在大二第一学期因为兴趣原因,自己学习了一些数据分析的算法,这里面便包含决策树,总的来说,学习的情况还是比较良好的,有那个意愿自己去学习.现在想想,那时的学习过程还是挺艰辛的,因为其实几种决策树,ID3,C4.5,CART之间的区别,当时在网上是有很多说法的,或者说其实很多说法说的都对,但都是答案的一部分,当时查了很久不得其解,比如说有的说CART跟其他两种的区别在于用GINI属性来划分属性,有的说是因为既可以进行分类也可以进行回归,既可以处理离散属性,也可以处理连续的.其实这些都是正确的,只是有些博客说的片面了点而已.
现在回过头来再次学习,一方面由于熟悉的原因,另一方面感觉自己阅读代码的能力还是有所进步的(主要是python),整个算法的流程还是能够比较快地梳理出来的.
一. 决策树介绍
决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树。
二. 原理介绍
决策树是一种非参数的监督学习方法,它主要用于分类和回归。决策树的目的是构造一种模型,使之能够从样本数据的特征属性中,通过学习简单的决策规则——IF THEN规则,从而预测目标变量的值。
决策树往往采用的是自上而下的设计方法,每迭代循环一次,就会选择一个特征属性进行分叉,直到不能再分叉为止。因此在构建决策树的过程中,选择最佳(既能够快速分类,又能使决策树的深度小)的分叉特征属性是关键所在。这种“最佳性”可以用非纯度(impurity)进行衡量。如果一个数据集合中只有一种分类结果,则该集合最纯,即一致性好;反之有许多分类,则不纯,即一致性不好。有许多指标可以定量的度量这种非纯度,最常用的有熵,基尼指数(Gini Index)和分类误差,它们的公式分别为:


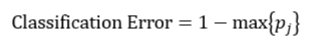
上述所有公式中,值越大,表示越不纯,这三个度量之间并不存在显著的差别。式中D表示样本数据的分类集合,并且该集合共有J种分类,pj表示第j种分类的样本率:
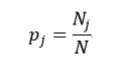
式中N和Nj分别表示集合D中样本数据的总数和第j个分类的样本数量。把式4带入式2中,得到:

目前常用的决策树的算法包括ID3(Iterative Dichotomiser 3)、C4.5和CART(ClassificationAnd Regression Tree,分类和回归树)。前两种算法主要应用的是基于熵的方法,而第三种应用的是基尼指数的方法。
ID3和C4.5最大的差别在于,分类时的依据,ID3依据信息增益(基于熵),而C4.5是依据信息增益率.ID3应用的信息增益的方法存在一个问题,就是它会更愿意选择那些包括很多种类的特征属性,即哪个A中的n多,那么这个A的信息增益就可能更大。为此,C4.5使用信息增益率这一准则来衡量非纯度,可以对比一下:
ID3

C4.5

CART决策树,则主要用了基尼不纯度作为分类标准,这是分类树,而回归树,则是用了方差来衡量数据,把适合分类的非纯度度量用适合回归的非纯度度量取代.简单来说,区分分类树和回归树,在于分类树的样本输出(即响应值)是类的形式,而回归树的样本输出是数值的形式.
上面所说的熵和基尼不纯度,主要就是决策树在构建过程中,将数据要按那个属性进行划分的依据,总的来说,分类数据总是从无序到有序,但在这个过程中,数据收敛到该算法能达到的最佳情况下的时间和步骤也不一样,最佳构建出的决策树也会有所差异.
三. 学习心得
在我学习之后,我认为在实际学习生活应用中,分类和回归,有时还是可以相互转换的,不是说原本数据是类别,传入参数就一定是类别,也不一定说原本数据是数值,传入参数就一定不能是类别,这还是要根据实际情况对数据进行预处理,处理成能够符合你建立的模型的数据,方可进行模型的训练.
对了,决策树中构建树用到的衡量度,熵和基尼指数,我查了许多资料后,发现,熵和基尼不纯度之间的主要区别在于,熵达到峰值的过程要相对慢一些.因此,熵对混乱集合的”判罚”要相对重一些,在现实中,人们对熵的使用更为普遍.
我总结了一下一棵完整的决策树需要考虑到的问题:
1.当用户想要检测一些非常罕见的异常现象的时候,这是非常难办到的,这是因为训练可能包含了比异常多得多的正常情况,那么很可能分类结果就是认为每一个情况都是正常的.为了避免这种情况的出现,我们需要设置先验概率,这样异常情况发生的概率就被人为的增加(可以增加到0.5甚至更高),这样被误分类的异常情况的权重就会变大,决策树也能够得到适当的调整.这一步我记得在朴素贝叶斯算法里也曾见到过,足以说明这个问题还是挺容易出现在分类中的.
2.第二个需要解决的问题是,某些样本缺失了某个特征属性,但该特征属性又是最佳分叉属性,那么如何对该样本进行分叉呢?目前有几种方法可以解决该问题,一种是直接把该样本删除掉.另一种方法是用各种算法估计该样本的缺失属性值.还有一种方法就是用另一个特征属性来替代最佳分叉属性,该特征属性被称为替代分叉属性.因此在计算最佳分叉属性的同时,还要计算该特征属性的替代分叉属性,以防止最佳分叉属性缺失的情况.
3.过拟合.这是在机器学习算法中很容易出现的问题,在决策树中,解决方法就是将复杂的决策树进行简化,称为剪枝,它的目的是去掉一些节点,包括叶节点和中间节点。剪枝常用的方法有预剪枝和后剪枝两种。预剪枝是在构建决策树的过程中,提前终止决策树的生长,从而避免过多的节点的产生。该方法虽然简单但实用性不强,因为我们很难精确的判断何时终止树的生长。后剪枝就是在决策树构建完后再去掉一些节点。常见后剪枝方法有四种:悲观错误剪枝(PEP)、最小错误剪枝(MEP)、代价复杂度剪枝(CCP)和基于错误的剪枝(EBP)。CCP算法能够应用于CART算法中.
我觉得吧,剪枝是及其重要的一步,能够更好地发挥决策树的优越性,一棵冗杂的树,尽管实现分类决策成功了,但是效率相比较来说比较低,更重要的是可能出现测试数据没有代表性的情况.剪枝较好地解决了过拟合的问题,实际应用价值更大.
决策树,也是非常经典的算法了,一开始学的时候,是觉得名字看起来挺有趣的,而且数据结构时候学过平衡二叉树那些,对树这种结构还是比较熟悉的,结果当时学这个还是有点吃力,主要便在于树的构建和构建之后的优化操作会需要逻辑思维好一点.
我觉得数据挖掘的算法有些还是很有趣的,经典不代表过时,决策树也是作为入门数据挖掘的很好的算法学习之一,我觉得很直观,新手很容易直观地看出分类的走向,虽然内核算法还是要下点功夫好好钻研一下.
当然,以上我的观点和所列举的知识点可能还有不恰当或者缺漏的现象,这也是很可能存在的,毕竟我可能学习时间不够,有一些深层知识点还没体会到的,还是要继续努力下去把.