简介
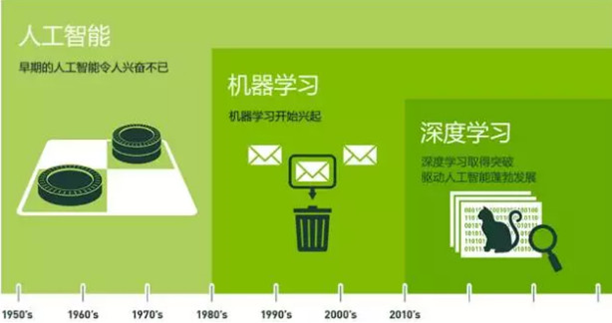
深度学习是机器学习研究中的一个新的领域,其动机在于建立、模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,例如图像,声音和文本。
算法导论和机器学习的异同
相同点:都是输入,计算,得到结果。
差异:
算法导论:
以f(x)=w*x为例,其实就是人为的设定w的过程。但x是离散变量不是连续变量,不然就是高中数学题了。

机器学习:
以f(x)=w*x为例,是通过一个训练集(x,y),优化w的过程。

神经网络
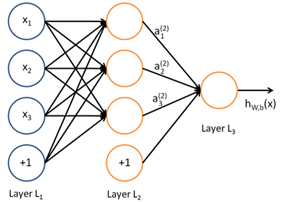
神经网络是机器学习的一种,就是将许多个单一“神经元”联结在一起,这样,一个“神经元”的输出就可以是另一个“神经元”的输入。
一般超过8层的神经网络模型就叫深度学习。
深度学习解决了浅层神经网络多层传递之后梯度消失和局部最优解的问题。
主要的两类深度学习
监督学习:
回归和分类,回归问题通常是用来预测一个值,如预测房价、未来的天气情况等等。分类问题是用于将事物打上一个标签,通常结果为离散值。例如判断一幅图片上的动物是一只猫还是一只狗。

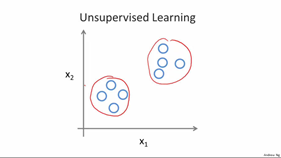
无监督学习:
无监督学习里典型的例子就是聚类了。聚类的目的在于把相似的东西聚在一起,而我们并不关心这一类是什么。
神经网络基础
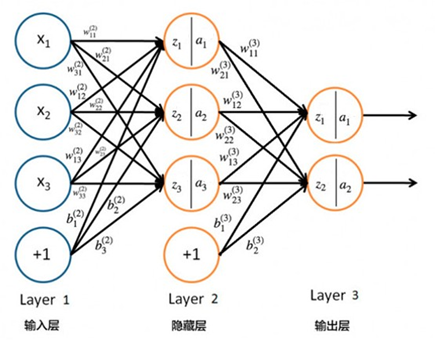
注:第二层、第三层的z和a不是同一个值。
输入:整个训练集表示为![]() ,n代表第几个样本,i代表某一样本中某个参数。下面为举例说明一个样本简写为
,n代表第几个样本,i代表某一样本中某个参数。下面为举例说明一个样本简写为![]() 。
。
输出:![]()
权重: ![]() ,随机初始化,神经网络其实就是计算最佳的权重。
,随机初始化,神经网络其实就是计算最佳的权重。
偏置:![]()
计算过程:比如第二层![]()
激活函数:比如激活函数为sigmoid时,第二层![]() 。
。
以上是正向传播的内容。得到模型后只需计算到该步。
反向传播:梯度下降法更新权重w。其中α为步长。
损失函数(Loss Function):是定义在单个样本上的,算的是一个样本的误差。
以均方误差损失函数为例,![]()
代价函数(Cost Function):是定义在整个训练集上的,是所有样本误差的平均,也就是损失函数的平均。

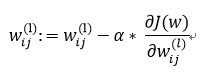
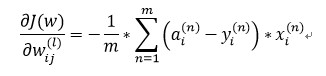
附,矩阵操作
所有的计算过程如果都是![]() 这种形式,计算就会显得很复杂。
这种形式,计算就会显得很复杂。
所以神经网络中广泛的使用了矩阵操作。
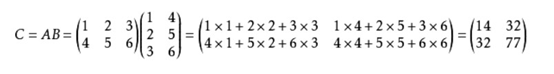
所以上述一次计算可以变成(与线代计算过程不同,tensorflow具有广播机制):

Tensorflow
安装
python环境Anaconda集成安装
ide Pycharm等
配置清华源
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --set show_channel_urls yes
创建一个python环境
conda create -n tensorflow python=版本号
activate tensorflow(退出deactivate tensorflow)
pip清华源安装tensorflow
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple tensorflow
或者全局设置pip源。C:\Users\用户名\pip\pip.ini,默认情况下pip文件夹和pip.ini都未创建,自行创建,pip中添加以下内容。
[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
使用pip install tensorflow
案例
tensorflow mnist
from tensorflow.examples.tutorials.mnist import input_data
import tensorflow as tf
# MNIST数据存放的路径
file = "./MNIST"
# 导入数据
mnist = input_data.read_data_sets(file, one_hot=True)
# 模型的输入和输出
x = tf.placeholder(tf.float32, shape=[None, 784])
y_ = tf.placeholder(tf.float32, shape=[None, 10])
# 模型的权重和偏移量
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
# 创建Session
sess = tf.InteractiveSession()
# 初始化权重变量
sess.run(tf.global_variables_initializer())
# SoftMax激活函数
y = tf.nn.softmax(tf.matmul(x, W) + b)
# 交叉熵损失函数
cross_entropy = -tf.reduce_sum(y_*tf.log(y))
# 梯度下降法训练
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)
for i in range(1000):
batch = mnist.train.next_batch(50)
train_step.run(feed_dict={x: batch[0], y_: batch[1]})
# 测试
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_:mnist.test.labels}))
参考链接:
吴恩达给你的人工智能第一课
http://mooc.study.163.com/smartSpec/detail/1001319001.htm
机器学习的算法和普通《算法导论》里的算法有什么本质上的异同?
https://www.zhihu.com/question/24976006
人工智能、机器学习和深度学习的区别?
https://www.zhihu.com/question/57770020
如何简单形象又有趣地讲解神经网络是什么?
https://www.zhihu.com/question/22553761
深入浅出--梯度下降法及其实现
https://www.jianshu.com/p/c7e642877b0e
深入梯度下降(Gradient Descent)算法
https://www.cnblogs.com/ooon/p/4947688.html
梯度下降(Gradient Descent)小结(写了梯度下降和梯度上升)
https://www.cnblogs.com/pinard/p/5970503.html
一文弄懂神经网络中的反向传播法——BackPropagation
https://www.cnblogs.com/charlotte77/p/5629865.html
基于字符的卷积神经网络实现文本分类(char-level CNN)-论文详解及tensorflow实现
https://blog.csdn.net/irving_zhang/article/details/75634108
数据挖掘系列(10)——卷积神经网络算法的一个实现