吴恩达机器学习笔记及作业代码实现中文版
第十章 支持向量机
优化目标
- 在监督学习中,许多学习算法的性能都非常类似,因此,重要的不是你该选择使用学习算法 A 还是学习算法 B,而更重要的是,所创建的大量数据在应用这些算法时,表现情况通常依赖于你的水平。比如你为学习算法所设计的特征量的选择,以及如何选择正则化参数,诸如此类。
- 支持向量机(Support VectorMachine),简称 SVM,与逻辑回归和神经网络相比,在学习复杂的非线性方程时提供了一种更为清晰,更加强大的方式。
- 从逻辑回归开始展示如何一点一点修改来得到本质上的支持向量机:
- 在逻辑回归中我们已经熟悉了下图的假设函数形式和右边的 S 型激励函数。

- 如果有一个 的样本,不管是在训练集中或是在测试集中,又或者在交叉验证集中,总之是 ,现在我们希望 趋近 1。因为我们想要正确地将此样本分类,这就意味着当 趋近于 1 时, 应当远大于 0,这里的>>意思是远远大于 0。
- 相反地,如果我们有另一个样本,即
。我们希望假设函数的输出值将趋近于 0,这对应于
,或者就是
会远小于 0,因为对应的假设函数的输出值趋近 0。
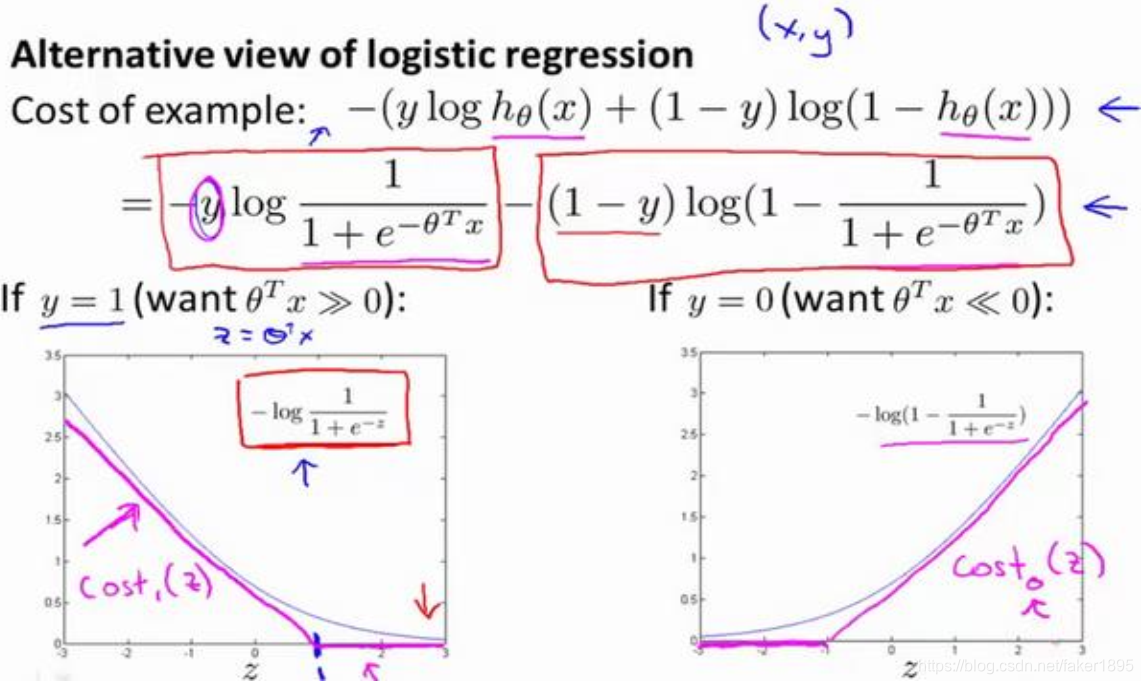
- 现在,一起来考虑两种情况:一种是y等于 1 的情况;另一种是y等于 0 的情况。
- 在第一种情况中,假设 ,此时在目标函数中只需有第一项起作用,因为 时, 项将等于 0。因此,当在 的样本中时,即在 (x, y)中 ,我们得到 这一项。
- 如果画出关于 的函数,我们同样可以看到,当 增大时,也就是相当于 增大时, 对应的值会变的非常小。对整个代价函数而言,影响也非常小。这也就解释了,为什么逻辑回归在观察到正样本 时,试图将 设置得非常大。因为,在代价函数中的这一项会变的非常小。
- 现在开始建立支持向量机,我们会从这个代价函数开始,也就是
一点一点修改,取这里的
点,先画出将要用的代价函数:
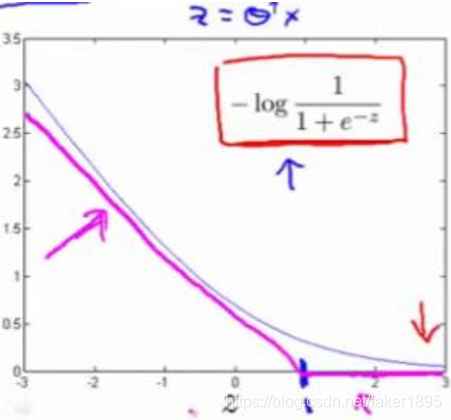
- 新的代价函数是一条直线,也就是用紫红色画的曲线,这里已经非常接近逻辑回归中使用的代价函数了,不过这里是由两条线段组成,即位于右边的水平部分和位于左边的直线部分,左边直线部分的斜率并不重要。但是,这里我们将使用的新的代价函数,是在 的前提下的。
- 目前,我们只是讨论了
的情况,另外一种情况是当
时,此时代价函数只留下了
这一项。如果你将这一项作为
的函数,那么,这里就会得到横轴
。同样地,我们要替代这一条蓝色的线,用相似的方法:
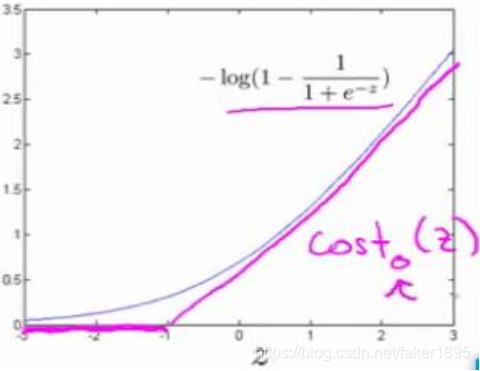
- 如果我们用一个新的代价函数来代替,即这条从 0 点开始的水平直线,然后是一条斜线,像上图。那么,现在给这两个方程命名为
和
。这里的下标是指在代价函数中,对应的
和
的情况,拥有了这些定义后,现在,我们就开始构建支持向量机:
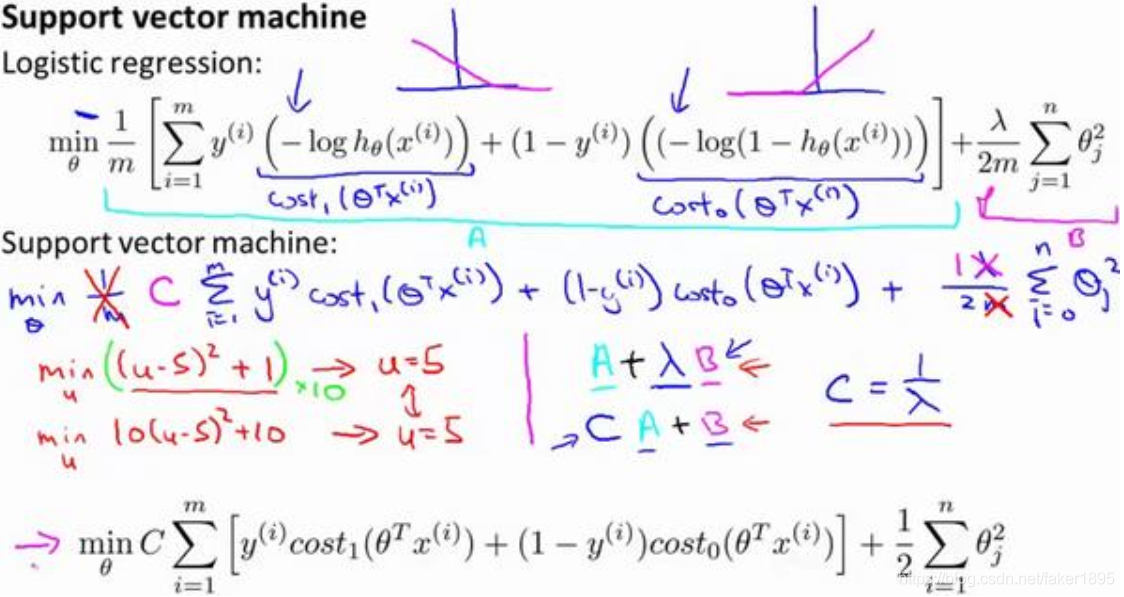
- 首先,我们要除去1/m这一项,当然,这仅仅是由于人们使用支持向量机时,对比于逻辑回归而言,不同的习惯所致,这也会得出同样的 最优值。
- 第二点概念上的变化,我们只是指在使用支持向量机时,一些如下的标准惯例,而不是逻辑回归。对于逻辑回归,在目标函数中,我们有两项:第一个是训练样本的代价,第二个是我们的正则化项。这就相当于我们想要最小化 加上正则化参数 ,然后乘以其他项 ,我们所做的是通过设置不同正则参数 达到优化目的,使得训练样本拟合的更好,即最小化 。
- 对于支持向量机,按照惯例,我们将使用一个不同的参数替换这里使用的 来权衡这两项,就是第一项和第二项我们依照惯例使用一个不同的参数称为 ,同时改为优化目标 。
- 在逻辑回归中,如果给定 一个非常大的值,意味着给予 更大的权重。而这里,就对应于将 设定为非常小的值,那么,相应的将会给 比给 更大的权重。
- 因此,这只是一种不同的方式来控制这种权衡或者一种不同的方法,即用参数来决定是更关心第一项的优化,还是更关心第二项的优化。
- 那么,我现在删掉这里的
,并且用常数
来代替。这就得到了在支持向量机中我们的整个优化目标函数。然后最小化这个目标函数,得到 SVM 学习到的参数
:
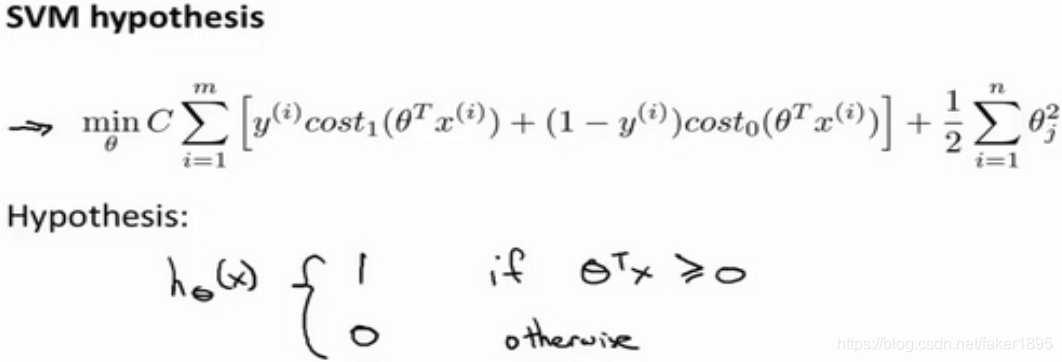
- 最后有别于逻辑回归输出的概率。在这里,我们的代价函数,当最小化代价函数,获得参数 时,支持向量机所做的是它来直接预测 的值等于1,还是等于0,当 大于或者等于 0 时,这个假设函数会预测1,其他情况为0。
- 这就是支持向量机数学上的定义。
- 在逻辑回归中我们已经熟悉了下图的假设函数形式和右边的 S 型激励函数。