = 1
p.child[ord(v) - ord('a')] = s
else:
# 插入节点时,每经过一个节点,该节点频次加1
p.child[ord(v) - ord('a')].freq += 1
p = p.child[ord(v) - ord('a')]
# 判断子节点是否为空
def is_child_null(self, node):
for i in range(26):
if node.child[i] != 0:
return False
return True
# 子节点频次之和
def child_freq_sum(self,node):
cnt = 0
for i in range(26):
if node.child[i] != 0:
cnt += node.child[i].freq
return cnt
# 查找某个单词出现的频次
def find_word(self,word):
p = self.root
cnt = 0
chars = list(word)
for v in chars:
v = v.lower()
if p.child[ord(v) - ord('a')] == 0 :
cnt = 0
return 0
else:
p = p.child[ord(v) - ord('a')]
# 查找时,每经过一个节点,将cnt置为该节点的频次
cnt = p.freq
# 查找完单词的最后一个字符,判断该节点是否为根节点,
# 如果不是根节点,需要cnt需要减去改节点的所有子节点频次之和
if not self.is_child_null(p):
cnt = cnt - self.child_freq_sum(p)
return cnt
来检查一下运行结果是否正确,新建一个文件1.txt,内容写入
a am am inn in
i to tea ted ten
执行下面这段代码
from TrieTree import node, tree
if __name__ == '__main__':
f = open('1.txt', 'r')
l = f.read()
l = l.split()
res = tree()
# res.init_tree()
for v in l:
res.insert_word(v)
l = set(l)
for v in l:
cnt = res.find_word(v)
print("%s:%d"%(v,cnt))
执行结果如图
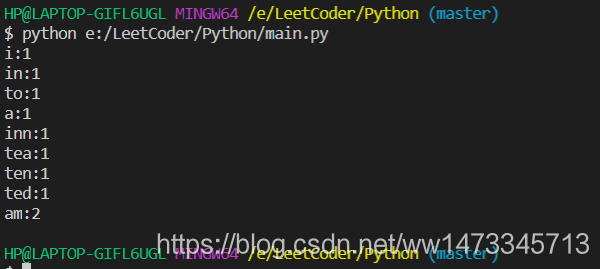
可见程序运行正确,拿其他的数据测试,一样可以得到正确的结果。
代码下载
https://github.com/zkangHUST/DataStructure/tree/master/TrieTree