“ 你所有流过的泪,是一条渡你的河, 你所有受过的苦,将照亮你前方的路;岁月从没有放过我们,我们也不能辜负岁月。”
最近过的不好~
被虐
自信全无
各种害怕、自卑~
唯有努力前行,安慰自己
记录下两种算法BFS和DFS的学习之路:
BFS和DFS,这两个是比较重要的概念,是很多很多算法的基础,另外设计到数学当中的树和图,已帮你百度:

所谓的图就是许多的点和许多的边把这些点连了起来,具体每个点放在那里没啥关系,重点是他们之间的连接关系。一个图长得就像是下面这样:
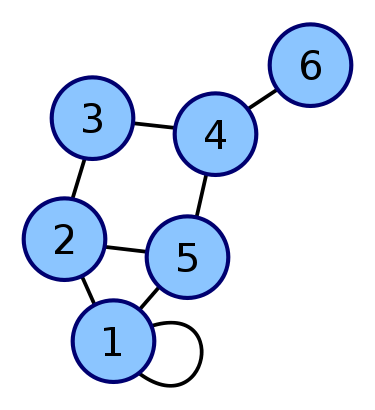
这个图有6个点,8条边,其中有一条是自己连接自己的。另外图的话有:有向图,无向图等等,还有很多很多分类,比如二分图等等,上图只是一种。
恩,其实,树也是图,只是比较特殊而已,它有N个点,N-1条边,而且这N个点是互相连通的,那么这个图就能画成一颗树一样的样子。
接下来
进入正题~
BFS:Breadth-First-Search,宽度(广度)优先搜索;DFS:Depth-first search,深度优先搜索。
二者都是对图或树的一种搜索或遍历方法,只不过搜索的形式不一样。对于一个图来说,搜索就是从某个点开始,不停的搜索与他相连的所有的点,然后以此接连下去,直到所有的点都被搜索到了。
为了区分BFS和DFS的遍历方式,我们拿上面的图来举例:
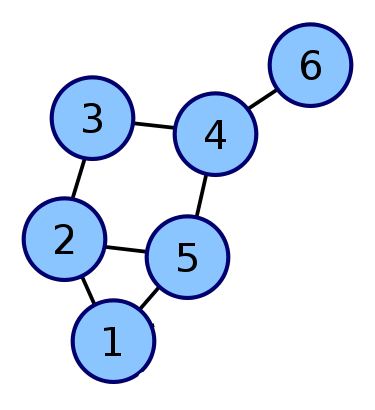
比如上图,如果从1开始进行搜索的话,BFS的步骤就是,先搜索所有和1相连的,也就是2和5被找到了,然后再从2开始搜索和他相连的,也就是3被找到了,然后从5搜,也就是4被找到了,然后从3开始搜索,4被找到了,但是4之前已经被5找到了,所以忽略掉就行。然后3开始搜索,忽略4所以啥都没搜到,然后从4开始,6被找到了。。。
这样,这就是BFS。。。
而DFS的步骤是:从1开始,先找到其中一个相连的,2被找到了,然后直接开始从2开始搜索,3被找到了,然后从3开始搜索,4被找到了,然后从4开始搜索,5被找到了,然后从5开始搜索,忽略已经找到的所以啥都没找到。然后没路可走了,回到前面去再走另一条路,从4开始,6被找到了,然后又没路可走了,然后再回去前面4,然后没路了 ,回去前面3,然后一直这样。。。
DFS 就是像走迷宫一样一条路走到头直到走不通才回到前一个换一条路。。。就是这样。。。
总的来说:DFS和BFS主要是运用于对于图和树的搜索,但是绝大部分问题模型都是可以建模变成一个图或者树的,所以差不多不少问题都会涉及到这两个。
那具体怎么用代码实现这两种方式呢?
图的表示:
对于图上的每个点来说就是标号1,2,3....N就好,表示有N个结点,一般题目也已经标好号了,然后边的话一般会就是 u,v 这样表示有一条边连接u点和v点。
存储一个图的边有三种方法:(存图就是对于每个点u,记录它能到的所有点就行了...)
1.邻接矩阵:
直接开一个N×N的二维数组E,然后 E[i][j] 为1的时候表示 i 和 j 之间有一条边,0的时候就没有。
这样很方便简单,但是有几个缺陷,首先是效率问题,超过1000个点一般不管是空间还是时间都不允许了。然后就是如果从 3 到 5 有两条边的话,就没法表示了。。。
所以一般很少用了现在,当然有些算法还是会用到的。
int E[110][110];
E[1][2]=1;
E[5][3]=0;
2.邻接链表:
使用链表的方式保存一个结点的所有边,就是每个点都有一个链表。当然写个链表很麻烦,所以一般是用vector来替代。就像是下面这样。
vector <int> E[110];
E[3].push_back(6) // 有一条从3到6的边。
3.前向星:
这个名字实在逼格太高,而且很好用效率也高,所以我一直都用这种方式来存图。他和链表几乎没什么区别,就是每次添加新的边的时候往开头加,而不是往最后加。具体就像是下面这样:
struct Edge
{
int to,next;
};
Edge E[1010]; // 总共不超过1000条边。
int head[110],Ecou; // 不超过100个点。
void init() // 初始化。
{
memset(head,-1,sizeof(head));
Ecou=0;
}
void addEdge(int u,int v) // 增加边 u,v。
{
E[Ecou].to=v;
E[Ecou].next=head[u];
head[u]=Ecou++;
}好的~
可来说一说BFS、DFS怎么写?
BFS的写法:
注:BFS需要一个队列这种数据结构来保存,在每次找到和u相连的之后要一个个找这些点,符合先进先出。代码如下:(采用第二种存图方式。)
bool vis[110]; // 记录已经走过的点,防止重复访问。
void BFS(int root,int N) // N个点的图,从root点开始搜索。
{
queue <int> que;
memset(vis,0,sizeof(vis)); // 初始化。
vis[root]=1;
que.push(root);
int u,len;
while(!que.empty())
{
u=que.front();
que.pop();
len=E[u].size();
for(int i=0;i<len;++i) // 找到和u相连的所有点,存在一个vector里面。
if(vis[E[u][i]]==0)
{
vis[E[u][i]]=1;
que.push(E[u][i]);
}
}
}DFS的写法:
注:DFS需要一个栈(stack),因为每次都是搜到之后不停的往下搜,符合先进先出。但是一般来说不用栈,而是直接通过函数的递归就行了。
bool vis[110];
int N;
void DFS(int u)
{
int len;
vis[u]=1;
len=E[u].size();
for(int i=0;i<len;++i)
if(vis[E[u][i]]==0)
DFS(E[u][i]);
}差不多就是这样,建议好好模拟使用一下~
另:
这两个算法在一定程度上其实是可以相互转化的,但是有些需要各自的特性的话就不行了。
DFS主要的特性是深度优先,总是不停的往下找,走到没路才罢休。
BFS则是从root开始扩展,每一层都是精密的搜索完整了才下一个。
sweet~
bye
无论怎样,一定要加油!相信自己,没有那么差,如果你自己都看不起自己,那也别指望别人能看得起你~