框架图(Agent1的avro source写错误了,应该是exec source):
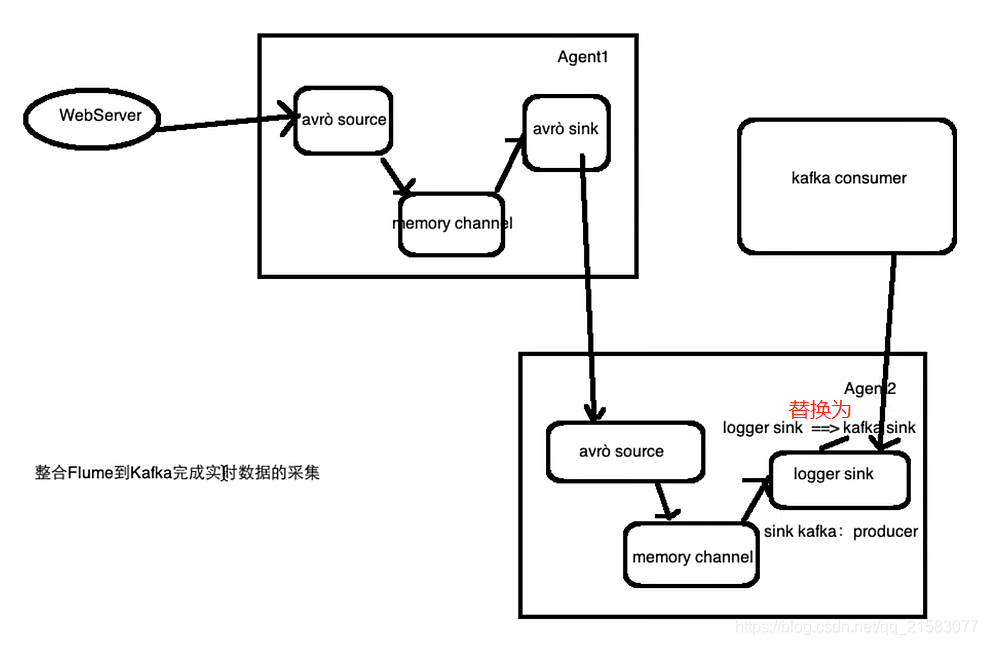
Flume配置文件:avro-memory-kafka.conf
avro-memory-kafka.sources = avro-source
avro-memory-kafka.sinks = kafka-sink
avro-memory-kafka.channels = memory-channel
avro-memory-kafka.sources.avro-source.type = avro
avro-memory-kafka.sources.avro-source.bind= hadoop1
avro-memory-kafka.sources.avro-source.port= 44444
avro-memory-kafka.sinks.kafka-sink.type = org.apache.flume.sink.kafka.KafkaSink
avro-memory-kafka.sinks.kafka-sink.brokerList = hadoop0:9092
avro-memory-kafka.sinks.kafka-sink.topic = shuaige
avro-memory-kafka.sinks.kafka-sink.batchSize = 5
avro-memory-kafka.sinks.kafka-sink.requiredAcks = 1
avro-memory-kafka.channels.memory-channel.type = memory
avro-memory-kafka.sources.avro-source.channels = memory-channel
avro-memory-kafka.sinks.kafka-sink.channel = memory-channel
运行B: flume-ng agent --name avro-memory-kafka --conf $FLUME_HOME/conf --conf-file $FLUME_HOME/conf/avro-memory-kafka.conf -Dflume.root.logger=INFO,console
运行A:flume-ng agent --name exec-memory-avro --conf $FLUME_HOME/conf --conf-file $FLUME_HOME/conf/exec-memory-avro.conf -Dflume.root.logger=INFO,console(和此博客需求三中机器A的配置相同)
问题:卡在这不动了(耗费了2天时间解决这个问题!)
2019-02-12 16:15:05,869 (conf-file-poller-0) [WARN - org.apache.flume.node.AbstractConfigurationProvider.getConfiguration(AbstractConfigurationProvider.java:133)] No configuration found for this host:agent
2019-02-12 16:15:05,881 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:138)] Starting new configuration:{ sourceRunners:{} sinkRunners:{} channels:{} }
经检查发现是我agent的名字写错了。
首先运行B avro-memory-kafka,然后运行A exec-memory-avro ,再打开一个客户端C消费Kafka中的数据, ./kafka-console-consumer.sh --zookeeper localhost:2181 --topic shuaige
验证:在机器A中,/soft/flume1.6/data/data.log 中使用echo命令增加数据,观察客户端C是否会接收并在控制台打印出追加的数据。