通俗易懂而不失深度 HashMap解读
什么是HashMap
HashMap在代码的定义如下,从代码可以看出 HashMap的结构是一个数组。
Node<K,V>[] table;
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
//省略实现
}
其结构如下图所示: haspMap的结构由数组、链表、红黑树组成。
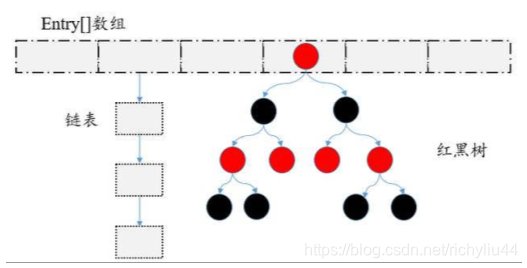
什么选择这样的结构呢?
我们先整理下每一种构的特点。
数组:采用一段连续的存储单元来存储数据。对于指定下标的查找,时间复杂度为O(1);通过给定值进行查找,需要遍历数组,逐一比对给定关键字和数组元素,时间复杂度为O(n),当然,对于有序数组,则可采用二分查找,插值查找,斐波那契查找等方式,可将查找复杂度提高为O(logn);对于一般的插入删除操作,涉及到数组元素的移动,其平均复杂度也为O(n)
线性链表:对于链表的新增,删除等操作(在找到指定操作位置后),仅需处理结点间的引用即可,时间复杂度为O(1),而查找操作需要遍历链表逐一进行比对,复杂度为O(n)
二叉树:对一棵相对平衡的有序二叉树,对其进行插入,查找,删除等操作,平均复杂度均为O(logn)。
可以得出结论,数组(使用下标时)效率是最高的。使用数组我们需要解决以下问题?
1: key-value 中的key不是数组的下标,我们需要把key转成下标,例如,0,1,2,3,4。
方案:把Key进行Hash转换获取数字 并取 & (n-1),满足取出来的值 小于数组的长度。
2: key转成hash,那就必须会遇到hash冲突的问题。
方案:数据的Value存的是链表,把hash值一样的数据插入到链表的未端。
3: 生成的下标需要小于数组的长度,并组分散。
方案:数组的长度(n)设置为2的幂,(n-1)取 与(&)计算,可以获得小于数组长度,并组分散在0~n中。
4: 链表长度过长,查询性能差
方案:链表长度过长时,把结构转成换红黑树。
5: 数据过多时,而数组的长度不够,造成的Hash冲突严重,影响性能。
方案:数组扩容,减少hash冲突。
原代码分析
阈值
主要是HashMap的默认值设置,详细情况见注释。
/**
* 默认的初始化变量(16)-必须是2的幂(次方)
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
/**
* 最大容量(必须是2的幂且 <= 2的30次方)
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* 默认的装载因子(填充比例):0.75,即实际元素所占所分配的容量的75%时就要扩容啦。
* 如果该值过大,再增加元素将导致链表过长,查找效率降低;反之,浪费空间
* 关注内存:适当增大填充比;
* 关注查找性能: 适当减小填充比;
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* 每个桶的可树化的阀值,即当桶中元素个数超过该值时,自动将链表转化为红黑树结构
*/
static final int TREEIFY_THRESHOLD = 8;
/**
* 每个桶的去树化阀值,即在扩容(resize())时,发现桶中的元素少于该值,则将树形结构还原为链表结构
*/
static final int UNTREEIFY_THRESHOLD = 6;
/**
* 哈希表中可被树形化的最小数量。
* 即若哈希表中的元素个数少于该值,则桶(bin)不会被树形化,而是会进行扩容(就算桶中的元素个数超过TREEIFY_THRESHOLD)。
* 主要是为了避免扩容&可树化的选择冲突
*/
static final int MIN_TREEIFY_CAPACITY = 64;
插入
代码如下,关键的地方增加了注释。
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 桶数组的初始化工作;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 如果 table在(n-1)&hash 的值如果为null,则新建一个节点插入到该位置;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
// 这里表示出现哈希冲突,下标一样。处理冲突的操作
else {
Node<K,V> e;
K k;
// 1. 首先判断链表的第一个元素,是不是要替换的值;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 2. 判断 第一个节点的类型是链表or红黑树,对应进行相应的处理。处理节点是红黑树的情况。
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
// 3. 处理节点类型是链表的情况;
else {
for (int binCount = 0; ; ++binCount) {
// 链表中不存在该节点,则直接插入到链表的尾部
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// 判断是否需要树形化
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
// 链表中已经存在该节点,直接退出循环
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
// 若节点已经存在,新值覆盖旧值,同时返回旧值;
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
// 判断是否需要resize()。
if (++size > threshold)
resize();
// 这行代码是为了LinkedHashMap使用的。
afterNodeInsertion(evict);
return null;
}
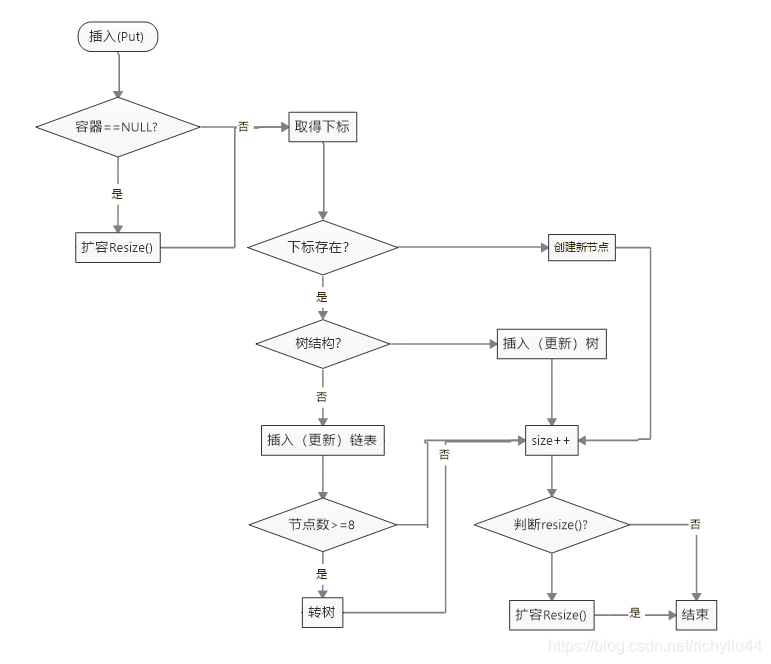
插入是HashMap比较难懂的,逻辑比较复杂,是面试的重灾区。插入的逻辑如下图所示。
1、先判容器是否为空,是执行Resize()。
2、 取得key的下标。
1)下标不存在则创建新节点。
2) 下标存在,则判断节点结构
1)) 树结构:增加树结点
2)) 链表结构:如果链表结点>8,则把链表结构转成树,增加链表节点。
3、size++
4、size >= 阈值时 Resize().
删除
源代码如下
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
/*根据下标,key值 找到对应的节点 */
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
//如果 hash code一致 并且 值一致
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
// p有下个节点
else if ((e = p.next) != null) {
//树结构时 获取到对应的树结点
if (p instanceof TreeNode)
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
//获取链表结点
else {
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
/*节点删除,根据链表或者树结构,进行结点删除,其中是树结构时可能触发树转链表*/
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
//树结点删除 ,removeTreeNode 删除动可能触发树转链表的动作
if (node instanceof TreeNode)
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
else if (node == p)
tab[index] = node.next;
else
//链表删除
p.next = node.next;
++modCount;
--size;
afterNodeRemoval(node);
return node;
}
}
return null;
}
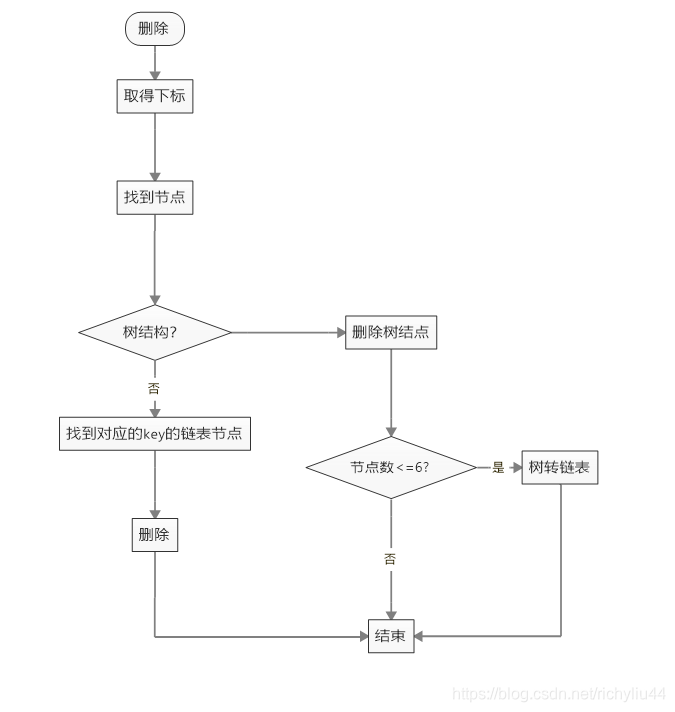
删除动作流程如下图所示:
1、取得下标
2、找到数组节点。
3、判断节点的结构类型:
1)链表:遍历值,删除对应的链表节点。
2)树:删除对应的树节点。并判断树的节点数A。如A<=6,则把结构转换成链表。
查询
源代码如下:
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
//根据下标取得数组节点
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // 第一个节点就是要找的值
((k = first.key) == key || (key != null && key.equals(k))))
return first;
//第一个不是要找到值,根据不同结构进行查找,返回节点
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
//没找到值,返回null
return null;
}
1、根据下标取得数组节点。
2、第一节点的值==key,直接返回第一个节点。
3、第一节点值 !=key。 根据不同结构进行查找,返回节点
4、如查找不到,直接返回null。
关键
下标的算法
怎么样的算法,才能符合数组的要求呢?
第一:必须是数字。
第二:必须<数组的长度-1;
第三:key分散。
下面,我把源代码抽出来,如下:
int i=(n-1) & hash ; //n是数组的长度
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
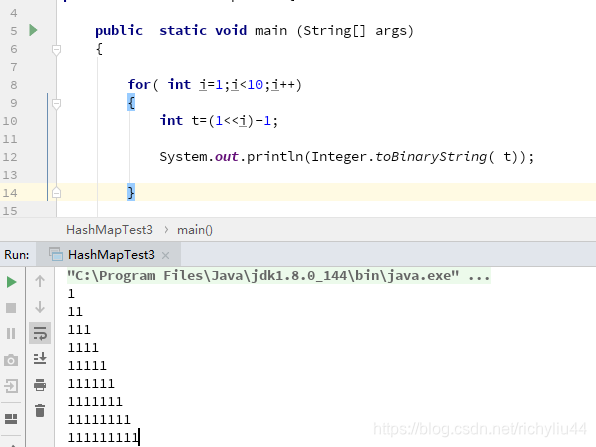
我们先来做个实验,用这个算法,输出1~200的值 对应的下标。代码如下:
public class HashMapTest {
public static void main (String[] args)
{
int n=128; //数组的容量,必须是2的幂 1<<7
for(int i=0;i<=200;i++)
{
System.out.print(((n-1) & hash(i))+",");
}
}
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
}
结果如下:
0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79,80,81,82,83,84,85,86,87,88,89,90,91,92,93,94,95,96,97,98,99,100,101,102,103,104,105,106,107,108,109,110,111,112,113,114,115,116,117,118,119,120,121,122,123,124,125,126,127,0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,
从结果来看是符合我们的要求的。下标算法是大厂面试的重点,接下来,我们再深入了解。 下标取得的流程如下:
1:为什么要取 i=(n-1) & hash 。
解: hashMap的数组长度(n)一定保持2的次幂,那么n-1 的二进度数所有的位数必然是1,如下图所示。
那么(n-1)& hash(i) 取出来的下标必然是小于数组个数,并且能覆盖到整个数组的下标。
下面引用了一个网友的解释:
数组长度保持2的次幂,length-1的低位都为1,会使得获得的数组索引index更加均匀,比如:
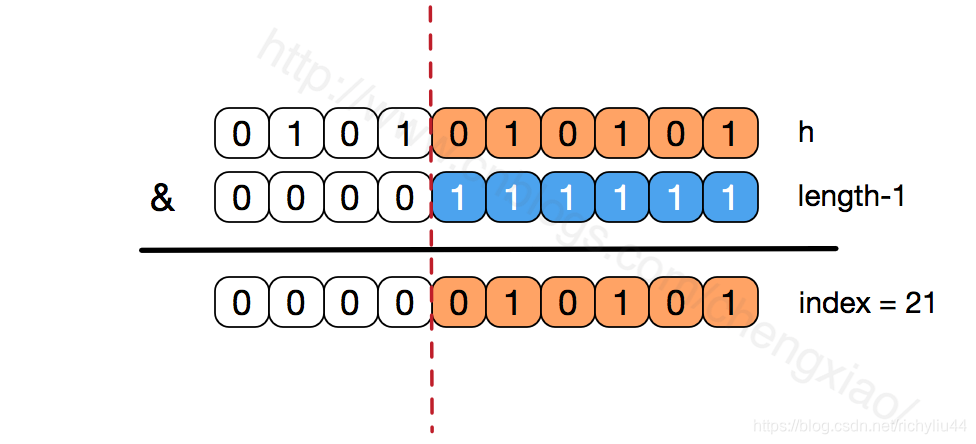
我们看到,上面的&运算,高位是不会对结果产生影响的(hash函数采用各种位运算可能也是为了使得低位更加散列),我们只关注低位bit,如果低位全部为1,那么对于h低位部分来说,任何一位的变化都会对结果产生影响,也就是说,要得到index=21这个存储位置,h的低位只有这一种组合。这也是数组长度设计为必须为2的次幂的原因。
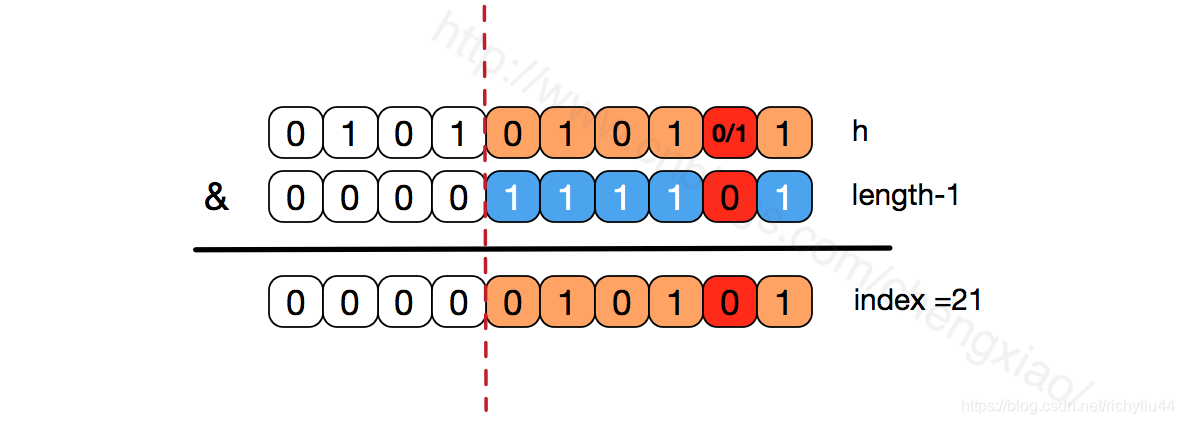
如果不是2的次幂,也就是低位不是全为1此时,要使得index=21,h的低位部分不再具有唯一性了,哈希冲突的几率会变的更大,同时,index对应的这个bit位无论如何不会等于1了,而对应的那些数组位置也就被白白浪费了。
写在最后
HashMap真的很有意思,小小的一个东西却充满了学问。感觉学它不应只是为了应对面试,它的的原理和思维方式可以用到其它很多场景。例如:多个结构并存、结构的升级与降级、下标的算法、扩容等等。
另外深入了解了,面试还考得倒你吗?
本人能力有限,出有错误,请指教。
参考:
https://www.cnblogs.com/chengxiao/p/6059914.html#t2
https://blog.csdn.net/wangcheeng/article/details/105294388
java 8 原代码
