follow 是一个布尔(boolean)值,指定了根据该规则从response提取的链接是否需要跟进。 如果callback 为None,follow 默认设置为 True ,添加回调函数callback后为 False,不跟踪
一句话解释:follow可以理解为回调自己的回调函数
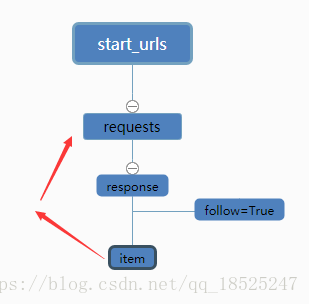
举个例子,如百度百科,从任意一个词条入手,抓取词条中的超链接来跳转,rule会对超链接发起requests请求,如follow为True,scrapy会在返回的response中验证是否还有符合规则的条目,继续跳转发起请求抓取,周而复始,如下图
代码实现:
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders.crawl import Rule, CrawlSpider
class BaiDuSpider(CrawlSpider):
name = "baidu_spider"
start_urls = ['https://baike.baidu.com/item/Python/407313?fr=aladdin']
'''获取url'''
rules = (
Rule(LinkExtractor(restrict_xpaths='//*[@class="para"]//a')),
)
print(rules)ps: 爬取百度百科时需要在setting中设置不遵守robots规则: ROBOTSTXT_OBEY = False