Backpropagation ~ 反向传播
一旦知道计算图,就可以用反向传播技术–递归调用链式法则来计算计算图中的每个变量的梯度~~
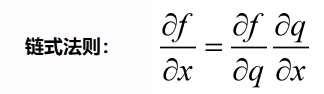
工作机制~
分为:
- 一维
- 高维
先讲一维
对任意一个点,有
根据这些结点展开到所有的结点
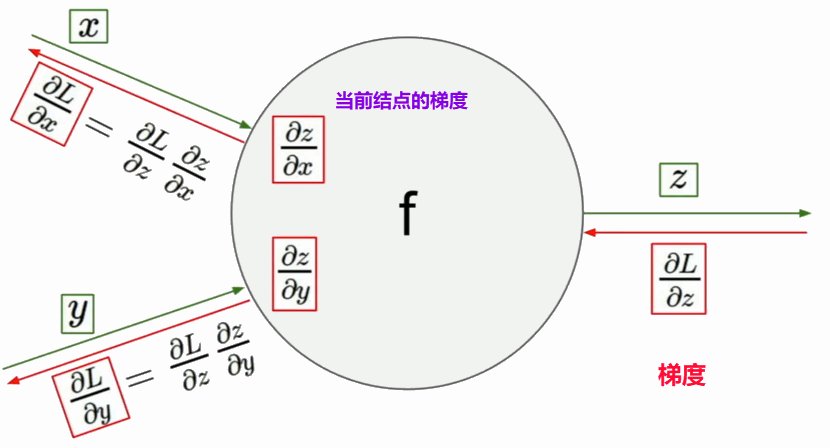
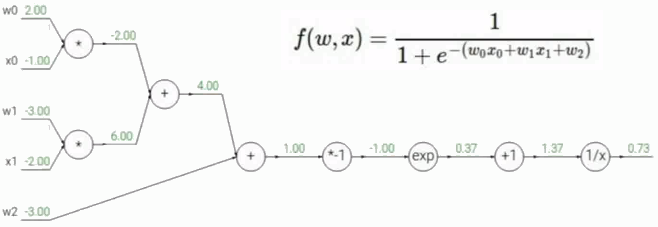
例题
先求解函数f()的值
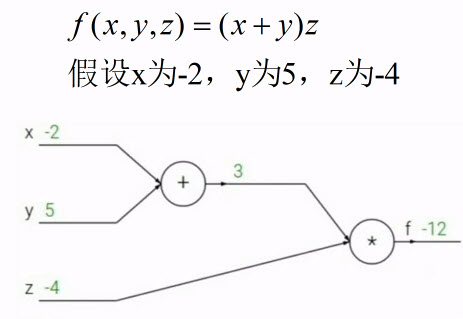
然后从后往前走计算所有的梯度:(反向传播)
虽然该方法正向直接由微积分就能求解出,但在实际问题中,函数非常的复杂,用微积分直接计算非常困难。而是使用该方法将复杂的表达式分解成一些计算节点,只需要一个非常简单的计算就能计算出梯度。
复杂~
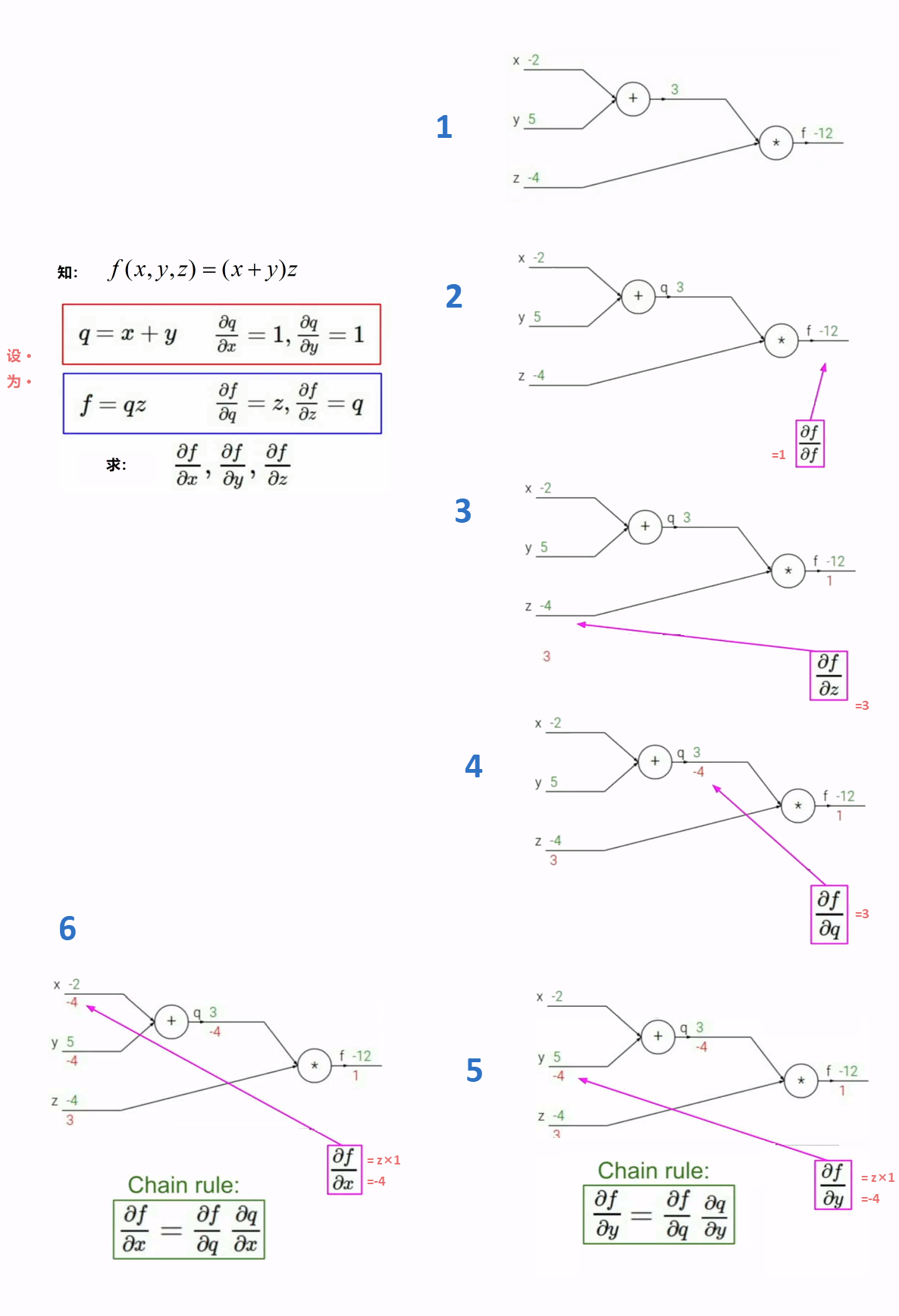
求解了的函数值f():
然后从后往前走计算所有的梯度:(反向传播)
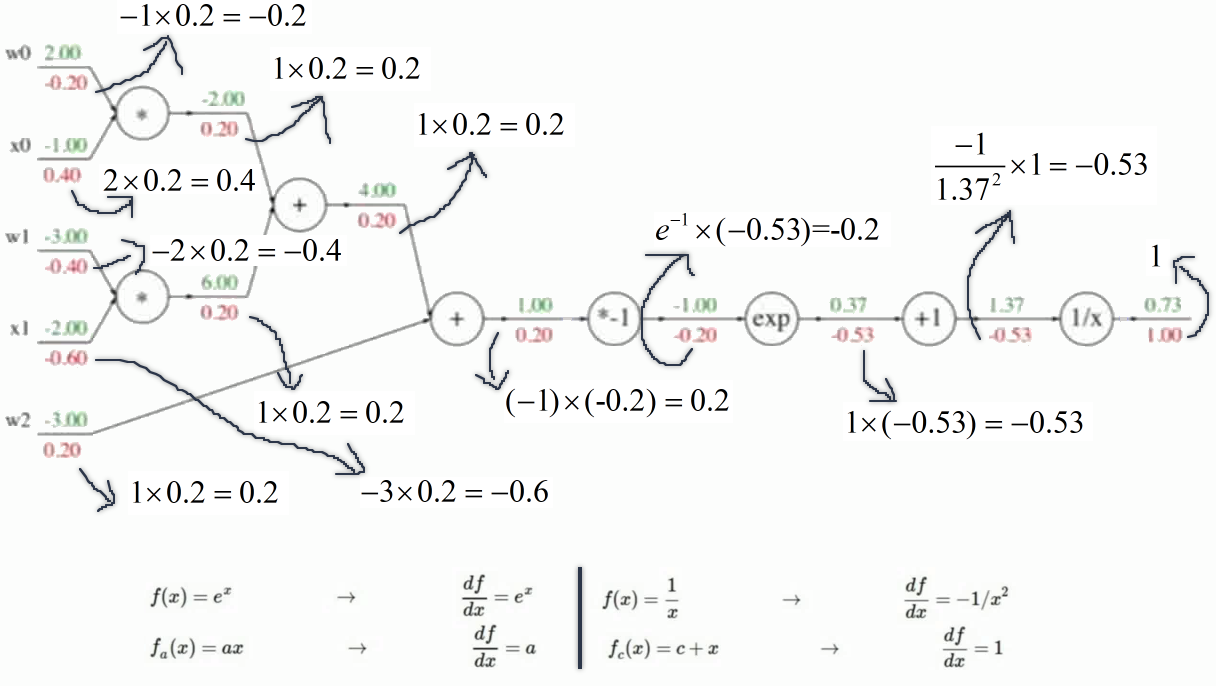
此时再用微积分显然太麻烦~~~
对于不同的门(节点):
- add gate:梯度传递器(分支都等于门上的梯度)
- max gate:梯度路由器(将门上的梯度全给大的,其他分支都为0)
- mul gate:梯度转换器(进行尺度的放缩–分支等于门上的乘以乘法器的乘的参数)
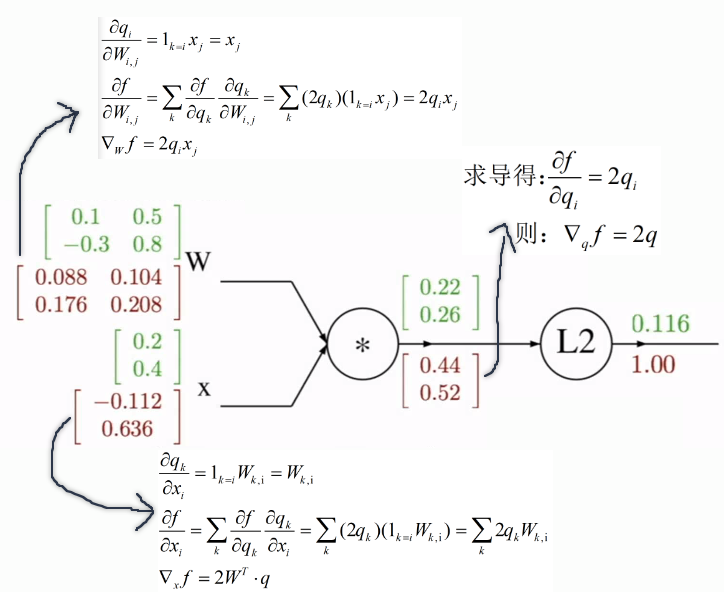
再叙高维
对任意一个点,实际上是
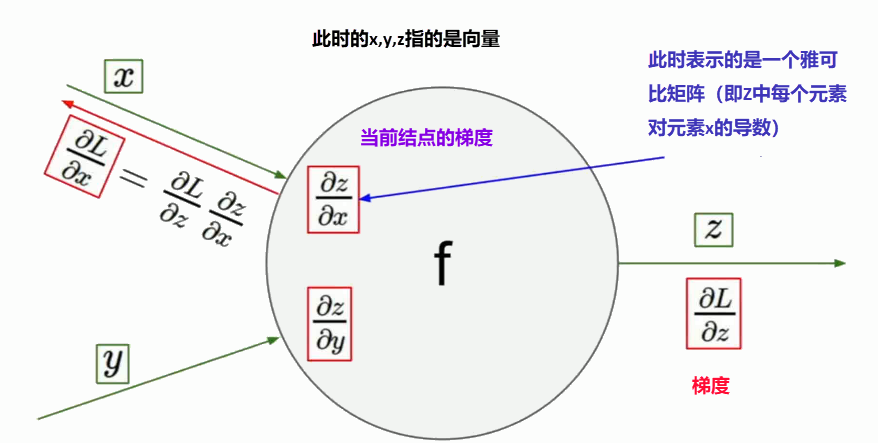
由矩阵输出矩阵~~
根据这些结点展开到所有的结点
例题
先求解函数f()的值
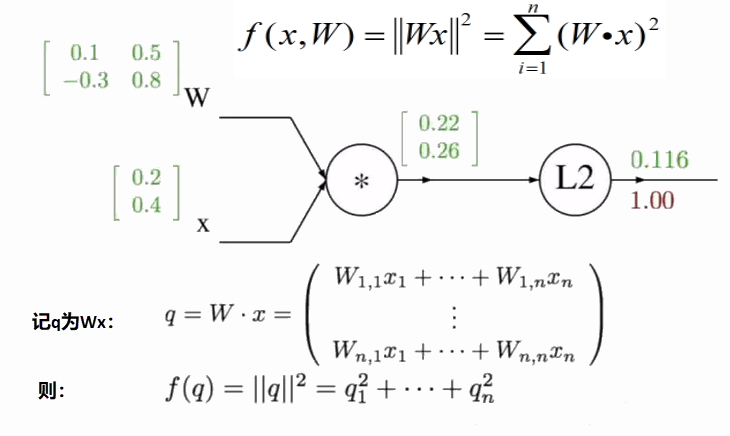
计算反向传播
优化思想
实际计算过程中,由于图像的矩阵之大,造成其雅可比矩阵非常大。对于求其雅可比矩阵非常困难。但实际上我们不用将雅可比矩阵计算出来~~对角矩阵
实现代码▼
# 在计算图中~
# 一个正向计算和反向计算的过程
# 针对gate实现的不同API~
class ComputationalGraph(object):
def forward(inputs):
# 依次传值给各输入门
# 依据拓扑排序实现优先性
# 使得计算图逐渐前进
for gate in self.graph.nodes_topologivally_sorted():
gate.forward()
return loss
def backward():
for gate in reversed(self.graph.nodes_topologically_sorted()):
gate.backward()
return inputs_gradients
示例某一种门的实现~
对于x,y,z都是标量时
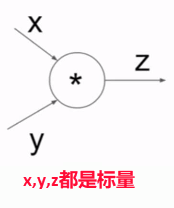
乘法门▼
# 乘法门
# 调用相应的API
class MultiplyGate(object):
def forward(x,y):
z=x*y
self.x=x # 对x值进行缓存,以为计算反向传播中调用多次
self.y=y # 对y值进行缓存,以为计算反向传播中调用多次
return z
def backward(dz): #dz表示函数f对z的偏导
dx = self.y * dz # [dL/dz * dz/dx]
dy = self.x * dz # [dL/dz * dz/dy]
return [dx, dy]