版权声明:本文为博主原创学习笔记,如需转载请注明来源。 https://blog.csdn.net/SHU15121856/article/details/84203508
学习《scikit-learn机器学习》时的一些实践。
SVM预测digits数据集
sklearn里的各种模型对象统一了接口,fit()做训练,predit()做预测,用score()获得对模型测试结果的打分。
这里的打分不是acc,应该是决定系数。
查看数据形式
from sklearn import datasets
from matplotlib import pyplot as plt
# 手写数字数据集
digits = datasets.load_digits() # <class 'sklearn.utils.Bunch'>
# 将数据集中的手写数字图像和标签打包成元组,这里得到[(图像,标签),...]
images_and_labels = list(zip(digits.images, digits.target))
plt.figure(figsize=(8, 6), dpi=200)
# 遍历(image=图像,label=标签),i=遍历序号.只遍历前8个
for i, (image, label) in enumerate(images_and_labels[:8]):
# 在子图上绘制出来看一下
plt.subplot(2, 4, i + 1) # 激活对应位置的子图
plt.axis('off') # 不显示坐标
plt.imshow(image, cmap='gray_r', interpolation='nearest') # interpolation='nearest'设置最近邻插值
plt.title("Digit:%i" % label, fontsize=20)
plt.show()
print("原始图像的shape:{0}".format(digits.images.shape)) # (1797, 8, 8)
print("对应的数据的shape:{0}".format(digits.data.shape)) # (1797, 64)
运行结果:

训练和测试
from sklearn.model_selection import train_test_split
from sklearn import datasets
from sklearn import svm
from matplotlib import pyplot as plt
from sklearn.externals import joblib
digits = datasets.load_digits()
# train_test_split函数用于将矩阵随机划分为训练子集和测试子集,并返回划分好的训练/测试样本,训练/测试标签
# test_size=:0~1之间的浮点数:测试样本占比;整数:测试样本的数量.random_state:随机数的种子
Xtrain, Xtest, Ytrain, Ytest = train_test_split(digits.data, digits.target, test_size=0.20, random_state=2)
print(Xtrain.shape, Xtest.shape, Ytrain.shape, Ytest.shape) # (1437, 64) (360, 64) (1437,) (360,)
# 使用C-SVM训练模型,C是对离群点的惩罚因子,gamma是核的系数,默认用RBF核
clf = svm.SVC(C=100.0, gamma=0.001)
clf.fit(Xtrain, Ytrain)
# 在测试集上做测试,返回决定系数R2=1-(SSE/SST),其中SSE是残差平方和,SST是总平方和
r2 = clf.score(Xtest, Ytest)
print(r2) # 0.9777777777777777
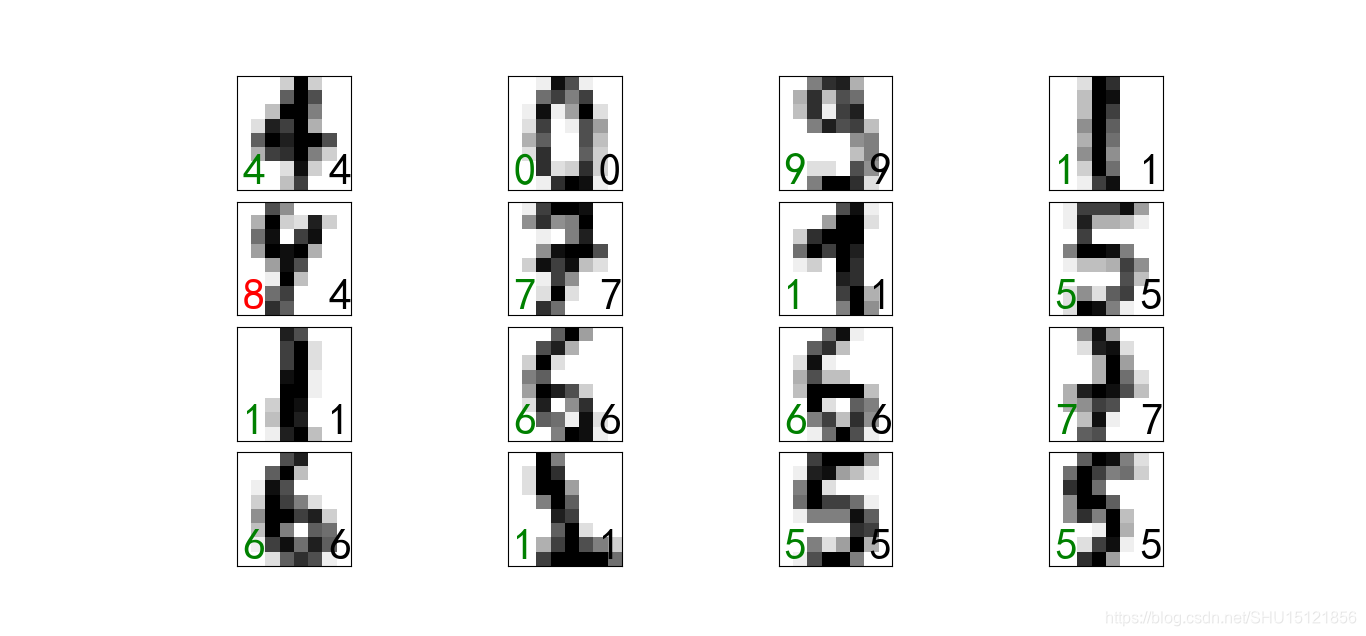
# 获取在测试集上预测的具体结果:使用clf.predict(测试样本)即可
Ypred = clf.predict(Xtest)
# 创建子图图形.接下来绘制前16个测试样本的测试结果
fig, axes = plt.subplots(4, 4, figsize=(8, 8))
# 调整子图外围的边距
fig.subplots_adjust(hspace=0.1, wspace=0.1)
# numpy.flat返回数组摊平为一维的结果,用这种方式方便地遍历axes中的每个ax
for i, ax in enumerate(axes.flat):
# 训练和测试的数据都是摊平后的,这里要调整成8*8的图像再输入
ax.imshow(Xtest[i].reshape(8, 8), cmap='gray_r', interpolation='nearest')
# 这里transform=ax.transAxes使前面的位置坐标参数是相对于左下角坐标轴原点,而不是默认的右上角
ax.text(0.05, 0.05, str(Ypred[i]), fontsize=32, transform=ax.transAxes,
color='green' if Ypred[i] == Ytest[i] else 'red') # 左下角:预测值
ax.text(0.8, 0.05, str(Ytest[i]), fontsize=32, transform=ax.transAxes, color='black') # 右下角:真实值
ax.set_xticks(()) # 不显示刻度
ax.set_yticks(())
plt.show()
# 保存训练好的模型
joblib.dump(clf, "../../data/z2/digits_svm.pkl")
# 读取保存下来的训练好的模型
# clf = joblib.load("../../data/z2/digits_svm.pkl")
# print(clf.score(Xtest, Ytest))
运行结果:
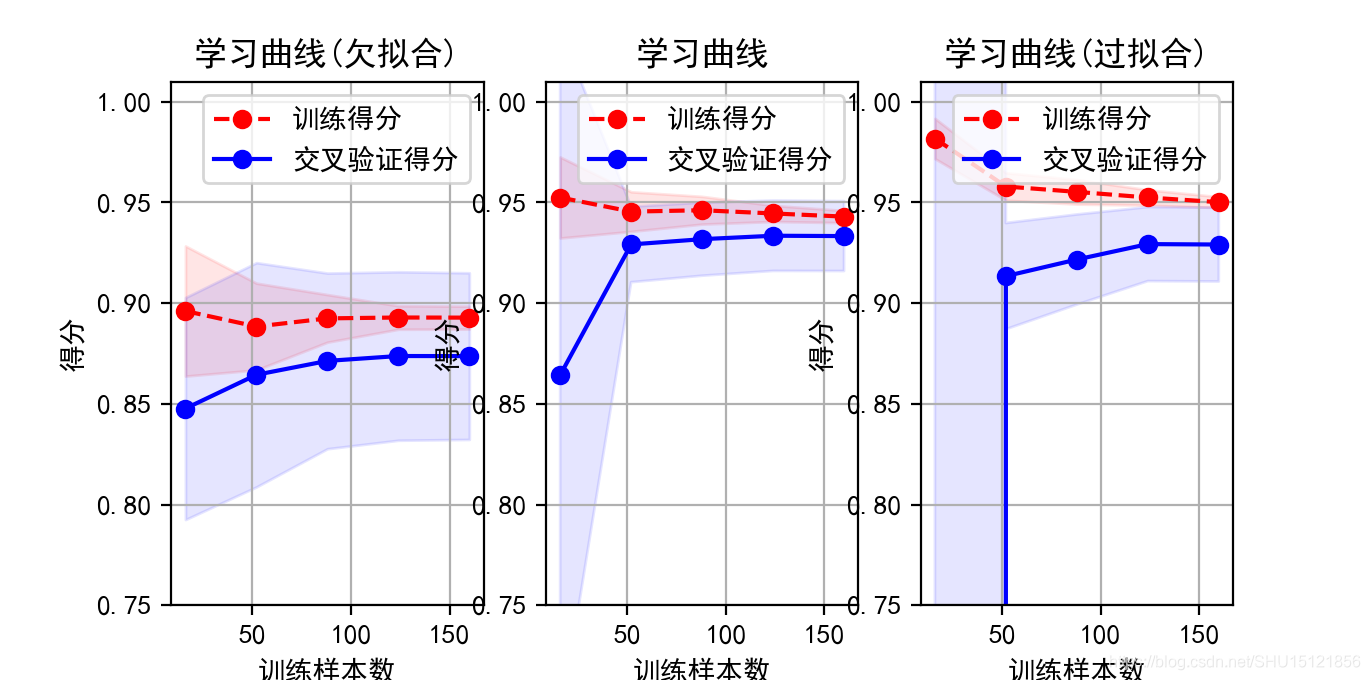
绘制随机波动样本的学习曲线
绘制学习曲线能直观的看出模型的拟合情况。这里涉及transformer、estimator和pipeline的概念,书上都没讲,后面专门研究一下这个。
这里的学习曲线就是展示随着训练样本增多,模型得分score的变化。另外,在三种次数的多项式下,拟合的程度会不同,能在图上明显看到过拟合和欠拟合的问题。
import numpy as np
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import learning_curve
from sklearn.model_selection import ShuffleSplit
from matplotlib import pyplot as plt
# 生成200个样本点
n_dots = 200
X = np.linspace(0, 1, n_dots)
# y=sqrt(X)上下浮动0.1
y = np.sqrt(X) + 0.2 * np.random.rand(n_dots) - 0.1
# sklearn里用的矩阵shape是(样本数,特征数)和(样本数,一维预测值)
# 这里正是200个1特征的样本,故转化为200x1的矩阵
X = X.reshape(-1, 1) # shape:(200, 1)
y = y.reshape(-1, 1) # shape:(200, 1)
# 多项式模型,传入多项式的次数
def polynomial_model(degree=1):
# <class 'sklearn.preprocessing.data.PolynomialFeatures'>
# 该类用于产生多项式的特征集
polynomial_features = PolynomialFeatures(degree=degree, include_bias=False)
# <class 'sklearn.linear_model.base.LinearRegression'>
# 该类用于创建线性回归的评估模型对象
linear_regression = LinearRegression()
# <class 'sklearn.pipeline.Pipeline'>
# 装入流水线.每个元组第一个值为变量名,元组第二个元素是sklearn中的transformer或estimator
# transformer即必须包含fit()和transform()方法,或者 fit_transform()
# estimator即必须包含fit()方法
# Pipeline.fit()可以对训练集进行训练,Pipeline.score()进行评分
pipeline = Pipeline([("Polynomial_features", polynomial_features), ("linear_regression", linear_regression)])
return pipeline
# 绘制模型的学习曲线
def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None, n_jobs=1, train_sizes=np.linspace(0.1, 1.0, 5)):
plt.title(title)
# 设置y轴的刻度范围,这里用了序列解包
if ylim is not None:
plt.ylim(*ylim)
plt.xlabel("训练样本数")
plt.ylabel("得分")
# (5, 10) (5, 10)
# 参数:
# estimator=实现"拟合"和"测试"的模型,这里将Pipeline传入,X=数据集,y=样本,n_jobs=并行运行的作业数(-1表示使用全部核)
# train_sizes=比例点数组,用于生成学习曲线的训练示例的相对或绝对数量(相对数量就是每百分之多少训练一次)
# 返回值:
# train_sizes_abs=每次用于生成学习曲线上的点的样本的数目.这里其shape=(5,),值=数组[16 52 88 124 160]
# train_scores=在比例点拿样本训练,训练集的的得分.这里其shape=(5, 10),其列数=cv里的n_splits(划分次数)
# test_scores=在比例点拿样本训练,测试集的的得分.这里其shape=(5, 10),其列数=cv里的n_splits(划分次数)
train_sizes_abs, train_scores, test_scores = learning_curve(estimator, X, y, cv=cv, n_jobs=n_jobs,
train_sizes=train_sizes)
# 做列的聚合,得到n_splits次训练-测试的方差和平均得分
train_scores_mean = np.mean(train_scores, axis=1) # shape=(5,),下同
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
plt.grid(True) # 显示背景的网格线
# plt.fill_between(x, y1, y2=0, where=None, interpolate=False, step=None, *, data=None, **kwargs)
# 在两条水平曲线y1=f(x)和y2=g(x)之间填充颜色,这里是把模型训练和测试score的均值的上下方差的范围里填充半透明的红色和蓝色
plt.fill_between(train_sizes_abs, train_scores_mean - train_scores_std, train_scores_mean + train_scores_std,
alpha=0.1,
color="r")
plt.fill_between(train_sizes_abs, test_scores_mean - test_scores_std, test_scores_mean + test_scores_std, alpha=0.1,
color='b')
# 绘制score的均值点构成的曲线
plt.plot(train_sizes_abs, train_scores_mean, 'o--', color='r', label="训练得分")
plt.plot(train_sizes_abs, test_scores_mean, 'o-', color='b', label="交叉验证得分")
plt.legend(loc="best") # 自动选择最合适的位置设置图例
# return plt
# <class 'sklearn.model_selection._split.ShuffleSplit'>
# 该对象用于将样本集合随机打乱后划分为训练集/测试集
# n_splits=划分次数,test_size=测试集占比,train_size=训练集占比(默认None即取余下全部)
cv = ShuffleSplit(n_splits=10, test_size=0.2, random_state=0)
# 后面绘图用的三个子图的图例
titles = ["学习曲线(欠拟合)", "学习曲线", "学习曲线(过拟合)"]
# 三个多项式拟合模型的次数
degrees = [1, 3, 10]
plt.figure(figsize=(18, 4), dpi=200)
# 在子图上分别画出三个次数的多项式的学习曲线
for i in range(len(degrees)):
plt.subplot(1, 3, i + 1)
plot_learning_curve(polynomial_model(degrees[i]), titles[i], X, y, ylim=(0.75, 1.01), cv=cv)
plt.show()
运行结果:
偏差:预测结果和真实值之间的差异;方差:多个模型输出结果之间的离散程度差异。
上图中欠拟合的特点就是score都比较低,随着训练样本数增加score有所增加(但是这里的欠拟合不是因为训练样本不够的问题,是选取的这个1次多项式的复杂度太低,所以很难有太大提升)。
上图中过拟合的特点是训练集和验证集的学习曲线相隔比较远(因为在训练集上学习到的东西不适合新的样本),而且随着训练样本数目增加验证集的score能有所提升,即更多的数据能改善过拟合问题。