学习《scikit-learn机器学习》时的一些实践。
原理见PCA及绘制降维与恢复示意图。
sklearn的PCA
sklearn中包装的PCA也是不带有归一化和缩放等预处理操作的,可以用MinMaxScaler()实现并装在Pipeline里封装起来。
from sklearn.decomposition import PCA
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import MinMaxScaler
import numpy as np
def init():
global A
# 原始矩阵
A = np.array([
[3, 2000],
[2, 3000],
[4, 5000],
[5, 8000],
[1, 2000]
])
# 这里修改其中元素的类型为float64,否则将给MinMaxScaler()内部做转换会引起警告
# By default(copy=True), astype always returns a newly allocated array.
A = A.astype(np.float64, copy=False)
# 预处理->PCA管道
def std_PCA(**kwargs):
scalar = MinMaxScaler() # 用于数据预处理(归一化和缩放)
pca = PCA(**kwargs) # PCA本身不包含预处理
pipline = Pipeline([('scalar', scalar), ('pca', pca)])
return pipline
if __name__ == '__main__':
init()
# 使用(这里n_components指定降维后的维数k)
pca = std_PCA(n_components=1)
Z = pca.fit_transform(A)
print(Z)
# 数据还原
A_approx = pca.inverse_transform(Z)
print(A_approx)
[[-0.2452941 ]
[-0.29192442]
[ 0.29192442]
[ 0.82914294]
[-0.58384884]]
[[2.33563616e+00 2.91695452e+03]
[2.20934082e+00 2.71106794e+03]
[3.79065918e+00 5.28893206e+03]
[5.24568220e+00 7.66090960e+03]
[1.41868164e+00 1.42213588e+03]]
结合SVM做AT&T数据集人物图像分类
后面的函数都添加到同一个文件里,修改主函数以运行不同的功能。
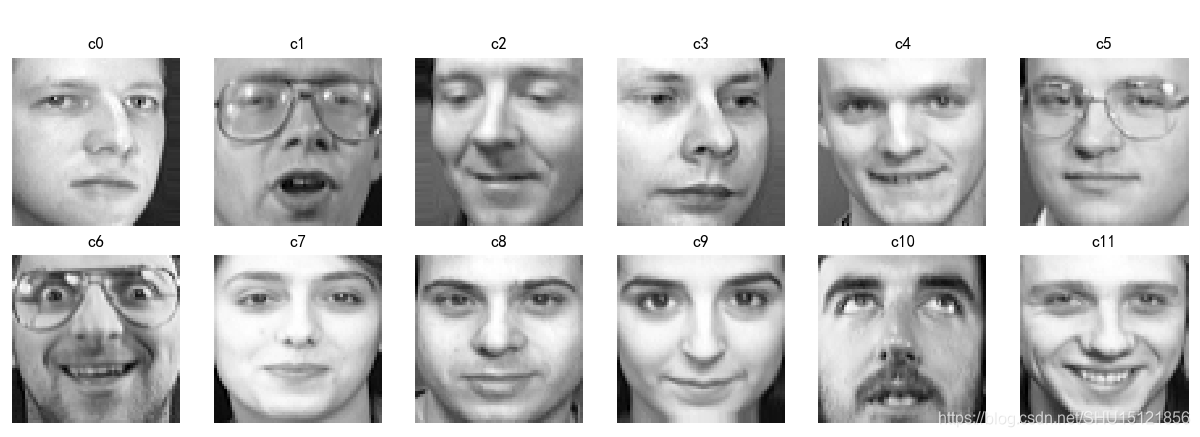
数据初始化和查看样本图像
后面的功能不再贴出"数据初始化"部分的输出。
import logging
from sklearn.datasets import fetch_olivetti_faces
import numpy as np
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
from z10.pca_skl import std_PCA
from sklearn.model_selection import GridSearchCV
def init():
global X, y, targets, target_names, n_targets, n_samples, h, w, X_train, X_test, y_train, y_test
# 更改logging日志模块的默认行为
logging.basicConfig(level=logging.INFO, format='%(asctime)s %(message)s')
# 读取数据
data_home = 'E:\Data\code\datasets'
logging.info("开始读取数据集")
# Load the Olivetti faces data-set from AT&T (classification).
faces = fetch_olivetti_faces(data_home=data_home)
logging.info("读取完成")
# 统计
X = faces.data # 数据
y = faces.target # 标签.这里给出的实际是索引号
targets = np.unique(y) # 标签只留一个
target_names = np.array(["c%d" % t for t in targets]) # 用索引号给人物命名为"c索引号"
n_targets = target_names.shape[0] # 类别数
n_samples, h, w = faces.images.shape # 样本数,图像高,图像宽
print("样本数:{}\n标签种类数:{}".format(n_samples, n_targets))
print("图像尺寸:宽{}高{}\n数据集X的shape:{}".format(w, h, X.shape))
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=2)
def plot_gallery(images, titles, h, w, n_row=2, n_col=5):
"""绘制图片阵列"""
plt.figure(figsize=(2 * n_col, 2.2 * n_row), dpi=100)
# 跳帧子图布局,这里hspace指子图之间高度h上的间隔
plt.subplots_adjust(bottom=0, left=0.01, right=0.99, top=0.90, hspace=0.01)
for i in range(n_row * n_col):
plt.subplot(n_row, n_col, i + 1)
plt.imshow(images[i].reshape((h, w)), cmap='gray')
plt.title(titles[i])
plt.axis('off') # 不提供坐标轴
def look_face(only_get_sample=False):
"""查看人脸图片阵列,参数为True时不做绘图,仅仅返回样本"""
n_row = 2
n_col = 6
sample_images = None
sample_titles = []
# 对于每个可能的标签
for i in range(n_targets):
# 选取出该标签的所有样本
people_images = X[y == targets[i]]
# 随机从中选取出一个样本,即对这个人随机选它的一张照片
people_sample_index = np.random.randint(0, people_images.shape[0], 1)
people_sample_image = people_images[people_sample_index, :]
# (不是第一个放进来的人)
if sample_images is not None:
# 这时要用np.concatenate()做数组拼接,即将这个人(的特征数组)放在下一行
sample_images = np.concatenate((sample_images, people_sample_image), axis=0)
# (是第一个放进来的人)
else:
sample_images = people_sample_image
# 将标签放入标签列表中
sample_titles.append(target_names[i])
# 如果仅仅是要得到样本,这里就不绘图
if only_get_sample:
return sample_images, sample_titles
# 调用绘制图片阵列的函数来绘制这些人脸图像的图片阵列
plot_gallery(sample_images, sample_titles, h, w, n_row, n_col)
plt.show()
if __name__ == '__main__':
init()
look_face()
样本数:400
标签种类数:40
图像尺寸:宽64高64
数据集X的shape:(400, 4096)
尝试直接使用SVM做分类
特征太多(4096),直接使用SVM分类效果很差。
def just_svm():
"""仅仅使用svm分类"""
# class_weight用于解决数据不均衡,s设置为'balanced'由类库自己计算权重
clf = SVC(class_weight='balanced')
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
cm = confusion_matrix(y_test, y_pred, labels=range(n_targets))
print("混淆矩阵:")
# 设置打印时显示方式,threshold=np.nan意思是输出数组的时候完全输出,不需要省略号将中间数据省略
np.set_printoptions(threshold=np.nan)
print(cm)
print("分类报告:")
# 这里因为除以0的问题会报warning,见:https://stackoverflow.com/questions/34757653
print(classification_report(y_test, y_pred, target_names=[d for d in target_names]))
if __name__ == '__main__':
init()
just_svm()
混淆矩阵上并未出现"对角线"上大多非零值这样的正常分类现象。

出现warning是生成分类报告中某些指标除以0产生的,另外测试样本未必能选取到所有的类别(人),也会导致直接打入类别标签时,出现类别找不到的情况。
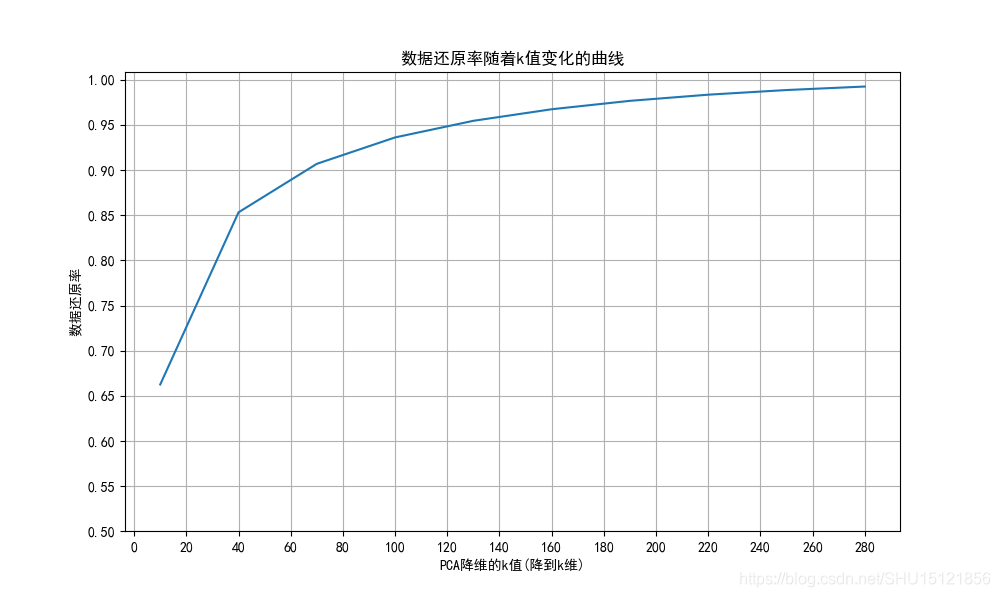
绘制数据还原率随k值变化的曲线
这里k是降维到的维度,数据还原率这里由降维后的各主成分的方差值占总方差值的比例表征。
def draw_explained_variance_ratio():
"""
explained_variance_ratio_
代表降维后的各主成分的方差值占总方差值的比例
直接影响数据还原率,该函数即用于绘制k值对数据还原率的影响
"""
# 让k值取值0~300之间每隔30次采样一次,计算PCA处理后的数据还原率
candidate_components = range(10, 300, 30)
# 存数据还原率的列表
explained_ratios = []
# 对每次选取的k值
for k in candidate_components:
# 做归一化和PCA得到降维后的Z
model = std_PCA(n_components=k)
Z = model.fit_transform(X)
# 拿出其中的PCA模型
pca = model.named_steps['pca']
# pca.explained_variance_ratio_得到的是各维度的方差值占总方差值的比例,对其求和得到的就是数据还原率
explained_ratios.append(np.sum(pca.explained_variance_ratio_))
plt.figure(figsize=(10, 6), dpi=100)
plt.grid()
# 绘制数据还原率随着k值变化的曲线
plt.plot(candidate_components, explained_ratios)
plt.xlabel("PCA降维的k值(降到k维)")
plt.ylabel("数据还原率")
plt.title("数据还原率随着k值变化的曲线")
plt.yticks(np.arange(0.5, 1.05, 0.05))
plt.xticks(np.arange(0, 300, 20))
plt.show()
if __name__ == '__main__':
init()
draw_explained_variance_ratio()
绘制原图和在不同还原率下的图像,进行对比
这里只取前5个人 ,使用到了最开始定义的绘制图片阵列的函数。
def draw_orign_to_restore():
"""绘制原图和在不同还原率下的图像,进行对比"""
# 这里只固定列数,行数取决于后面用了多少k值
n_col = 5
# 采样取得每个人的数据和标签,每个人只取一条
sample_images, sample_titles = look_face(only_get_sample=True)
# 只取前5个人
sample_images = sample_images[0:5]
sample_titles = sample_titles[0:5]
# 要绘制的图,先把这5张原始图放进来
plotting_images = sample_images
# 该函数用于组合成title
title_prefix = lambda a, b: "{}:{}".format(a, b)
# 对应的标题,也是先放入这五个原始图的标题
plotting_titles = [title_prefix('orig', t) for t in sample_titles]
# k值
candidate_components = [140, 75, 37, 19, 8]
# 对每一种k值
for k in candidate_components:
# 用总样本集X训练PCA模型
model = std_PCA(n_components=k)
model.fit(X)
# 仅对这5张图数据进行降维
Zs = model.transform(sample_images)
# 还原回来
Xs_inv = model.inverse_transform(Zs)
# 将新得到的5张还原回来的图接在要绘制的图的数组里
plotting_images = np.concatenate((plotting_images, Xs_inv), axis=0)
# 标题也是,相应的标题也生成然后加进来
titles_pca = [title_prefix(k, t) for t in sample_titles]
plotting_titles = np.concatenate((plotting_titles, titles_pca), axis=0)
# 绘图
plot_gallery(plotting_images, plotting_titles, h, w, 1 + len(candidate_components), n_col)
plt.show()

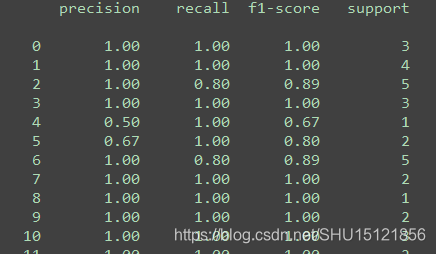
PCA降维+SVM分类
这里用到了前面装在Pipeline里的带数据与处理的PCA模型,使用GridSearchCV()在降维后的数据集上找到了给出的参数表中最佳的参数,然后使用最佳参数对应的分类器clf.best_estimator_进行分类,最终输出分类报告。
def pca_svm():
"""PCA降维+SVM分类"""
k = 140
# svd_solver='randomized'指定随机SVD,whiten=True做白化变换,让降维后的数据方差都为1
model = std_PCA(n_components=k, svd_solver='randomized', whiten=True)
# 注意,PCA的fit(即获得主成分特征矩阵U_reduce的过程)仅使用训练集!
model.fit(X_train)
# 训练集和测试集分别降维
X_train_pca = model.transform(X_train)
X_test_pca = model.transform(X_test)
# 使用GridSerachCV选择最佳的svm.SVC模型参数
param_grid = {'C': [1, 5, 10, 50, 100], 'gamma': [0.0001, 0.0005, 0.001, 0.005, 0.01]}
# verbose控制verbosity,决定输出的过程信息的复杂度,=2详细
clf = GridSearchCV(SVC(kernel='rbf', class_weight='balanced'), param_grid, verbose=2, n_jobs=4)
# 这里用降维后的训练集来找最佳参数,则找到的最佳参数也会适合降维后的训练集
clf = clf.fit(X_train_pca, y_train)
print("寻找到的最佳参数:", clf.best_params_)
# 用找到的最佳参数对降维后的测试集做预测,可以直接用clf.best_estimator_获得训练好的最佳参数模型
y_pred = clf.best_estimator_.predict(X_test_pca)
# 输出分类报告看一下
print(classification_report(y_test, y_pred))
if __name__ == '__main__':
init()
pca_svm()
指定verbose=2能在寻找参数时输出更多的中间信息。
使用降维后的高斯核SVM分类器做分类,分类效果大大提升。