目前在调研基于深度学习的观点对超分辨率问题的解决,对于其中的一些方法进行了一个大概的综述,现将其总结如下:
SRCNN
模型架构
SRCNN是深度学习用在超分辨率上的开山之作。首先将图片通过插值的方式放大到需要变换的尺寸。然后再将放大后的图片放入到一个3层的卷积神经网络中,最终输出一个较为清晰的图片。其对应的3层卷积网络结构如下:

上述网络层次比较简单但是效果已经能够远远超过传统的方式。其对应的精确度也与两次卷积计算的卷积核的多少有关系,卷积核越多其对应的结果越好。该模型的输入可以使RGB的也可以是YUV中的Y分量。在实验中作者采用了Y分量进行(主要是为了能够公平的和目前已有的大部分处理方式进行比较)。但是该模型输入的较大尺寸的图片,所以对应的速度较慢。
FSRCNN
模型架构
FSRCNN的提出人和SRCNN是同一个,主要是为了解决SRCNN需要提前进行立方差值作为输入的问题。FSRCNN的输入是一个低分辨率的图片,经过一系列的卷积之后,最后采用逆卷积进行上采样扩大。这样处理的好处有三点:1. 输入的数据尺寸较小,这样计算较快;2. 当需要不同比率的大小时直接微调最后一层的反卷积即可,整个网络的前部分可以共享和复用;3. 整个训练过程采用3X3的卷积进行,通过一系列的小卷积串联达到大卷积的目的。
由于输入的数据尺寸较小,所以此时不在采用9X9的卷积核而是采用5X5的卷积核,同时为了跟别的模型对比,此时依然是对YUV数据中的Y通道进行处理,所以输入的通道数是1,因此第一层的卷积核是cov(5,d,1),其中d表示卷积核的个数,5表示卷积个的尺寸,1表示卷积计算的输入通道也就是指卷积计算前的通道数。由于需要将低分辨率变成对应的高分辨率,因此对低分辨率的特征提取要多一些,这样才能保证恢复的图片拥有更多的特征。所以此时的d往往比较大,对于比较大的d会增加复杂度。因此在后面采用s个1X1的卷积核将其通道数降为s个,即cover(1,s,d);紧接着需要对特征进行一些非线性的变换;该网络借鉴了VGG的小卷积串联思想将m个3x3的卷积进行串联,串联的卷积核个数始终为s个,即mXcov(3,s,s);特征提取之后由于用于从建的图片需要的特征往往较多,所以在使用d个1X1的卷积核将特征的个数恢复至d个,即cov(1,d,s),根据实验显示如果不使用该层进行恢复,则对应的结果PSNP值下降0.3 。最后使用1个9X9的卷积进行逆卷积计算来扩大维度即cov(9,1,d)。
关于最后一层的卷积主要有以下几个说明:1. 考虑到如果逆向选取的话(即对高分辨率的图片变换成低分辨率的图片)采用SRCNN提取特征时使用的是9x9的,因此作者也采用9x9的卷积;2. 根据卷积计算可知,当stride取值为n时,计算后的大小变成原来的1/n,所以逆过来当stride取值为n时,结果就变成原来的n倍。根据上述原理其对应的网络结够如下:(其中卷积层的stride均为1,即不改变大小)

由上述结构可以看出关于FSRCNN的主要参数是。这也是一些人所说FSRCNN的参数。在该网络中激活函数采用的是PRELU并且在串联的3X3卷积中并不适用激活层,只在最后一个使用。论文作者使用的是56,12,4的参数对性能进行评估,即d=56,s=12,m=4 。其具体性能见后面的性能表。
VDSR
模型架构
VDSR其本质上还是对SRCNN的一个改进,只是改进的出发点不一样。主要针对的是SRCNN输入的图像较小(虽然放大之后但是总体的输入只能是较小的输入,输入较大时效果不好);收敛慢以及只对某一个固定比率有效(其他比率效果很差,也就相当于无效)这三方面进行的。同时改进的过程中也致力于精度的提高。

根据低分辨率图片和高分辨率图片有相同的低频信息的特点,采用先将低分辨率图片进行扩大,然后将其直接传入网络的最后一层和网络直接相加最终得到高分辨率图片的思想,使得网络不在学习所有特征而是只学习图片对应的高频特征。这样虽然网络的层数加深了,但是由于网络学习的特征不再是所有的特征,直接导致连接的方式变成了稀疏链接,这样总体的学习速度反而加快了。其具体结构如上图:输入的依然是采用插值方式得到的不清晰的大分辨率图片,输出的是较为清晰的大分辨率图片,其中所有的卷积核的尺寸均是3X3的。
由于该方法的网络层数比较大(20层)所以其PSNP值相对会高一些,但是同时也会面临梯度爆炸和梯度消失的风险,因此该网络在训练的时候采用了循环神经网络常用的梯度分割方法,将梯度限制在范围内,其中表示的是学习率,并且在开始的时候比较大,训练的过程中随着步骤会变化会慢慢变小(常用的指数衰减或者几何衰减)。
针对SRCNN训练尺寸单一的弊端,该方法采用多个尺度一起训练,最终得到了可以满足常用的(2,3,4)倍数的尺度模型,该步骤个人理解只是训练的数据里面有不同倍数的图片对,其网络的结构和参数并没有发生改变,但是理解并不深入。
由于网络的主要目的是为学习高频部分,所以本次采用residual_learning来计算损失。其具体的公式为: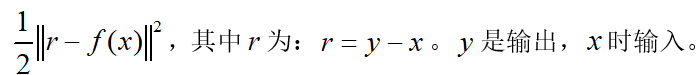 。相减表示去掉了对应的低频部分,剩余的是高频部分的信息。
。相减表示去掉了对应的低频部分,剩余的是高频部分的信息。
除了上述策略之外,该方法还提出了一个应对卷积变小的策略,就是如果通过卷积计算导致计算后的图片尺寸变小的话就在图片周围补0,通过补0使图片恢复原来的大小。个人认为该方法并不是原创,也没有太大的必要,因为在卷积计算时如果使用stride的步长为1,边界处理的方式为padding=SAME,计算后的尺寸并不会减小。
ESPCN
模型架构
ESPCN也是基于SRCNN进行改进的,只不过改进的时候采用的另外一个策略:即输入的原始分辨率较低的图片,使用亚像素卷积(sub-pixel convolutional)的方式将低分辨率的图片放大到超分辨率的倍数上。其具体结构如下:
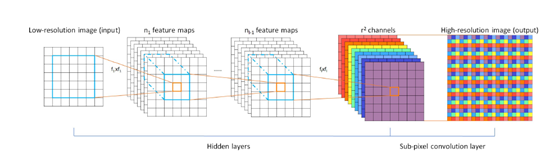
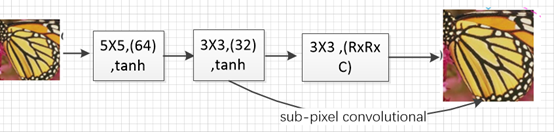
如上所示:模型使用了三层卷积计算(和SRCNN的层数相同),前面两层均是在低分辨率图片上进行的,最后一层卷积要求卷积核的个数是,其中表示放大的倍数,表示图片的通道数。然后在根据重排列的策略使得最后输出的通道数变成,图片的大小变成达到扩大图像尺寸的目的。最后重排列的公式如下:

![]() 表示最后一层特征图的位置,
表示最后一层特征图的位置, ![]() 第几个通道。个人认为第三层卷积生成的结果加上排序的方式在一起才被称为亚像素卷积(sub-pixel convolutional)。
第几个通道。个人认为第三层卷积生成的结果加上排序的方式在一起才被称为亚像素卷积(sub-pixel convolutional)。
该方法利用低分辨率特征进行卷积计算提高了对应的卷积计算速度,同时采用了亚像素积的方式进行大小的扩张,在准确度上得到了适当的提高;采用tanh的激活函数,也提高了准确度(实验表明的)。
LapSRN
模型架构
LapSRN主要是吸取了VDSR和FSRCN的观点,结合逆卷积和残差的思想来来提高速度和精度。除此之外该模型还采用了拉普拉斯金字塔的思想来完成当网络多倍数的学习。其主要的出发点是目前无论SRCNN,FSRCNN还是VDSR都存在以下几方面的问题:
- 有些方法在输入网络之前需要采用预先定义上采样(比如bicubic)来获得目标尺寸,这样增加了额外的计算开销,但同时也导致了虚影。而有的方法则采用亚像素卷积和逆卷积采样,这样的网络往往过于简单,性能较差并不能学习到低分辨到高分辨率的复杂映射。
- 在训练的时候采用的损失函数,不可避免的会产生模糊的预测,恢复的图片过于平滑(不是很理解)。
- 重建时只采用一次上采样操作,这样导致模型在获得大上采样(8倍以上)因子时比较困难,而且在不同的上采样模型往往需要训练不同的模型(VDSR虽然通过多个尺度一起训练的方式解决这个问题,但是其能力依然有限)。
针对上述的问题,作者提出使用残差的思想来加深网络,使用分级上采样的思想每次上采样2倍来进行整个结构的扩大(8倍就需要3级),采用Charbonnier惩罚函数来作为误差计算的方式。并基于这些方法提出了LapSRN模型。其具体结构如下:

由上述结构可以看出该结构是一个分级计算的,其中每一级中间进过一系列的卷积计算(3X3的卷积核,64),卷积之后添加一个逆卷积核(4X4),然后再有两个分支一个分支继续进行下一级对应的卷积计算(3X3,64个),另一个分支采用一个卷积提取上采样之后的特征(3X3,c个),该特征就是高频特征。除此之外还有一条分路是直接使用逆卷积的计算方式(逆卷积采用的卷积核跟特征提取时采用的一样)将原图进行扩张,最终得到相同倍数的上采样图,和卷积网络得出的高频特征相加得到恢复后的图。依次往后可以得到最终需要的大小,并且中间过程是2倍2倍往上增加的。另外对于低层的2倍和4倍那两级一般卷积核采用的是10层卷积,对于8倍的那一级不希望有太多的卷积规则(文献上说的,具体原因不详)因此采用的是5层卷积。
因为该网络有另一条分支直接连接网络的输出特征进行相加,所以属于残差结构,同时由于其学习的是高频特征,因此属于稀疏链接,所以虽然网络的层数增加了,但是其对应的计算反而减少了,其速度反而提高了。另外每一级的网络都是提高2倍,采用的卷积结构几乎一样,所以在每一级之间卷积的参数也是共享的,由于这一共享机制的存在导致该网络在训练的时候往往也会有更好的速度。
除此之外该网络采用的损失函数是Charbonnier惩罚函数,其具体形式如下:
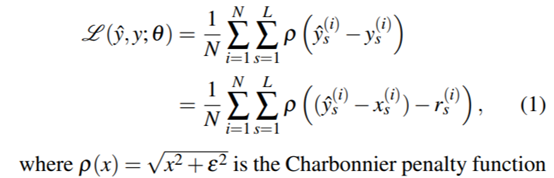
其中![]() 表示第s级网络学习得到的残差,
表示第s级网络学习得到的残差,![]() 表示原图经过上采样得到的预测图,根据上述原理,输出的结果为
表示原图经过上采样得到的预测图,根据上述原理,输出的结果为![]() 为真的扩大一定比例的图片,由于实际在使用中往往不存在同一副图的多比例原图,所以一般都是使用最大比例的图经过插值(bicubic)降到对应的尺寸(这也是一种常用的手段)。
为真的扩大一定比例的图片,由于实际在使用中往往不存在同一副图的多比例原图,所以一般都是使用最大比例的图经过插值(bicubic)降到对应的尺寸(这也是一种常用的手段)。![]() 表示对应的图片个数,
表示对应的图片个数,![]() 表示对应的级数。一般取值为1e-3。由上述计算公式可以看出,该结构在计算上是将各级(放大的比例)网络的误差相结合起来一起发挥作用。
表示对应的级数。一般取值为1e-3。由上述计算公式可以看出,该结构在计算上是将各级(放大的比例)网络的误差相结合起来一起发挥作用。
SRGAN和SRResNet
模型架构
SRResNet结构简单的说就是使用残差模型作为整个网络的主要框架来完成对应的模型构建。该模型的出发点是为了提高精度,因此其采用了更深层次的残差网络提高准确度。主要是由于残差网络是目前在ImageNet上取得成绩较好的模型,同时根据VDSR残差可以 提高训练的速度加深网络的层数,因此采用了残差的思想,但是这个残差和VDSR不同,VDSR更多的只是将输入的低分辨率的网络结构直接送入到最后一层,属于全局残差。但是SRResNet的残差具体是指卷积计算的过程中使用的是残差块(Residual block)构建卷积计算(属于局部),其对应结构主要如下图:
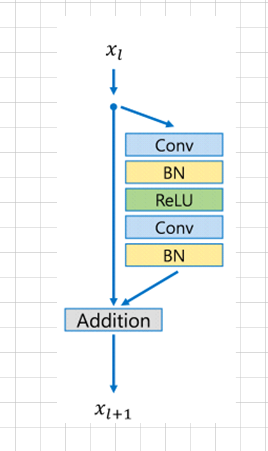
根据该结构并结合ESPCN网络的处理方式,采用亚像素卷积的思想最终就产生了SRResNet的超分辨率构建模型,其具体模型架构如下:大部分使用的是3X3的卷积核。

由于该网络结合了最新的ResNet结构和亚像素卷积,因此其准确度上已经达到了相当高的水平,他可以单独作为一个超分辨率重建的网络模型使用。但是现在提起SRResNet大部分是将其结合进SRGAN模型使用的。SRGAN 模型主要是使用GAN(对抗生成网络)来进行超分辨率重建的任务。
GAN模型主要分为两个网络即G网络和D网络。其中G网络用来生成图片,D网络用来判断一张图片是不是人为生成的,两个网络的目的是互斥的。也就是说G的目的是尽量生成一张正确的,误差小的图片,使其能够骗过D网络的图片,让D网络无法区分;D网络的目的是尽量判断出G网络生成的图片,将他与真实图片分开。当G网络生成的一张图片,D网络无法判断时就说明训练结束了。SRGAN主要就是使用了GAN的思想,将上述SRResNet的结构用于生成网络G的构建,同时将其对应的残差结构用于D网络的构建,就行成了对应的SRGAN结构,其具体如下:G网络中的B=16(16个残差块),D网络存在8个卷积层。
