HTML、DOM树以及XPath
从用户在浏览器输入URL到屏幕显示的过程。
- 在浏览器输入URL。URL的第一部分用于在网络上找到合适的服务器,而URL以及cookie等其他数据则构成一个请求,用于发送到那台服务器中。
- 服务器回应,向浏览器发送一个HTML页面。也可能返回其他格式,比如XML和JSON。
- 将HTML转换成浏览器内部的树状表示形式:文档对象模型。
- 基于一些布局规则渲染内部表示,达到你所在屏幕上的视觉效果。
URL
URL分为两个主要部分。第一个部分通过域名系统(DNS)帮助我们在网络上定位合适的服务器。URL的剩余部分对于服务器理解请求是什么。它可能是一张图片、一个文档,或是需要出发某个动作的东西。
HTML文档
服务端读取URL,理解我们的请求是什么,然后返回一个HTML文档。该文档实质上就是一个文本文件,我们可以使用TextMate、Notepad、vi或Emacs打开它。
树表示法
每个浏览器都有自身复杂的内部结构,凭借它来渲染网页。DOM表示法具有跨平台、语言无关性等特点,并且被大所属浏览器所支持。想要在Chrome中查看网页的树表示法,可以右键单击你感兴趣的元素,然后点击Inspect Element,需要注意的是,HTML只是文本,而树表示法是浏览器内存里的对象,可以通过编程的方式查看并操作它。
使用XPath选择HTML元素
通过一种称为XPath的语言选择并抽取元素、属性和文本。这种语言专门为此设计。
例子文本
<html>
<head>
<meta charset="utf-8" />
<title class='title'>网页标题</title>
</head>
<body>
<h1 id='my_h1'>标题1</h1>
<p class='my_p'>段落1</p>
<p class='my_p'>段落2</p>
<span>25.00</span>
<span>255.00</span>
<div>
<span>25.00</span>
<p>qwer</p>
</div>
<div>
<span>225.00</span>
<p>qwer</p>
</div>
</body>
</html>语法
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点 |
| / | 从根结点选取 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置 |
| . | 选取当前节点 |
| .. | 选取当前节点的父节点 |
| @ | 选取属性 |
| 路径表达式 | 描述 |
|---|---|
| html | 选取html元素的所有子节点 |
| /html | 选取根元素html,如果路径起始于斜杠(/),则此路径始终代表到某元素的绝对路径 |
| html/body | 选取属于html的子元素的所有body元素 |
| //body | 选取所有body子元素,而不管它们在文当中的位置 |
| //@class | 选取名为class的所有属性 |
| 路径表达式 | 描述 |
|---|---|
| //body/p[1] | 选取属于body子元素的第一个p元素 |
| //body/p[last()] | 选取属于body子元素的最后一个p元素 |
| //body/p[last()-1] | 选取属于 body子元素的倒数第二个p元素 |
| //body/p[position()<3] | 选取属于body子元素的前两个p元素 |
| //title[@class’] | 选取所有拥有名为class的属性的title元素 |
| //title[@class=’title’] | 选取所有title元素,且这些元素拥有值为tilte的class |
| /html/body[span>35.00] | 选取html元素的所有body元素,且其中的span元素的值须大于35.00 |
| /html/body[span>35.00]/p | 选取 html 元素中的 body元素的所有 p元素,且其中的 span 元素的值须大于 35.00 |
| //h1[@id=”my_h1”]/text() | 选择id为my_h1的h1标签下的text |
| 通配符 | 描述 |
|---|---|
| * | 匹配任何元素节点 |
| @* | 匹配任何属性节点 |
| node() | 匹配任何类型的节点 |
通过在路径表达式中使用‘|’运算符,可以选取若干个路经
浏览器中
为了在浏览器中使用XPath,需要单击Developer Tools的Console标签,并使用$x()工具函数。


使用scrapy在命令行选择
scrapy shell http://example1.com
>>> response.xpath('/html/head/title').extract()
[u'<title>Example 1</title>']
>>> response.xpath('//a/text()').extract()
[u'Burke', u'RGB to Hex', u'Portia Doubleday', u'Example1']
>>> 或取XPath表达式
我使用的火狐浏览器,安装四个插件Firebug、FirePath、User Agent Switcher、xpath finder。
右上角菜单——>Adds-ons(附件)——>Get Adds-ons
下载你想添加的插件。
重启浏览器
单击右键选择Firebug,选择元素,查看FirePath。
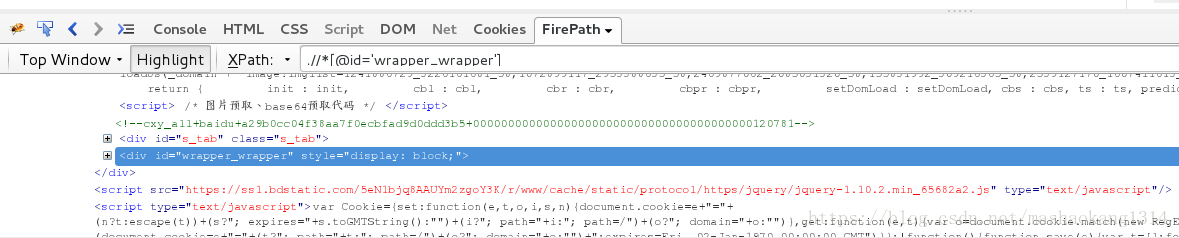
预见变化
如果HTML发生变化后,就会使XPath表达式失效。一些简单规则可以帮助我们减少表达式失效的可能性。
- 避免使用数组索引,因为这些数字最终将会孩子像不同的元素。
- 类并不好用,这些属性一般用通过CSS影响页面外观,因此可能会由于网站布局的微小变更而产生变化。
- 有意义的面向数据的类要比具体或者面向布局的类更好。因为在布局发生变化时,后者更可能保持有效。
- ID通常是最可靠的。