最近在做训练的时候遇到了做训练集的问题,所以总结一下自己做数据集的思路与操作。ubuntu16.04.
一、VOC数据集格式:做检测的时候会遇到,每一个图中可能有几个目标,每个目标都有一个位置信息保存到xml文件中,如果想将此类数据做成lmdb格式,首先就是要标记图像,得到每一个图中目标的位置信息,标记的程序可以网上找到,标记的工作量还是很大的,这里讲做好xml文件之后怎么做成lmdb。
1、首先在github上下载一个caffe-ssd,然后编译caffe-ssd,这个编译的方法网上有很多,这里就不多说了。编译好之后在./data中输入指令下载VOC0712数据集:【因为下面的两个脚本还调用了其他的Python文件,所以还要 make pycaffe】
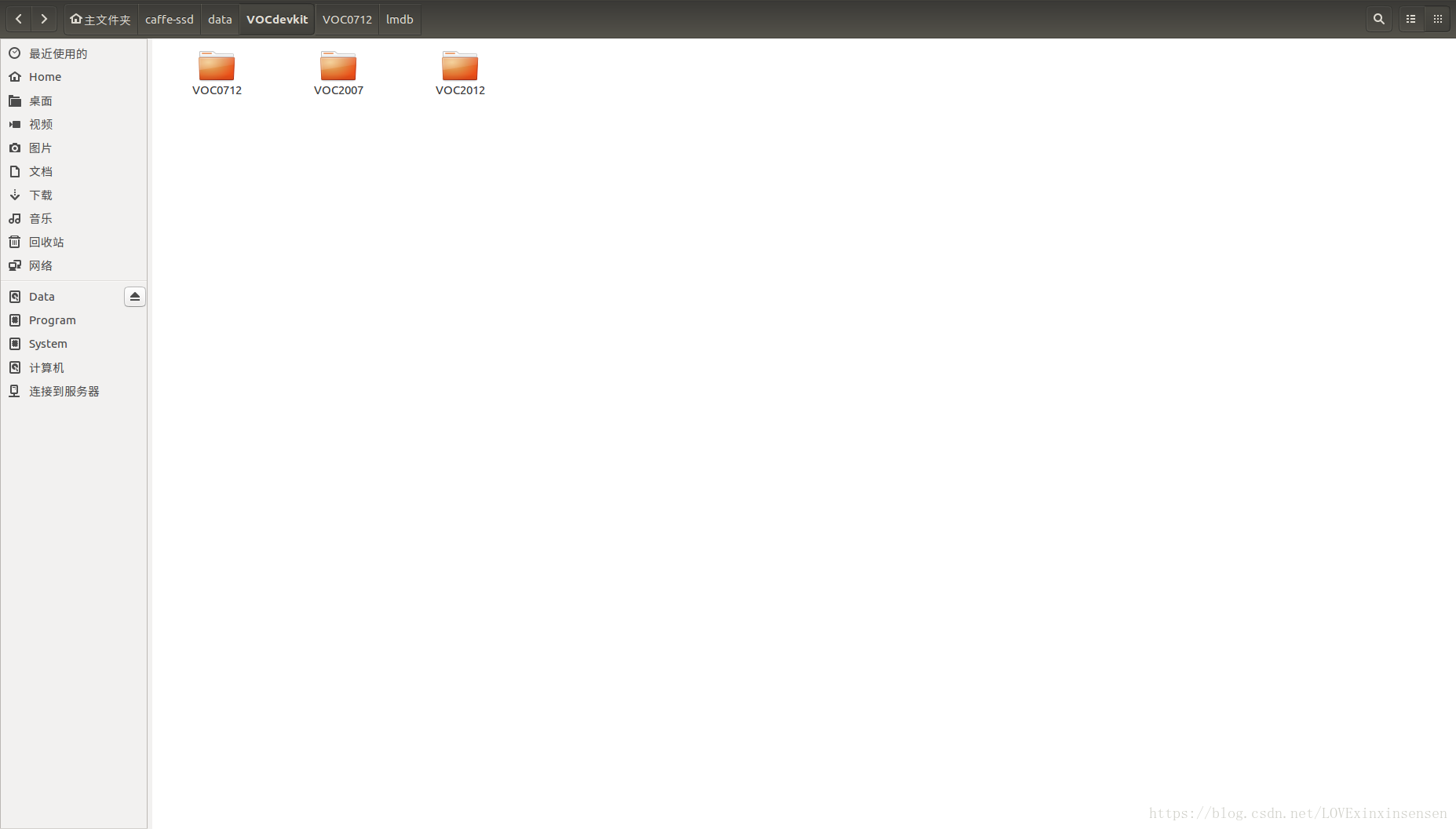
解压之后如下图所示,在VOCdevkit文件夹内有两个文件夹,VOC2007和VOC2012,第一个文件夹是我生成的lmdb文件。
2、创建lmdb格式的数据集
下面贴出来creat_list.sh的代码:
create_data.sh下面的这个代码就是要做成lmdb格式的数据集了。
然后就能看到lmdb格式的数据集就生成了。注意这里照着博主的改法就可以了,先执行create_list.sh脚本再执行create_data.sh脚本,数据集要提前准备好。
如果是自己的数据集的话要先用标记的程序标记目标位置,生成xml文件,然后按照voc数据集的格式去生成lmdb文件。
二、图片和label做成lmdb格式(用于图片分类)
扫描二维码关注公众号,回复: 4636651 查看本文章
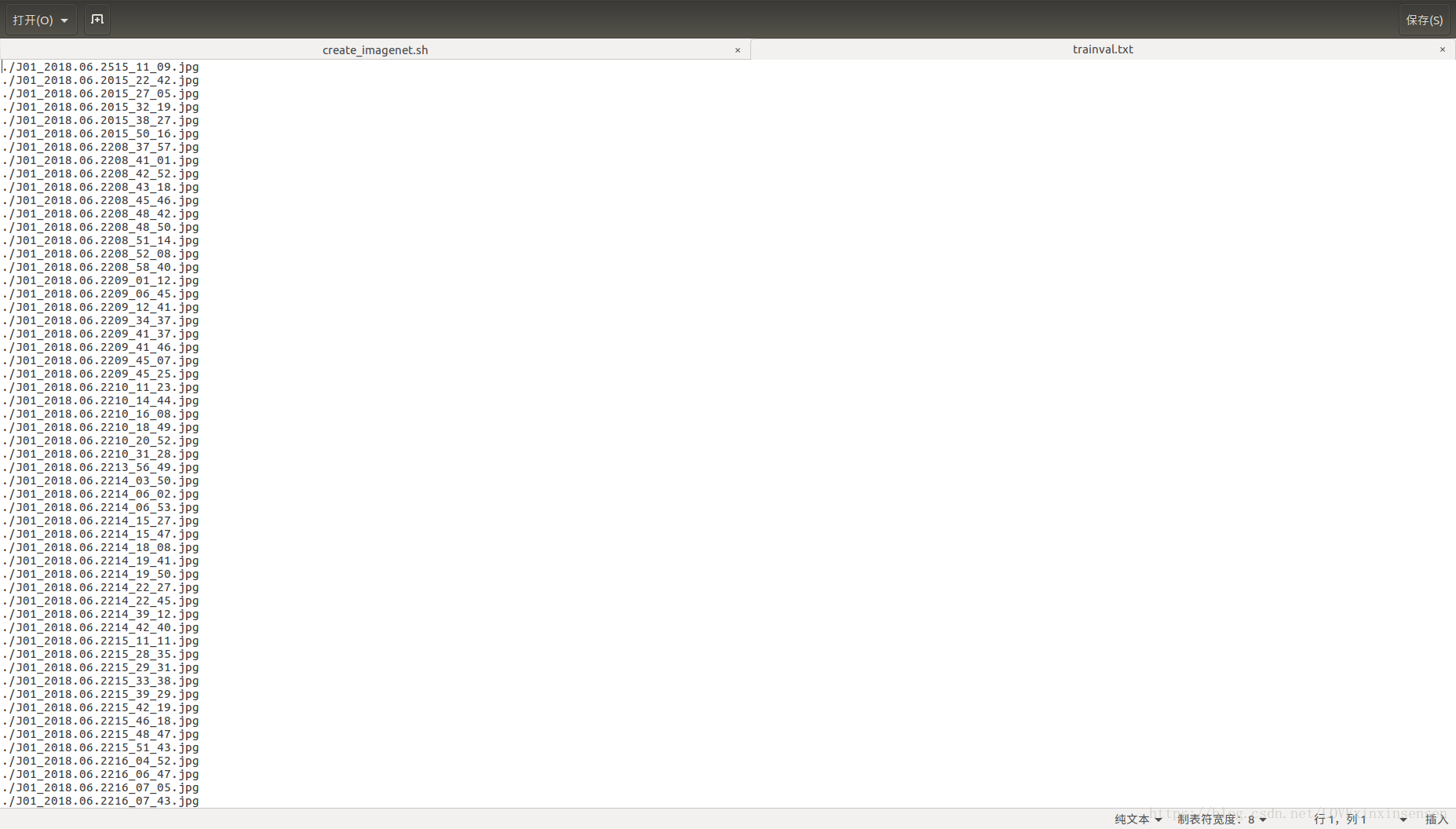
1、首先将同一label的train数据集放到一个文件夹内,在该文件夹内打开terminal输入find -name "*.jpg*" > trainval.txt,这样就可以将该文件夹内所有的图片全部存到txt中;
2、生成的txt中,将jpg替换成jpg 1 (1是这些图片对应的label,中间有空格)
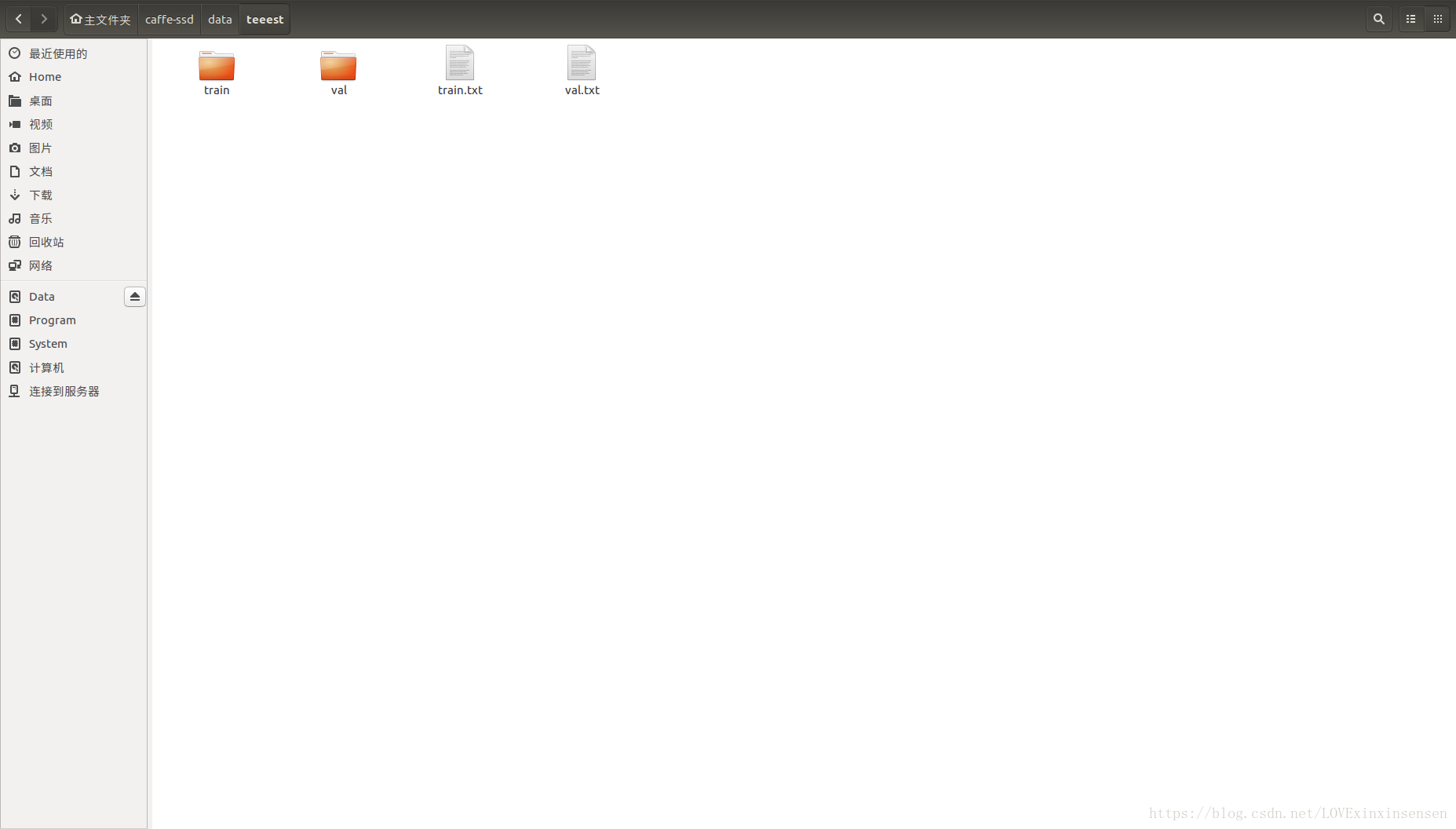
3、将所有的train。txt合在一起,图片也全部放到train文件夹中,将所有的test的txt和图片同样操作。
4、在examples/imagenet下找到create_imagenet.sh文件,如下,修改
5、运行这个sh文件,就可以生成lmdb文件了。
三、语义分割的数据集(按像素分类)待补充,暂时还没有用到,等用到的时候再更新吧
最近在做训练的时候遇到了做训练集的问题,所以总结一下自己做数据集的思路与操作。ubuntu16.04.
一、VOC数据集格式:做检测的时候会遇到,每一个图中可能有几个目标,每个目标都有一个位置信息保存到xml文件中,如果想将此类数据做成lmdb格式,首先就是要标记图像,得到每一个图中目标的位置信息,标记的程序可以网上找到,标记的工作量还是很大的,这里讲做好xml文件之后怎么做成lmdb。
1、首先在github上下载一个caffe-ssd,然后编译caffe-ssd,这个编译的方法网上有很多,这里就不多说了。编译好之后在./data中输入指令下载VOC0712数据集:【因为下面的两个脚本还调用了其他的Python文件,所以还要 make pycaffe】
解压之后如下图所示,在VOCdevkit文件夹内有两个文件夹,VOC2007和VOC2012,第一个文件夹是我生成的lmdb文件。
2、创建lmdb格式的数据集
下面贴出来creat_list.sh的代码:
create_data.sh下面的这个代码就是要做成lmdb格式的数据集了。
然后就能看到lmdb格式的数据集就生成了。注意这里照着博主的改法就可以了,先执行create_list.sh脚本再执行create_data.sh脚本,数据集要提前准备好。
如果是自己的数据集的话要先用标记的程序标记目标位置,生成xml文件,然后按照voc数据集的格式去生成lmdb文件。
二、图片和label做成lmdb格式(用于图片分类)
1、首先将同一label的train数据集放到一个文件夹内,在该文件夹内打开terminal输入find -name "*.jpg*" > trainval.txt,这样就可以将该文件夹内所有的图片全部存到txt中;
2、生成的txt中,将jpg替换成jpg 1 (1是这些图片对应的label,中间有空格)
3、将所有的train。txt合在一起,图片也全部放到train文件夹中,将所有的test的txt和图片同样操作。
4、在examples/imagenet下找到create_imagenet.sh文件,如下,修改
5、运行这个sh文件,就可以生成lmdb文件了。
三、语义分割的数据集(按像素分类)待补充,暂时还没有用到,等用到的时候再更新吧