1、数据收集工具/系统产生背景
Hadoop 业务的整体开发流程:
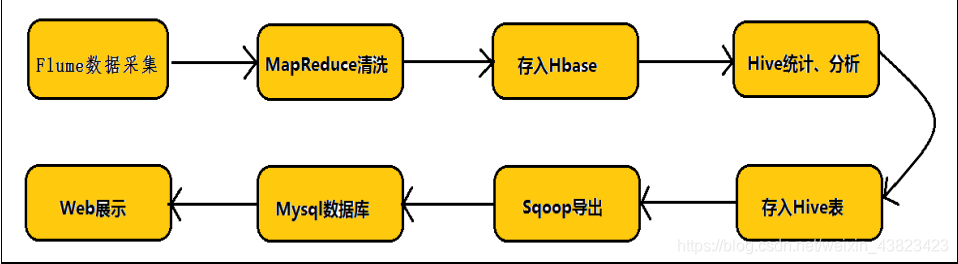
任何完整的大数据平台,一般都会包括以下的基本处理过程:
总结:
数据的来源大体上包括:
1、业务数据
2、爬虫爬取的网络公开数据
3、购买数据
4、自行采集手机的日志数据
2、Flume 概述
Flume is a distributed, reliable, and available service for efficiently collecting, aggregating, and
moving large amounts of log data. It has a simple and flexible architecture based on streaming data
flows. It is robust and fault tolerant with tunable reliability mechanisms and many failover and
recovery mechanisms. It uses a simple extensible data model that allows for online analytic
application.
Flume 是一个分布式、可靠、高可用的海量日志聚合系统,支持在系统中定制各类数据发送
方,用于收集数据,同时,Flume 提供对数据的简单处理,并写到各种数据接收方的能力。
1、 Apache Flume 是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统,和
Sqoop 同属于数据采集系统组件,但是 Sqoop 用来采集关系型数据库数据,而 Flume 用
来采集流动型数据。
2、 Flume 名字来源于原始的近乎实时的日志数据采集工具,现在被广泛用于任何流事件数
据的采集,它支持从很多数据源聚合数据到 HDFS。
3、 一般的采集需求,通过对 flume 的简单配置即可实现。Flume 针对特殊场景也具备良好
的自定义扩展能力,因此,flume 可以适用于大部分的日常数据采集场景
4、 Flume 最初由 Cloudera 开发,在 2011 年贡献给了 Apache 基金会,2012 年变成了 Apache
的顶级项目。Flume OG(Original Generation)是 Flume 最初版本,后升级换代成 Flume
NG(Next/New Generation)
5、 Flume 的优势:可横向扩展、延展性、可靠性
Flume 数据源和输出方式
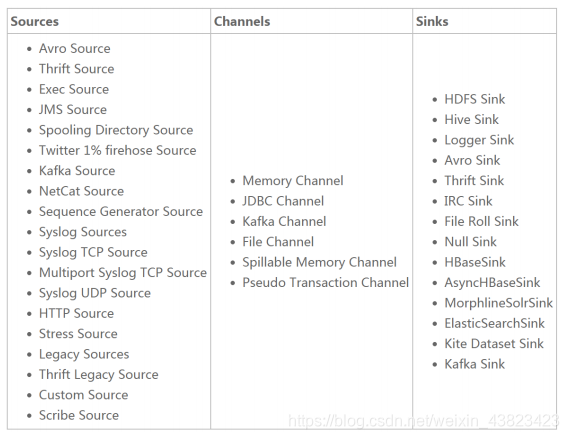
Flume 提供了从 console(控制台)、RPC(Thrift-RPC)、text(文件)、tail(UNIX tail)、syslog(syslog 日志系统,支持 TCP 和 UDP 等 2 种模式),exec(命令执行)等数据源上收集数据的能力,在我们的系统中目前使用 exec 方式进行日志采集。
Flume 的数据接受方,可以是 console(控制台)、text(文件)、dfs(HDFS 文件)、RPC(Thrift-RPC)和 syslogTCP(TCP syslog 日志系统)等。最常用的是 Kafka。
3、Flume 体系结构/核心组件
3.1、概述
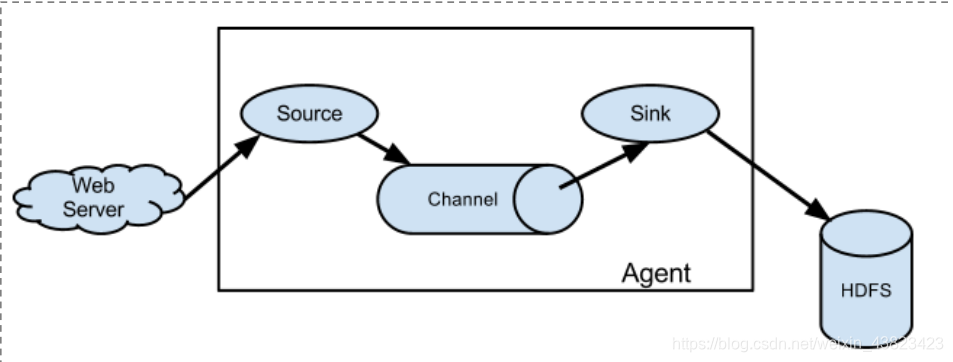
Flume 的数据流由事件(Event)贯穿始终。事件是 Flume 的基本数据单位,它携带日志数据(字节数组形式)并且携带有头信息,这些 Event 由 Agent 外部的 Source 生成,当 Source 捕获事件后会进行特定的格式化,然后 Source 会把事件推入(单个或多个)Channel 中。你可以把Channel 看作是一个缓冲区,它将保存事件直到 Sink 处理完该事件。Sink 负责持久化日志或者把事件推向另一个 Source。
Flume 以 agent 为最小的独立运行单位。
一个 agent 就是一个 JVM。
单 agent 由 Source、Sink 和 Channel 三大组件构成。
如下图:
3.2、Flume 三大核心组件
Event
- Event 是 Flume 数据传输的基本单元。 Flume 以事件的形式将数据从源头传送到最终的目的地。
Event由可选的header 和载有数据的一个 byte array 构成。
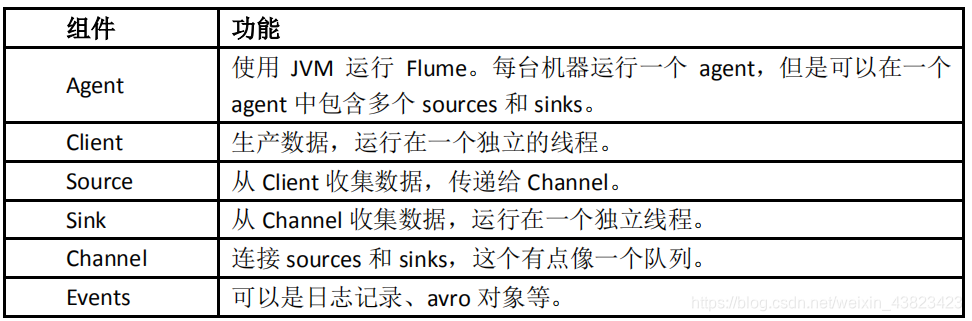
组件 功能
Agent
- 使用 JVM 运行 Flume。每台机器运行一个 agent,但是可以在一个 agent 中包含多个 sources 和 sinks。
Client 生产数据,运行在一个独立的线程。 Source 从 Client 收集数据,传递给 Channel。 Sink 从
Channel 收集数据,运行在一个独立线程。 Channel 连接 sources 和 sinks,这个有点像一个队列。 Events
可以是日志记录、avro 对象等。 载有的数据度 flume 是不透明的。 Header 是容纳了 key-value
字符串对的无序集合,key 在集合内是唯一的。 Header 可以在上下文路由中使用扩展
Client
- Client 是一个将原始 log 包装成 events 并且发送他们到一个或多个 agent 的实体 目的是从数据源系统中解耦
Flume 在 Flume 的拓扑结构中不是必须的。 Client 实例 flume log4j Appender 可以使用
Client SDK(org.apache.flume.api)定制特定的 Client
Agent
- 一个 Agent 包含 source,channel,sink 和其他组件。 它利用这些组件将 events
从一个节点传输到另一个节点或最终目的地 agent 是 flume 流的基础部分。 flume
为这些组件提供了配置,声明周期管理,监控支持。 Source Source 负责接收 event 或通过特殊机制产生 event,并将
events 批量的放到一个或多个 Channel 包含 event 驱动和轮询两种类型。 不同类型的 Source 与系统集成的
Source:Syslog,Netcat,监测目录池 自动生成事件的 Source:Exec 用于 Agent 和 Agent
之间通信的 IPC source:avro,thrift source 必须至少和一个 channel 关联
Agent 之 Channel

- Channel 位于 Source 和 Sink 之间,用于缓存进来的 event 当 sink 成功的将 event 发送到下一个的
channel 或最终目的 event 从 channel 删除 不同的 channel 提供的持久化水平也是不一样的 Memory
channel:volatile(不稳定的) File Channel:基于 WAL(预写式日志 Write-Ahead
logging)实现 JDBC channel:基于嵌入式 database 实现 channel 支持事务,提供较弱的顺序保证
可以和任何数量的 source 和 sink 工作
Agent 之 Sink
- Sink 负责将 event 传输到吓一跳或最终目的地,成功后将 event 从 channel 移除 不同类型的 sink 存储
event 到最终目的地终端 sink,比如 HDFS,HBase 自动消耗的 sink 比如 null sink 用于 agent
间通信的 IPC:sink:Avro 必须作用于一个确切的 channel
Iterator
- 作用于 Source,按照预设的顺序在必要地方装饰和过滤 events
Channel Selector
- 允许 Source 基于预设的标准,从所有 channel 中,选择一个或者多个 channel
Sink Processor
- 多个 sink 可以构成一个 sink group sink processor 可以通过组中所有 sink 实现负载均衡 也可以在一个 sink 失败时转移到另一个。
4、Flume 实战案例
4.1、安装部署 Flume
1、Flume 的安装非常简单,只需要解压即可,当然,前提是已有 Hadoop 环境上传安装包到数据源所在节点上,然后解压 tar -zxvf apache-flume-1.8.0-bin.tar.gz,然后进入 flume 的目录,修改 conf 下的 flume-env.sh,在里面配置 JAVA_HOME
2、根据数据采集的需求配置采集方案,描述在配置文件中(文件名可任意自定义)
3、指定采集方案配置文件,在相应的节点上启动 flume agent先用一个最简单的例子来测试一下程序环境是否正常
1、在$FLUME_HOME/agentconf 目录下创建一个数据采集方案,该方案就是从一个网络端口
收集数据,也就是创一个任意命名的配置文件如下:netcat-logger.properties
文件内容如下:
# 定义这个 agent 中各个组件的名字
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 描述和配置 source 组件:r1
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# 描述和配置 sink 组件:k1
a1.sinks.k1.type = logger
# 描述和配置 channel 组件,此处使用是内存缓存的方式
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 描述和配置 source channel sink 之间的连接关系
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
2、启动 agent 去采集数据:
在$FLUME_HOME 下执行如下命令:
bin/flume-ng agent -c conf -f agentconf/netcat-logger.properties -n a1 -Dflume.root.logger=INFO,console
-c conf 指定 flume 自身的配置文件所在目录
-f conf/netcat-logger.perproties 指定我们所描述的采集方案
-n a1 指定我们这个 agent 的名字
3、测试
先要往 agent 的 source 所监听的端口上发送数据,让 agent 有数据可采
例如在本机节点,使用 telnet localhost 44444 命令就可以,如果这个命令的执行过程中发现抛出异常说:command not found ,那么请使用:sudo yum -y install telnet 这个命令进行 telnet 的安装
输入两行数据:
hello huangbo
1 2 3 4
4、Flume-Agent 接收的结果
