版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_32297447/article/details/80235713
前言:Hadoop整体开发业务流程
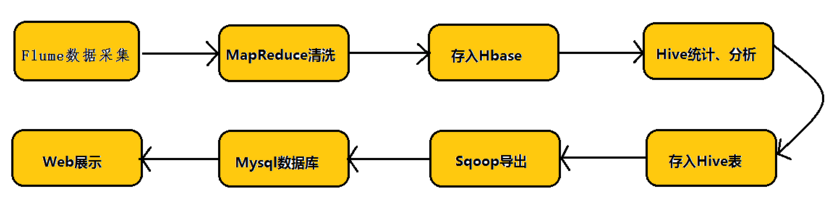
1、概述:
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力(
其设计的原理也是基于将数据流(如日志数据)从各种网站服务器上汇集起来,存储到HDFS、HBase等集中存储器中。它具有可靠的可靠性机制以及许多故障转移和恢复机制,具有强大的容错性和容错能力。它使用一个简单的可扩展数据模型,允许在线分析应用程序
)
Flume提供了从console(控制台)、RPC(Thrift-RPC)、text(文件)、tail(UNIX tail)、syslog(syslog日志系统,支持TCP和UDP等2种模式),exec(命令执行)等数据源上收集数据的能力。 Flume采用了多Master的方式。为了保证配置数据的一致性,Flume引入了
ZooKeeper
,用于保存配置数据,ZooKeeper本身可保证配置数据的一致性和高可用,另外,在配置数据发生变化时,ZooKeeper可以通知Flume Master节点。Flume Master间使用gossip协议同步数据。
2、数据流模型
Flume事件被定义为具有字节有效载荷和一组可选字符串属性的数据流单元。Flume代理是一个(JVM)进程,用于承载事件从外部源流向下一个目标(跳转)的组件。

Flume源消耗由外部源(如Web服务器)传递给它的事件。外部源以Flume源识别的格式向Flume发送事件。例如,Avro Flume源可用于接收来自Avro客户端或Avro接收器发送事件的流中的其他Flume代理的Avro事件。使用Thrift Flume Source可以定义类似的流程,以接收来自Thrift Sink或Flume Thrift Rpc客户端的事件或使用Flume thrift协议生成的任何语言编写的Thrift客户端。当Flume源接收事件时,它将其存储到一个或多个频道。该频道是一个被动商店,可以保持该事件直到它被Flume水槽消耗。文件通道就是一个例子 - 它由本地文件系统支持。接收器从通道中删除事件并将其放入HDFS等外部存储库(通过Flume HDFS接收器)或将其转发到流中下一个Flume代理(下一个跃点)的Flume源。给定代理中的源代码和接收器与通道中的事件异步运行。
2.1、每个Flume Agent有三个组件:Source、Channel、Sink
Source 专门用来收集数据,可以处理各种类型、各种格式的日志数据,比如avro、exec、HTTP、Kafka、Spooling Directory等
Channel 是一个存储Source已经接收到的数据的缓冲区,简单来说就是对Source采集到数据进行缓存,可以缓存在memory、file、jdbc、Kafka等。
Sink 用于把数据发送到目的地,目的地可以是:HDFS、Hive、HBase、ES、Kafka、Logger等
2.2、Flume 运行机制
flume的核心就是一个agent,这个agent对外有两个进行交互的地方,一个是接受数据的输入——source,一个是数据的输出sink,sink负责将数据发送到外部指定的目的地。source接收到数据之后,将数据发送给channel,chanel作为一个数据缓冲区会临时存放这些数据,随后sink会将channel中的数据发送到指定的地方—-例如HDFS等,注意:只有在sink将channel中的数据成功发送出去之后,channel才会将临时数据进行删除,这种机制保证了数据传输的可靠性与安全性
2.3、复杂流程
Flume允许用户构建多跳流,其中事件在到达最终目的地之前通过多个代理传播。它还允许扇入和扇出流,上下文路由和备份路由(故障转移),用于失败跳。
3、设计目标
3.1、可靠性
当节点出现故障时,日志能够被传送到其他节点上而不会丢失。Flume提供了三种级别的可靠性保障,从强到弱以此分别为:end-to-end(收集数据agent首先将event写到磁盘上,当数据传送成功后,再删除;如果数据发送失败,可以重新发送)、Store on failure(这也是scribe采用的策略,当数据接受方crash时,将数据写到本地,待恢复后,继续发送)、best effort(数据发送到接收方后,不会进行确认)。
3.2、可扩展性
Flume采用了三层架构,分别为agent、collector和storage,每一层均可以水平扩展。其中,所有agent和collector由master统一管理,这使得系统容易监控和维护,且master允许有多个(使用zookeeper进行管理和负载均衡),这就避免了单点故障问题。
3.3、可管理性
所有agent和collector由master统一管理,这使得系统便于维护。多master情况,flume利用zookeeper和gossip,保证动态配置数据的一致性。用户可以在master上查看各个数据源或者数据流执行情况,且可以对各个数据源配置和动态加载。Flume提供了web和shell script command两种形式对数据流进行管理。
3.4、功能可扩展性
用户可以根据需要添加自己的agent、collector或者storage。此外,flume自带了很多组件,包括各种agent(file、syslog等),collector和storage(file、HDFS等)
4、应用场景
比如我们再做一个电子商务网站,我们想根据消费用户中访问点特定的节点区域来分析消费者的行为或者购买意图。这样就可以更加快速地将他想要的商品推送到界面上,为了实现这一点,我们需要手机到客户访问的页面以及单击的产品数据等日志数据信息,并移交给Hadoop平台上去分析,而Flume可以帮我们做到这一点。现在流行的内容推送,比如广告定点投放以及新闻私人订制也是基于此,不过不一定Flume。优秀的产品还有很多,比如Facebook的Scribe、Apache的Chukwa,还有淘宝的Time Tunnel
4.1、功能亮点:
添加拦截器从事件中删除标题
提供netcat UDP源代替TCP
支持配置文件中的环境变量
4.2、Flume优势
1、Flume可以将应用产生的数据存储到任何集中存储器中,比如Hadoop、HBase
2、当手机数据的速度超过将写入数据速度的时候,也就是当收集信息遇到峰值时,收集的信息非常大,甚至超过了系统的写入数据能力,这时候Flume会在数据生产者和数据收集容器间做出调整,保证其能够在两者之间提供一种平稳的数据
3、提供上下文路由特征
4、Flume的管道是基于事物,保证了数据在传送和接收时的一致性
5、Flume是可靠的、容错性高的、可升级的、易管理的、并且是可定制的
4.3、Flume特征
Flume可以高效地将多个网站服务器中收集的日志信息存入HDFS、HBase中
使用Flume,我们可以将从多个服务器中获取的数据迅速地移交给Hadoop处理
除了日志信息,Flume同时也可以用来接入收集规模宏大的社交网络节点事件数据(比如Facebook、Twitter)、电商网站(亚马逊、Flipkart)等
支持各种接入资源数据的类型以及接出数据类型
支持多路径流量、多管道接入流量、多管道接出流量,上下文路由等
可以被水平扩展
5、Flume架构
5.1、Flume逻辑架构

上面提到,flume采用了分层架构,分别为:agent、collector和storage。其中,agent和collector均由两部分组成:source和sink,source是数据来源,sink是数据去向。
Flume使用两个组件:master和node。Node根据在master shell或者web中动态配置,决定其作为agent还是collector。
5.2、Agent详解
Agent的作用是将数据源的数据发送给collector。
1、
Flume自带了很多直接可用的数据源(source),例如:
- Text(“filename”):将文件filename作为数据源,按行发送
- tail(“filename”):将探测filename新产生的数据,按行发送出去
- fsyslogTcp(5140):监听TCP的5140端口,并且接受到的数据发送出去
- tailDir(“dirname[,fileregex=”.*”[,startFromEnd=false[,recurseDepth=0]]]):监听目录中的文件末尾,使用这则去选定需要监听的文件(不包括目录),recurseDepth为递归监听其子目录的深度。
2、 同时提供了很多sink,如:
- console(“format”):直接将数据显示在console上
- text(“txtfile”):将数据写到文件txtfile中
- dfs(“dfsfile”):将数据写到HDFS上的dfsfile文件中
- syslogTcp(“host”,prot):将数据通过tcp传递给host节点
- agentSink[(“machine”[,port])]:等价于agentE2ESink,如果省略machine参数,默认使用flume.collector.event.host;如果省略port参数,默认使用flume.collector.event.port。
- agentDFOSink[("machine" [,port])]:本地热备agent,agent发现collector节点故障后,不断检查collector的存活状态以便重新发送event,在此间产生的数据将缓存到本地磁盘中
- agentBESink[("machine"[,port])]:不负责的agent,如果collector故障,将不做任何处理,它发送的数据也将被直接丢弃
- agentE2EChain:指定多个collector提高可用性。当向主collector发送event失效后,转向第二个collector发送,当所有的collector失败后,它会非常执着的再来一遍
5.3、Collector详解
Collector的作用是将多个agent的数据汇总后,添加到storage中,它的source和sink与agent类似。
1)数据源(source)如:
- collectorSource[(port)]:Collector source,监听端口汇聚数据
- autoCollectorSource:通过master协调物理节点自动汇聚数据
- logicalSource:逻辑source,由master分配端口并监听rpcSink
2)Sink如:
- collectorSink( "fsdir","fsfileprefix",rollmillis):collectorSink,数据通过collector汇聚之后发送到hdfs, fsdir 是hdfs目录,fsfileprefix为文件前缀码
- customdfs(“hdfspath”[,”format”]):自定义格式dfs
注:上面三个是Flume的主要组件,下面介绍两个次要组件。1、拦截器:用于Source和Channel之间,用来更改或者检查Flume的events数据。2、管道选择器:再多管道时被用来选择使用哪一条管道来传递数据(events),管道选择器又分为默认管道选择器(每一个管道传递的都是相同的events)和多路复用通道选择器(依据每一个event的头部header的地址选择管道)
5.4、Storage详解
Storage是存储系统,可以是一个普通file,也可以是hdfs、hive、hbase等分布式存储。
5.5、Master详解
Master是管理协调agent和collector的配置等信息,是flume集群的控制器。
6、flume数据流
在flume中,最重要的抽象是data flow(数据流),data flow描述了数据从产生、传输、处理并最终写入目标的一条路径。
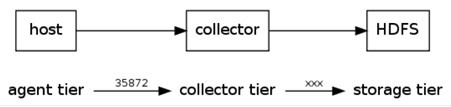
1、对于agent数据流配置就是从那里得到数据,并把数据发送到那个collector。
2、对于collector是接收agent发送过来的数据,并把数据发送到指定的目标机器上。
注:flume框架对hadoop和zookeeper的依赖只是在jar包上,并不要求flume启动时必须将hadoop和zookeeper服务也启动。
7.Flume 部署
目前Flume 的最新版本为1.8,笔者安装的是1.6,是Flume的一个经典版本,通常在生产环境中使用的就是这个版本,在安装Flume前,看先它的前置条件
(1).JDK1.7
(2).足够的内存
(3).足够的磁盘空间
(4).目录及文件要有读写权限
下载解压

配置flume
进入flume的conf目录下,拷贝flume-env.sh.template然后重命名为flume-env.sh
$ cp flume-env.sh.template flume-env.sh
$ chmod 777 flume-env.sh
$ vi flume-env.sh
进入flume-env.sh中配置java jdk路径
export JAVA_HOME=/home/hadoop/app/jdk
配置环境变量
# Flumeexport FLUME_HOME=/home/hadoop/app/flumeexport PATH=$PATH:$FLUME_HOME/bin
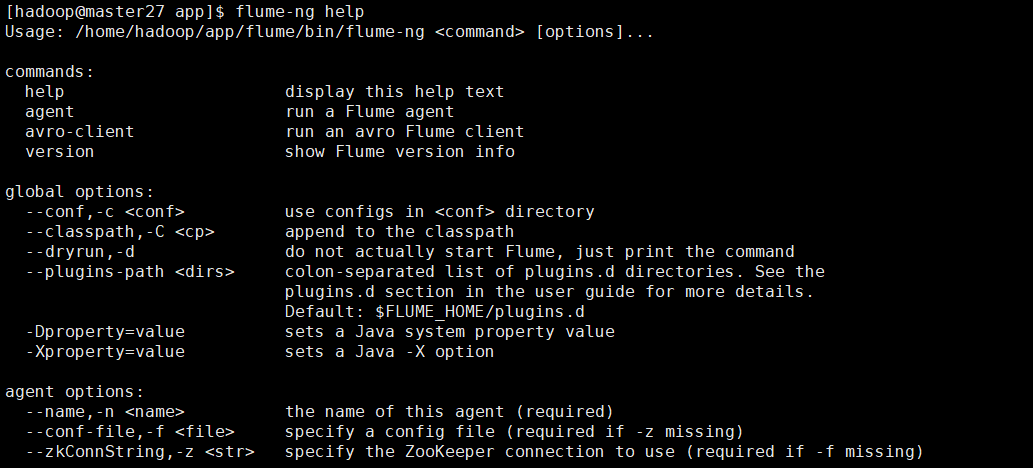
查看Flume 的命令帮助
[hadoop@master27 app]$ flume-ng help
查看Flume 版本信息
[hadoop@master27 app]$ flume-ng version

Flume 简单使用
需求:从网络端口接受数据,输出到控制台
Agent选型:netcat+source + memory channel + logger sink
Flume中最重要的就是Agent配置文件的编写,如何编写,官网都有说明,下面是官网提供的一个Agent配置文件模板
# example.conf: A single-node Flume configuration
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
参照上述官网的配置,新建simple-example.conf文件,配置如下
# Name the components on this agent
simple-agent.sources = netcat-source
simple-agent.sinks = logger-sink
simple-agent.channels = memory-channel
# Describe/configure the source
simple-agent.sources.netcat-source.type = netcat
simple-agent.sources.netcat-source.bind = Master
simple-agent.sources.netcat-source.port = 44444
# Describe the sink
simple-agent.sinks.logger-sink.type = logger
# Use a channel which buffers events in memory
simple-agent.channels.memory-channel.type = memory
# Bind the source and sink to the channel
simple-agent.sources.netcat-source.channels = memory-channel
simple-agent.sinks.logger-sink.channel = memory-channel
配置完成后,输入如下命令来启动flume
flume-ng agent \
--conf $FLUME_HOME/conf \
--name simple-agent \
--conf-file $FLUME_HOME/config/simple-example.conf \
-Dflume.root.logger=INFO,console
参数说明:
–conf:指定flume的配置文件所在目录
–name:指定Agent的名称
–conf-file:指定编写的flume配置文件
-Dflume.root.logger:指定日志级别
flume启动后,打印的日志中可以看到如下信息(部分日志)
Creating instance of source netcat-source, type netcat
Creating instance of sink: logger-sink, type: logger
Creating instance of channel memory-channel type memory
Created serverSocket:sun.nio.ch.ServerSocketChannelImpl[/192.168.242.150:44444]
输入jps命令可以查看到一个Application的进程,如果有这个进程,说明我们的flume启动成功了
[hadoop@Master ~]$ jps3091 Jps2806 Application
测试(启动一个telnet进程,telnet 数据输入)
$ telnet Master 44444
查看Flume控制台的输出(Event是Flume数据传输的基本单元,由可选的header和一个byte array的数据构成)
Event: { headers:{} body: 68 65 6C 6C 6F 0D hello. }
Event: { headers:{} body: 66 6C 75 6D 65 0D flume. }