版权声明:欢迎转载,转载请注明出处:土豆洋芋山药蛋 https://blog.csdn.net/qq_33414271/article/details/85490209
神经网络前向传播一般用于搭建整个神经网络的结构框架,形成整个网络的逻辑通路。反向传播用于更新每层之间的权重,减少损失,进而提升预测准确度。
下面是一个神经网络的结构图:
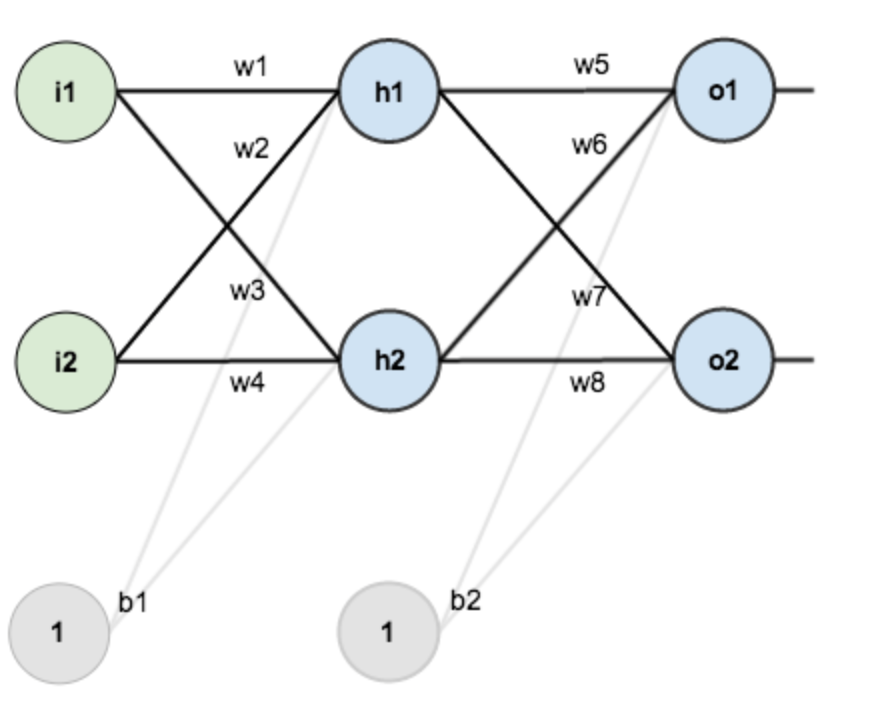
第一层是输入层,包含两个神经元i1,i2,和截距项b1;第二层是隐含层,包含两个神经元h1,h2和截距项b2,第三层是输出o1,o2,每条线上标的wi是层与层之间连接的权重,激活函数我们默认为sigmoid函数。
激活函数的作用:
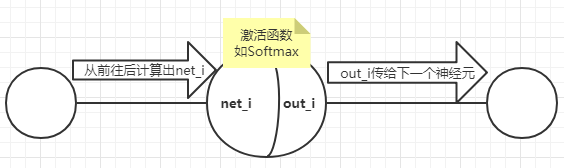
正如上图所示,每个神经元节点可以分为两部分,第一步是从前面计算而来的net_i,但这个net_i不能直接传送给后面。第二步就是利用激活函数计算出out_i,再根据权重传给后面。
初始化神经网络
附上权重以后如下图:
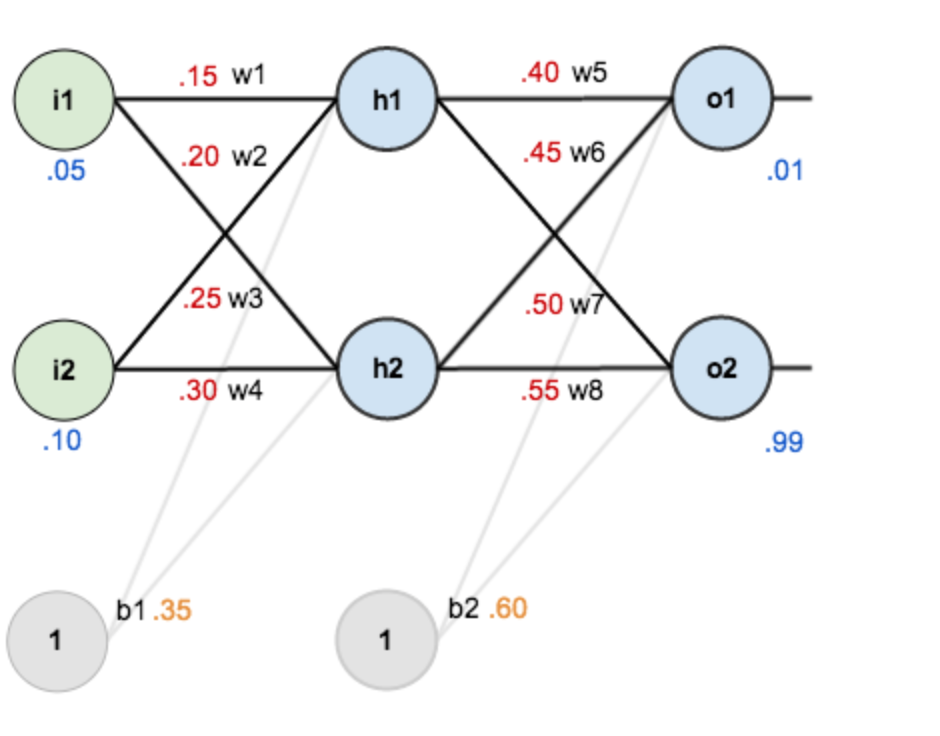
其中,
输入数据 i1=0.05,i2=0.10;
输出数据 o1=0.01,o2=0.99;
初始权重
w1=0.15,w2=0.20,w3=0.25,w4=0.30;
w5=0.40,w6=0.45,w7=0.50,w8=0.55;
目标:给出输入数据i1,i2(0.05和0.10),使输出尽可能与原始输出o1,o2(0.01和0.99)接近。
Step1: 前向传播
1. 输入层
→ 隐含层
计算神经元h1的输入加权和(net_h1):
逻辑表达式为:
h=i∗w+b
矩阵表示形式为:
[i1i2][w1w2w3w4]+b1=[neth1neth2]
如:
neth1=w1∗i1+w2∗i2+b1=0.15∗0.05+0.2∗0.1+0.35=0.3775
再利用Softmax激活函数计算得到
outh1传递给下一层:
outh1=1+e−neth11=1+e−0.37751=0.593269992
同理我们可以计算出:
outh2=0.596884378
2. 隐含层
→ 输出层
逻辑表达式为:
o=h∗w+b
矩阵表示形式为:
[outh1outh2][w5w6w7w8]+b2=[neto1neto2]
如:
neto1=w5∗outh1+w6∗outh2+b2=0.45∗0.596884378+0.6∗1=1.105905967
再利用Softmax激活函数计算得到
outo1传递给下一层:
outo1=1+e−neto11=1+e−1.1059059671=0.75136507
同理我们可以计算出:
outo2=0.772928465
我们得到输出值为[0.75136079 , 0.772928465],与实际值[0.01 , 0.99]相差还很远,现在我们对误差进行反向传播,更新权值,重新计算输出。
Step 2 :反向传播
1.计算总误差
总误差——使用均方误差(square error):
Etotal=n∑(target−output)2
target表示目标值,即正确的应该是多少。
所以:
Eo1=2(targeto1−outo1)2=0.274811083
Eo2=2(targeto2−outo2)2=0.298371109
Etotal=Eo1+Eo2=0.298371109
2.隐含层
→输出层的权值更新:
大体思路:
1.利用偏导数大小量化每个参数对结果的影响(后一个对传向前一个的权重w的偏导)。
2.更新:
w+=w−η∗偏导数。
计算偏导数要用到链式求导法则。
比如我们要更新w5:
1.计算偏导数
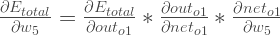
也就是下图所演示的过程:
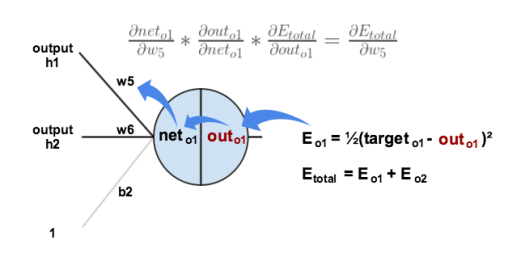
∂outo1∂total公式表示为:
Etotal=2(targeto1−outo1)2+2(targeto2−outo2)2∂outo1∂total=−(targeto1−outo1)=−(0.01−0.75136507)=0.74136507
.
∂neto1∂outo1公式表示为:
outo1=1+e−neto11∂neto1∂outo1=outo1(1−outo1)=0.75136507(1−0.75136507)=0.186815602
.
∂w5∂neto1公式表示为:
neto1=w5∗outh1+w6∗outh2+b2∂w5∂neto1=outh1=0.593269992
所以算出偏导数为:
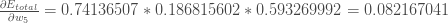
2.更新
w为
w+
w+=w−η∗∂w5∂total=0.4−0.5∗0.082167041=0.35891648。
同理:
w6+=0.408666186;w7+=0.511301270;w8+=0.561370121
3.隐含层
→隐含层的权值更新:
方法其实与上面说的差不多,但是有个地方需要变一下,在上文计算总误差对w5的偏导时,是从out(o1)---->net(o1)---->w5,但是在隐含层之间的权值更新时,是out(h1)---->net(h1)---->w1,而out(h1)会接受E(o1)和E(o2)两个地方传来的误差,所以这个地方两个都要计算。
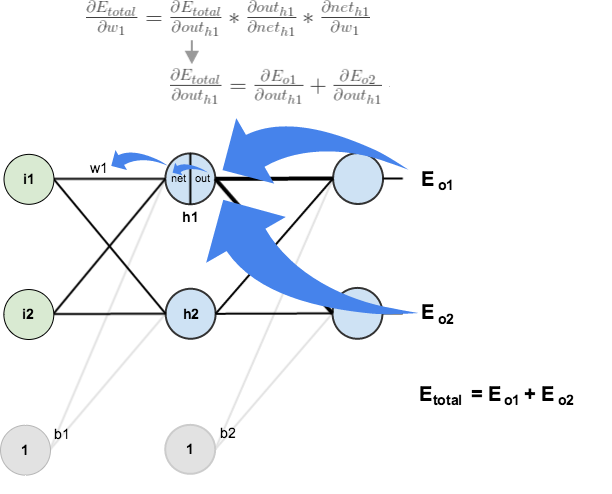
直接放计算结果:
最后更新
w1:

同理:

这样误差反向传播法就完成了,最后我们再把更新的权值重新计算,不停地迭代,在这个例子中第一次迭代之后,总误差E(total)由0.298371109下降至0.291027924。迭代10000次后,总误差为0.000035085,输出为[0.015912196,0.984065734] (原输入为[0.01,0.99]),证明效果还是不错的。
所以反向传播最主要的是要清楚求偏导的那个递推公式:
注意1:从哪开始推?
从最终得到的误差开始,如果输出有多个,应叠加。
注意2:推到哪结束?
利用w计算出了什么(下个节点的net值),就推到
neti对w求偏导为止。
都看到这里了,不如投我一票呗~
本人正在才加2018 CSDN博客之星的评选,NO.77 “土豆洋芋山药蛋”,请投我一票,谢谢大家宝贵的一票~

参考文献:
原始英文出处:https://mattmazur.com/2015/03/17/a-step-by-step-backpropagation-example/
Charlotte77的关于上一篇文章的翻译:https://www.cnblogs.com/charlotte77/p/5629865.html